 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Temporal Variability in Functional Magnetic Resonance Imaging Improves Prediction of Intelligence
Nov 11, 2022Neuroimaging-based prediction methods for intelligence and cognitive abilities have seen a rapid development, while prediction based on functional connectivity (FC) has shown great promise. The overwhelming majority of literature has focused on static FC with extremely limited results available on dynamic FC or region level fMRI time series. Unlike static FC, the latter features include the temporal variability in the fMRI data. In this project, we propose a novel bi-LSTM approach that incorporates an $L_0$ regularization for feature selection. The proposed pipeline is applied to prediction based on region level fMRI time series as well as dynamic FC and implemented via an efficient algorithm. We undertake a detailed comparison of prediction performance for different intelligence measures based on fMRI features acquired from the Adolescent Brain Cognitive Development (ABCD) study. Our analysis illustrates that static FC consistently has inferior performance compared to region level fMRI time series or dynamic FC for unimodal rest and task fMRI experiments, as well as in almost all cases for multi-task analysis. The proposed pipeline based on region level time-series identifies several important brain regions that drive fluctuations in intelligence measures. Strong test-retest reliability of the selected features is reported, pointing to reproducible findings. Given the large sample size from ABCD study, our results provide conclusive evidence that superior intelligence prediction can be achieved by considering temporal variations in the fMRI data, either at the region level, or based on dynamic FC, which is one of the first such findings in literature. These results are particularly noteworthy, given the low dimensionality of the region level time series, easier interpretability, and extremely quick computation times, compared to network-based analysis.
APSNet: Attention Based Point Cloud Sampling
Oct 11, 2022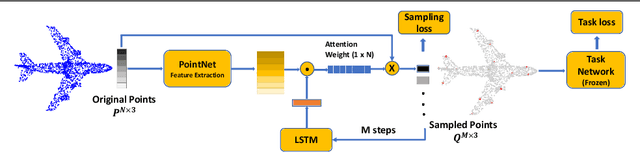
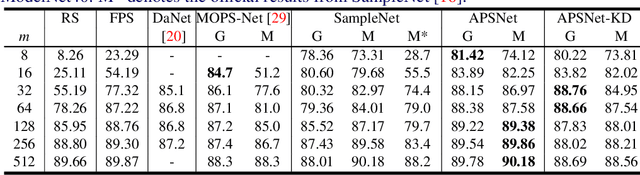
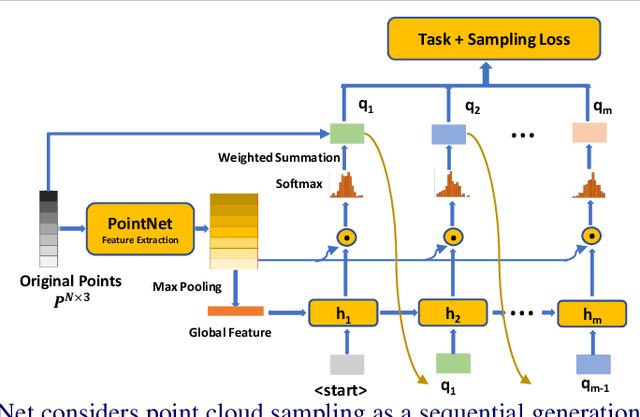
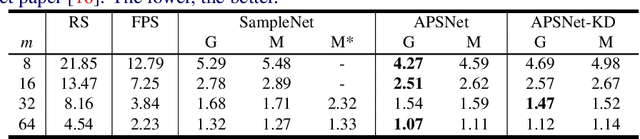
Processing large point clouds is a challenging task. Therefore, the data is often downsampled to a smaller size such that it can be stored, transmitted and processed more efficiently without incurring significant performance degradation. Traditional task-agnostic sampling methods, such as farthest point sampling (FPS), do not consider downstream tasks when sampling point clouds, and thus non-informative points to the tasks are often sampled. This paper explores a task-oriented sampling for 3D point clouds, and aims to sample a subset of points that are tailored specifically to a downstream task of interest. Similar to FPS, we assume that point to be sampled next should depend heavily on the points that have already been sampled. We thus formulate point cloud sampling as a sequential generation process, and develop an attention-based point cloud sampling network (APSNet) to tackle this problem. At each time step, APSNet attends to all the points in a cloud by utilizing the history of previously sampled points, and samples the most informative one. Both supervised learning and knowledge distillation-based self-supervised learning of APSNet are proposed. Moreover, joint training of APSNet over multiple sample sizes is investigated, leading to a single APSNet that can generate arbitrary length of samples with prominent performances. Extensive experiments demonstrate the superior performance of APSNet against state-of-the-arts in various downstream tasks, including 3D point cloud classification, reconstruction, and registration.
Towards Bridging the Performance Gaps of Joint Energy-based Models
Sep 16, 2022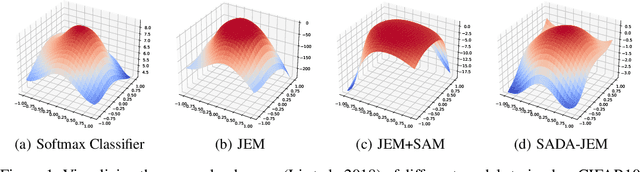

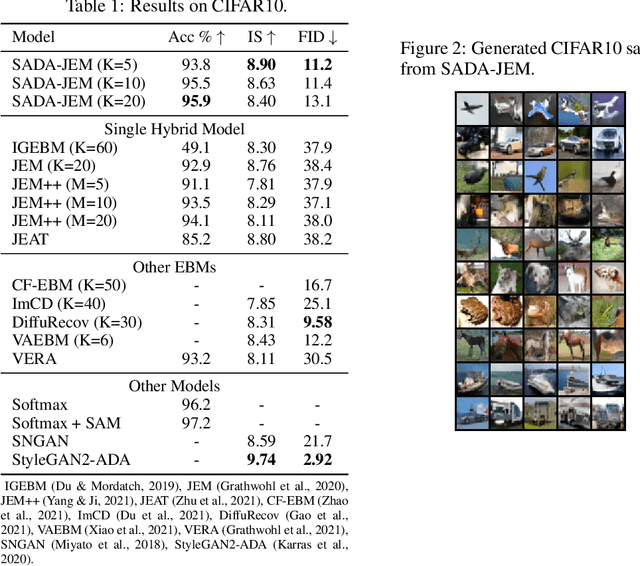
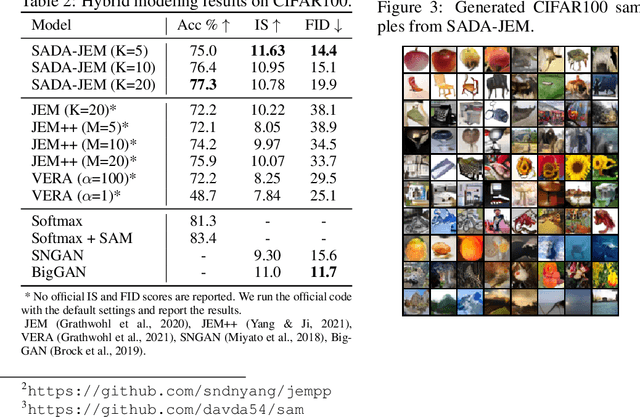
Can we train a hybrid discriminative-generative model within a single network? This question has recently been answered in the affirmative, introducing the field of Joint Energy-based Model (JEM), which achieves high classification accuracy and image generation quality simultaneously. Despite recent advances, there remain two performance gaps: the accuracy gap to the standard softmax classifier, and the generation quality gap to state-of-the-art generative models. In this paper, we introduce a variety of training techniques to bridge the accuracy gap and the generation quality gap of JEM. 1) We incorporate a recently proposed sharpness-aware minimization (SAM) framework to train JEM, which promotes the energy landscape smoothness and the generalizability of JEM. 2) We exclude data augmentation from the maximum likelihood estimate pipeline of JEM, and mitigate the negative impact of data augmentation to image generation quality. Extensive experiments on multiple datasets demonstrate that our SADA-JEM achieves state-of-the-art performances and outperforms JEM in image classification, image generation, calibration, out-of-distribution detection and adversarial robustness by a notable margin.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022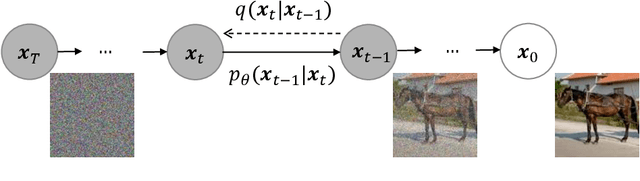
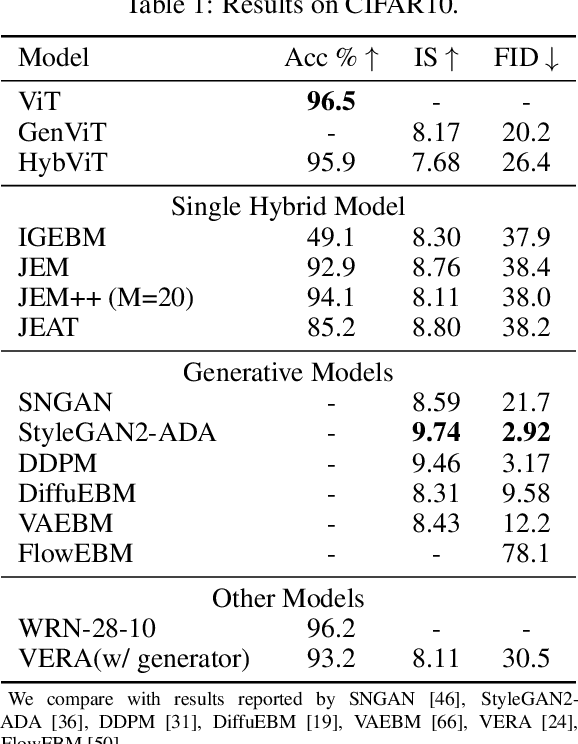
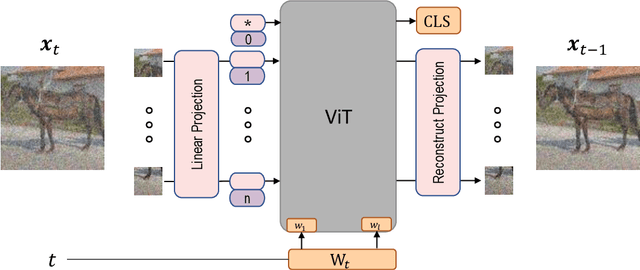
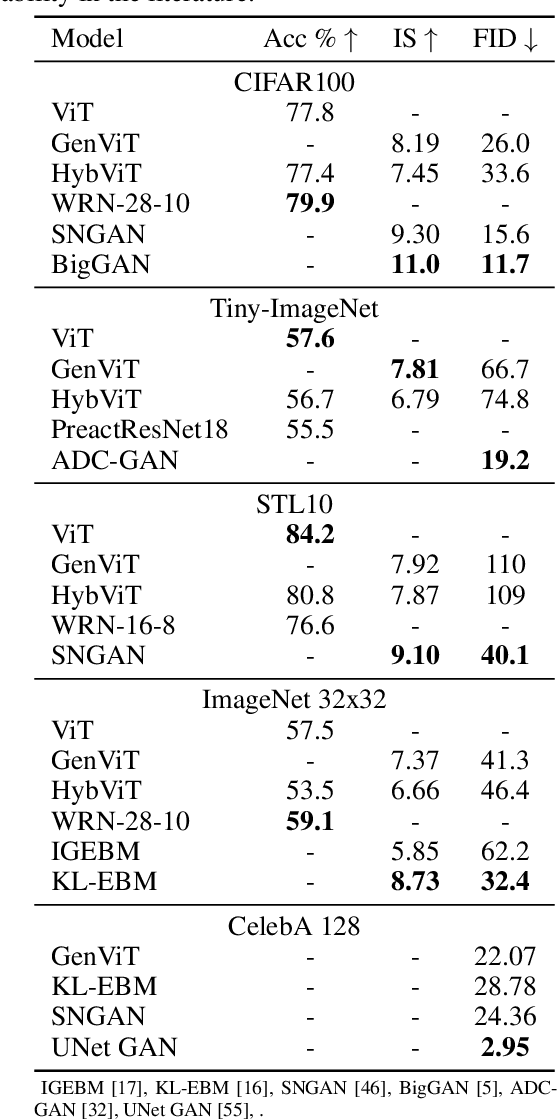
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
ChiTransformer:Towards Reliable Stereo from Cues
Mar 29, 2022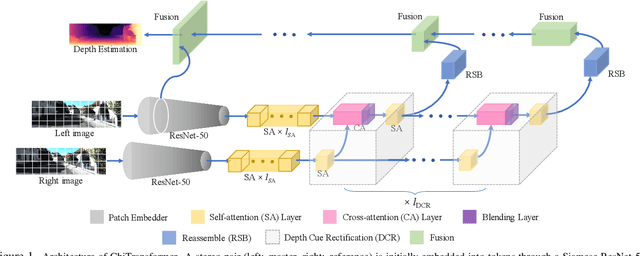
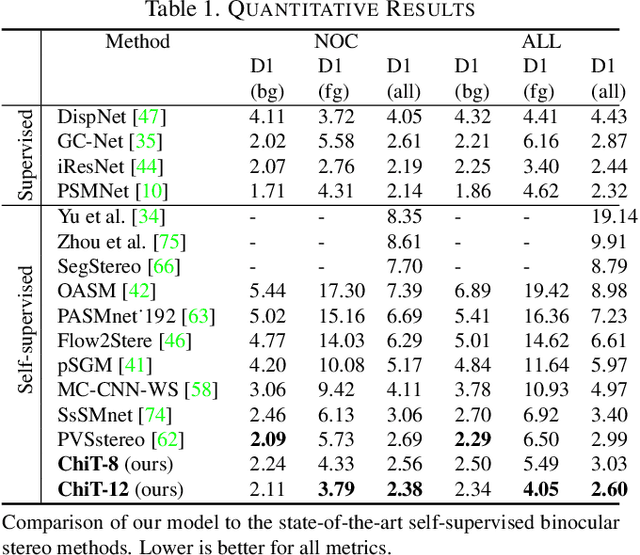
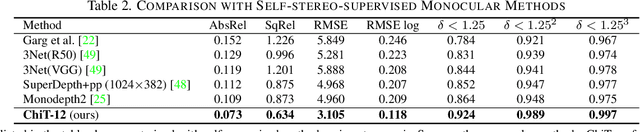

Current stereo matching techniques are challenged by restricted searching space, occluded regions and sheer size. While single image depth estimation is spared from these challenges and can achieve satisfactory results with the extracted monocular cues, the lack of stereoscopic relationship renders the monocular prediction less reliable on its own, especially in highly dynamic or cluttered environments. To address these issues in both scenarios, we present an optic-chiasm-inspired self-supervised binocular depth estimation method, wherein a vision transformer (ViT) with gated positional cross-attention (GPCA) layers is designed to enable feature-sensitive pattern retrieval between views while retaining the extensive context information aggregated through self-attentions. Monocular cues from a single view are thereafter conditionally rectified by a blending layer with the retrieved pattern pairs. This crossover design is biologically analogous to the optic-chasma structure in the human visual system and hence the name, ChiTransformer. Our experiments show that this architecture yields substantial improvements over state-of-the-art self-supervised stereo approaches by 11%, and can be used on both rectilinear and non-rectilinear (e.g., fisheye) images.
Generative Dynamic Patch Attack
Nov 15, 2021
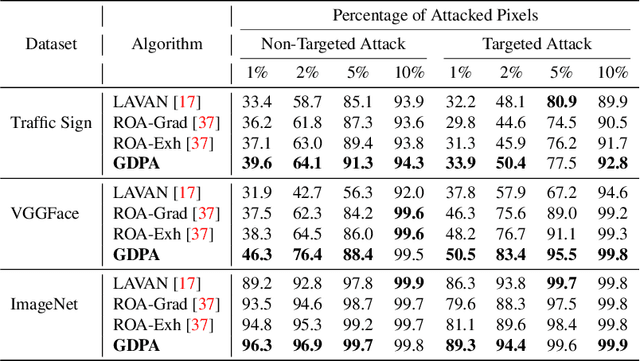
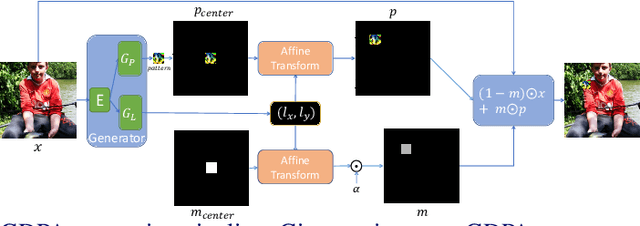
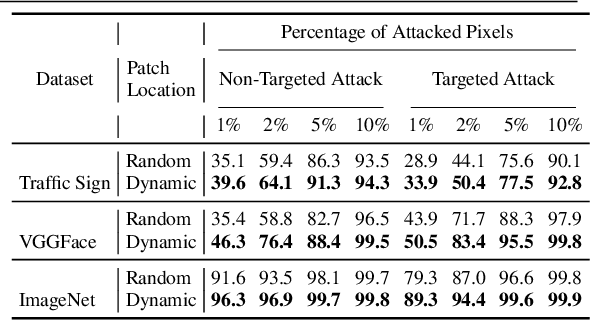
Adversarial patch attack is a family of attack algorithms that perturb a part of image to fool a deep neural network model. Existing patch attacks mostly consider injecting adversarial patches at input-agnostic locations: either a predefined location or a random location. This attack setup may be sufficient for attack but has considerable limitations when using it for adversarial training. Thus, robust models trained with existing patch attacks cannot effectively defend other adversarial attacks. In this paper, we first propose an end-to-end patch attack algorithm, Generative Dynamic Patch Attack (GDPA), which generates both patch pattern and patch location adversarially for each input image. We show that GDPA is a generic attack framework that can produce dynamic/static and visible/invisible patches with a few configuration changes. Secondly, GDPA can be readily integrated for adversarial training to improve model robustness to various adversarial attacks. Extensive experiments on VGGFace, Traffic Sign and ImageNet show that GDPA achieves higher attack success rates than state-of-the-art patch attacks, while adversarially trained model with GDPA demonstrates superior robustness to adversarial patch attacks than competing methods. Our source code can be found at https://github.com/lxuniverse/gdpa.
JEM++: Improved Techniques for Training JEM
Sep 21, 2021
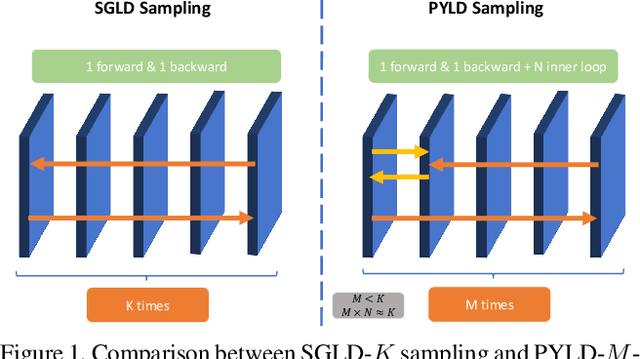

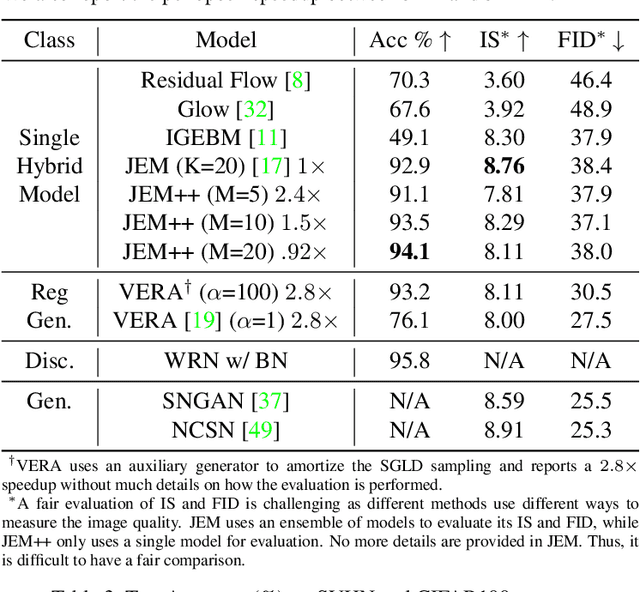
Joint Energy-based Model (JEM) is a recently proposed hybrid model that retains strong discriminative power of modern CNN classifiers, while generating samples rivaling the quality of GAN-based approaches. In this paper, we propose a variety of new training procedures and architecture features to improve JEM's accuracy, training stability, and speed altogether. 1) We propose a proximal SGLD to generate samples in the proximity of samples from the previous step, which improves the stability. 2) We further treat the approximate maximum likelihood learning of EBM as a multi-step differential game, and extend the YOPO framework to cut out redundant calculations during backpropagation, which accelerates the training substantially. 3) Rather than initializing SGLD chain from random noise, we introduce a new informative initialization that samples from a distribution estimated from training data. 4) This informative initialization allows us to enable batch normalization in JEM, which further releases the power of modern CNN architectures for hybrid modeling. Code: https://github.com/sndnyang/JEMPP
Improving Text-to-Image Synthesis Using Contrastive Learning
Jul 06, 2021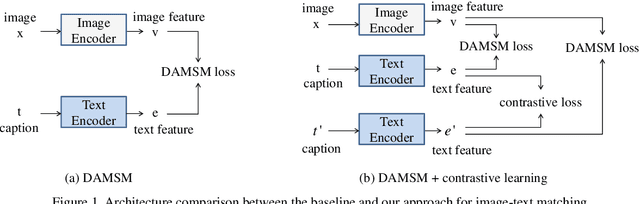
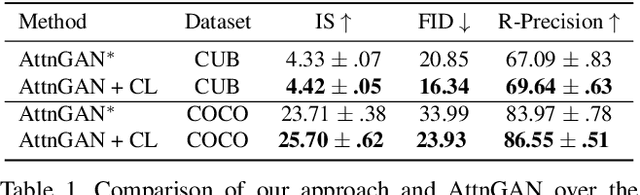
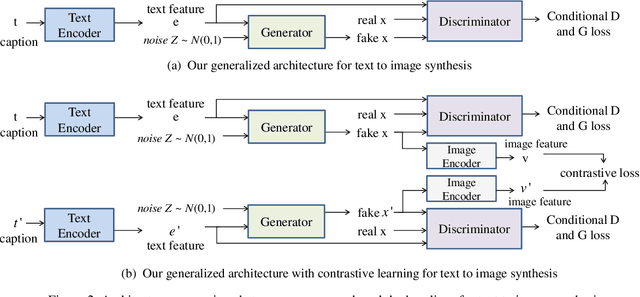

The goal of text-to-image synthesis is to generate a visually realistic image that matches a given text description. In practice, the captions annotated by humans for the same image have large variance in terms of contents and the choice of words. The linguistic discrepancy between the captions of the identical image leads to the synthetic images deviating from the ground truth. To address this issue, we propose a contrastive learning approach to improve the quality and enhance the semantic consistency of synthetic images. In the pre-training stage, we utilize the contrastive learning approach to learn the consistent textual representations for the captions corresponding to the same image. Furthermore, in the following stage of GAN training, we employ the contrastive learning method to enhance the consistency between the generated images from the captions related to the same image. We evaluate our approach over two popular text-to-image synthesis models, AttnGAN and DM-GAN, on datasets CUB and COCO, respectively. Experimental results have shown that our approach can effectively improve the quality of synthetic images in terms of three metrics: IS, FID and R-precision. Especially, on the challenging COCO dataset, our approach boosts the FID significantly by 29.60% over AttnGAn and by 21.96% over DM-GAN.
Dep-$L_0$: Improving $L_0$-based Network Sparsification via Dependency Modeling
Jun 30, 2021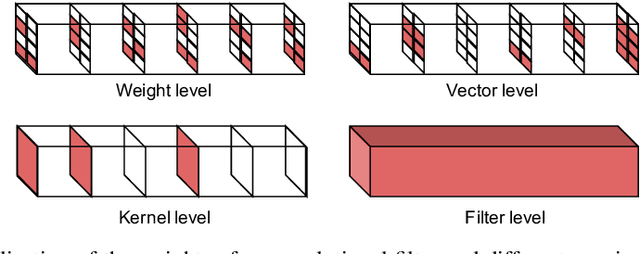
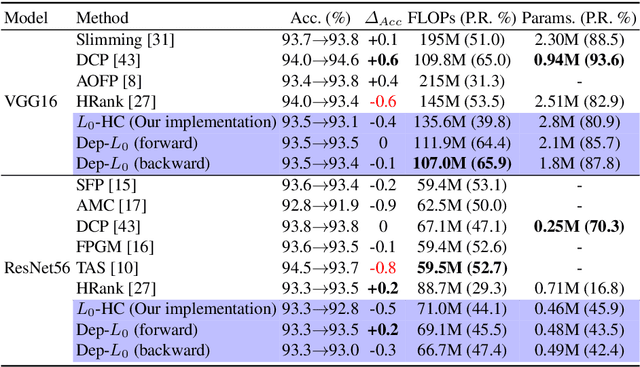
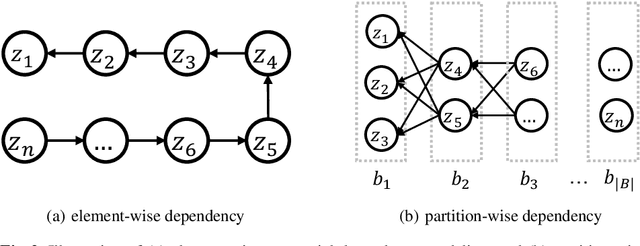
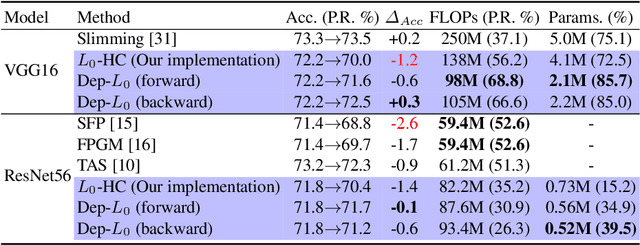
Training deep neural networks with an $L_0$ regularization is one of the prominent approaches for network pruning or sparsification. The method prunes the network during training by encouraging weights to become exactly zero. However, recent work of Gale et al. reveals that although this method yields high compression rates on smaller datasets, it performs inconsistently on large-scale learning tasks, such as ResNet50 on ImageNet. We analyze this phenomenon through the lens of variational inference and find that it is likely due to the independent modeling of binary gates, the mean-field approximation, which is known in Bayesian statistics for its poor performance due to the crude approximation. To mitigate this deficiency, we propose a dependency modeling of binary gates, which can be modeled effectively as a multi-layer perceptron (MLP). We term our algorithm Dep-$L_0$ as it prunes networks via a dependency-enabled $L_0$ regularization. Extensive experiments on CIFAR10, CIFAR100 and ImageNet with VGG16, ResNet50, ResNet56 show that our Dep-$L_0$ outperforms the original $L_0$-HC algorithm of Louizos et al. by a significant margin, especially on ImageNet. Compared with the state-of-the-arts network sparsification algorithms, our dependency modeling makes the $L_0$-based sparsification once again very competitive on large-scale learning tasks. Our source code is available at https://github.com/leo-yangli/dep-l0.
Reducing Risk and Uncertainty of Deep Neural Networks on Diagnosing COVID-19 Infection
Apr 28, 2021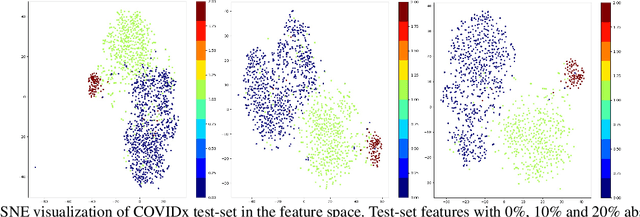
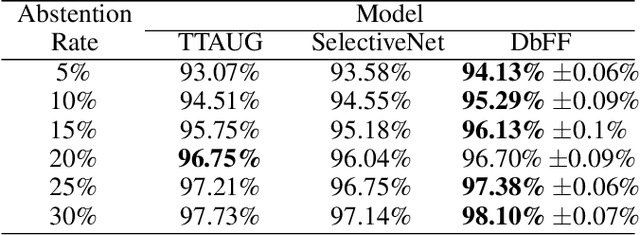

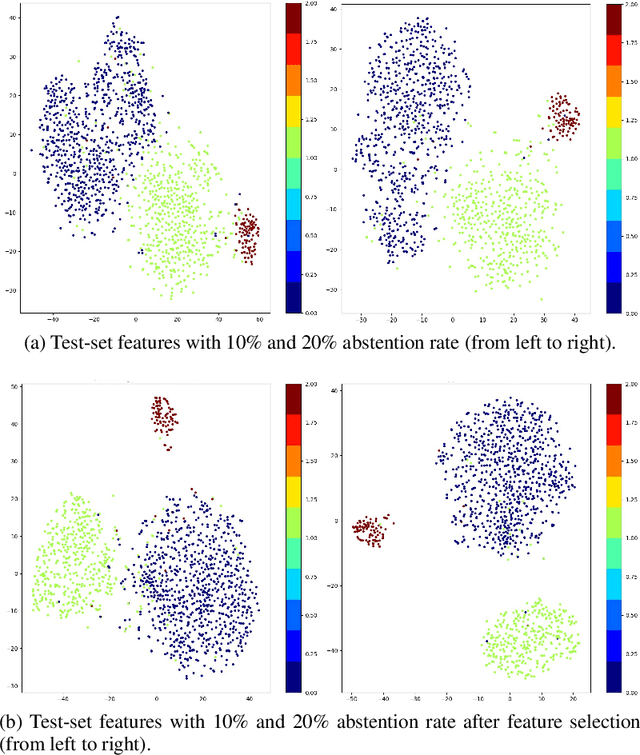
Effective and reliable screening of patients via Computer-Aided Diagnosis can play a crucial part in the battle against COVID-19. Most of the existing works focus on developing sophisticated methods yielding high detection performance, yet not addressing the issue of predictive uncertainty. In this work, we introduce uncertainty estimation to detect confusing cases for expert referral to address the unreliability of state-of-the-art (SOTA) DNNs on COVID-19 detection. To the best of our knowledge, we are the first to address this issue on the COVID-19 detection problem. In this work, we investigate a number of SOTA uncertainty estimation methods on publicly available COVID dataset and present our experimental findings. In collaboration with medical professionals, we further validate the results to ensure the viability of the best performing method in clinical practice.