 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Critic based Improper Reinforcement Learning
Jul 19, 2022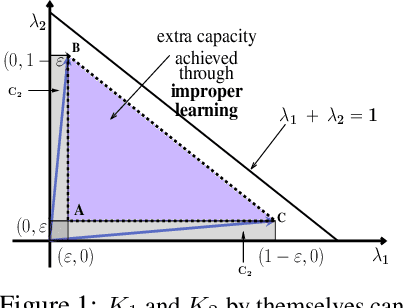

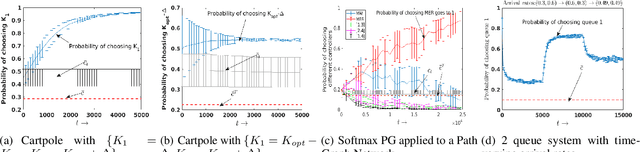
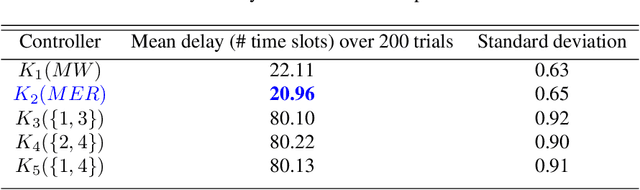
We consider an improper reinforcement learning setting where a learner is given $M$ base controllers for an unknown Markov decision process, and wishes to combine them optimally to produce a potentially new controller that can outperform each of the base ones. This can be useful in tuning across controllers, learnt possibly in mismatched or simulated environments, to obtain a good controller for a given target environment with relatively few trials. Towards this, we propose two algorithms: (1) a Policy Gradient-based approach; and (2) an algorithm that can switch between a simple Actor-Critic (AC) based scheme and a Natural Actor-Critic (NAC) scheme depending on the available information. Both algorithms operate over a class of improper mixtures of the given controllers. For the first case, we derive convergence rate guarantees assuming access to a gradient oracle. For the AC-based approach we provide convergence rate guarantees to a stationary point in the basic AC case and to a global optimum in the NAC case. Numerical results on (i) the standard control theoretic benchmark of stabilizing an cartpole; and (ii) a constrained queueing task show that our improper policy optimization algorithm can stabilize the system even when the base policies at its disposal are unstable.
Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs
Jul 05, 2022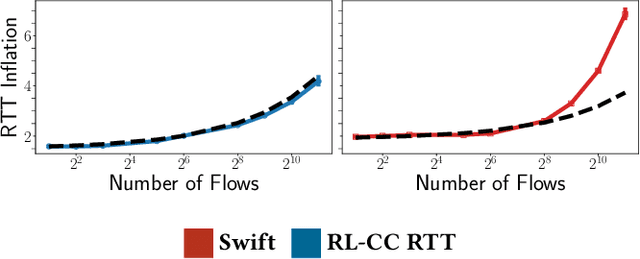

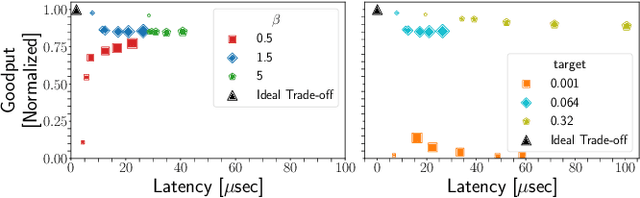
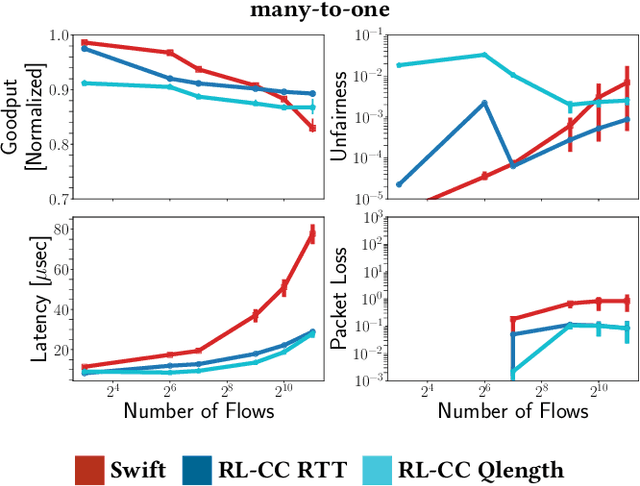
Cloud datacenters are exponentially growing both in numbers and size. This increase results in a network activity surge that warrants better congestion avoidance. The resulting challenge is two-fold: (i) designing algorithms that can be custom-tuned to the complex traffic patterns of a given datacenter; but, at the same time (ii) run on low-level hardware with the required low latency of effective Congestion Control (CC). In this work, we present a Reinforcement Learning (RL) based CC solution that learns from certain traffic scenarios and successfully generalizes to others. We then distill the RL neural network policy into binary decision trees to achieve the desired $\mu$sec decision latency required for real-time inference with RDMA. We deploy the distilled policy on NVIDIA NICs in a real network and demonstrate state-of-the-art performance, balancing all tested metrics simultaneously: bandwidth, latency, fairness, and packet drops.
Analysis of Stochastic Processes through Replay Buffers
Jun 26, 2022

Replay buffers are a key component in many reinforcement learning schemes. Yet, their theoretical properties are not fully understood. In this paper we analyze a system where a stochastic process X is pushed into a replay buffer and then randomly sampled to generate a stochastic process Y from the replay buffer. We provide an analysis of the properties of the sampled process such as stationarity, Markovity and autocorrelation in terms of the properties of the original process. Our theoretical analysis sheds light on why replay buffer may be a good de-correlator. Our analysis provides theoretical tools for proving the convergence of replay buffer based algorithms which are prevalent in reinforcement learning schemes.
Reinforcement Learning with a Terminator
May 30, 2022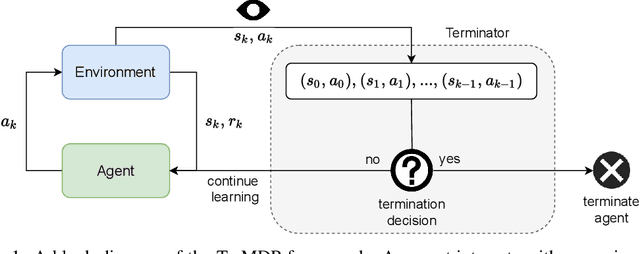
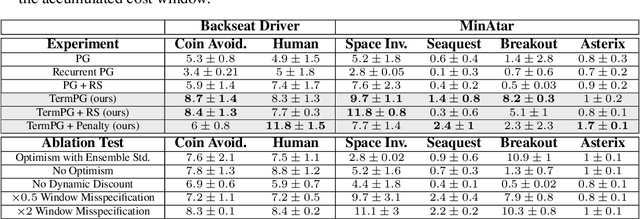
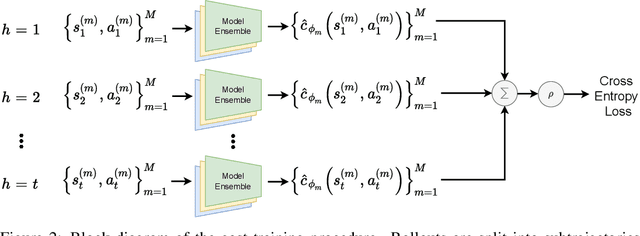
We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.
Efficient Policy Iteration for Robust Markov Decision Processes via Regularization
May 28, 2022
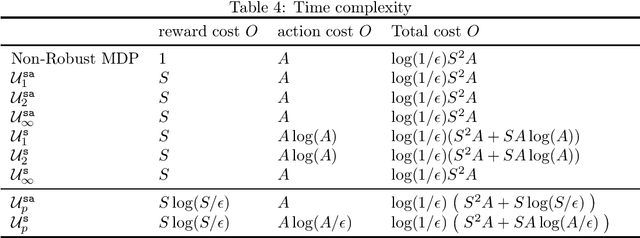
Robust Markov decision processes (MDPs) provide a general framework to model decision problems where the system dynamics are changing or only partially known. Recent work established the equivalence between \texttt{s} rectangular $L_p$ robust MDPs and regularized MDPs, and derived a regularized policy iteration scheme that enjoys the same level of efficiency as standard MDPs. However, there lacks a clear understanding of the policy improvement step. For example, we know the greedy policy can be stochastic but have little clue how each action affects this greedy policy. In this work, we focus on the policy improvement step and derive concrete forms for the greedy policy and the optimal robust Bellman operators. We find that the greedy policy is closely related to some combination of the top $k$ actions, which provides a novel characterization of its stochasticity. The exact nature of the combination depends on the shape of the uncertainty set. Furthermore, our results allow us to efficiently compute the policy improvement step by a simple binary search, without turning to an external optimization subroutine. Moreover, for $L_1, L_2$, and $L_\infty$ robust MDPs, we can even get rid of the binary search and evaluate the optimal robust Bellman operators exactly. Our work greatly extends existing results on solving \texttt{s}-rectangular $L_p$ robust MDPs via regularized policy iteration and can be readily adapted to sample-based model-free algorithms.
Efficient Risk-Averse Reinforcement Learning
May 10, 2022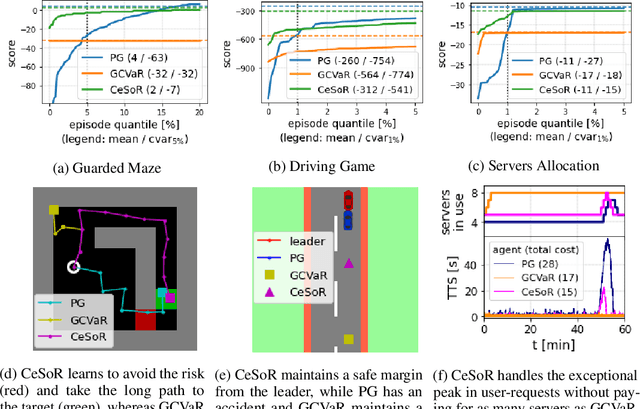
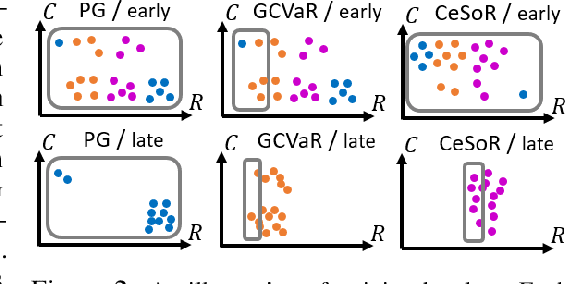
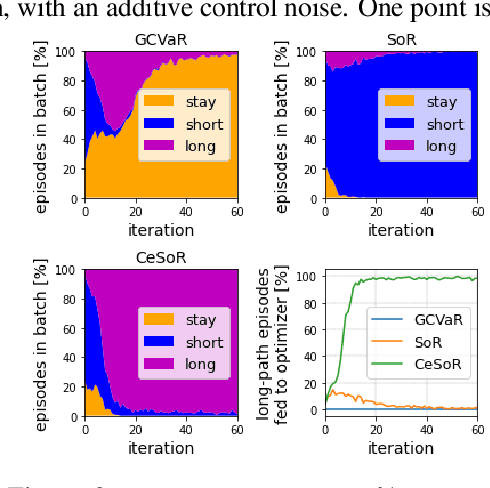
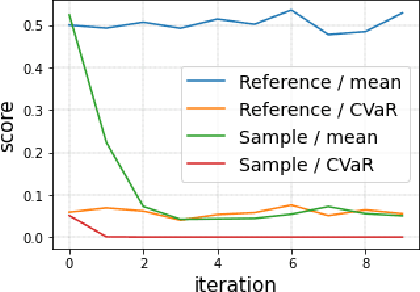
In risk-averse reinforcement learning (RL), the goal is to optimize some risk measure of the returns. A risk measure often focuses on the worst returns out of the agent's experience. As a result, standard methods for risk-averse RL often ignore high-return strategies. We prove that under certain conditions this inevitably leads to a local-optimum barrier, and propose a soft risk mechanism to bypass it. We also devise a novel Cross Entropy module for risk sampling, which (1) preserves risk aversion despite the soft risk; (2) independently improves sample efficiency. By separating the risk aversion of the sampler and the optimizer, we can sample episodes with poor conditions, yet optimize with respect to successful strategies. We combine these two concepts in CeSoR - Cross-entropy Soft-Risk optimization algorithm - which can be applied on top of any risk-averse policy gradient (PG) method. We demonstrate improved risk aversion in maze navigation, autonomous driving, and resource allocation benchmarks, including in scenarios where standard risk-averse PG completely fails.
Optimizing Tensor Network Contraction Using Reinforcement Learning
Apr 18, 2022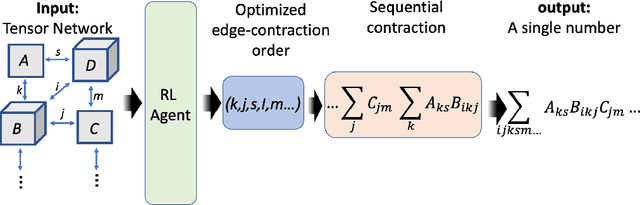
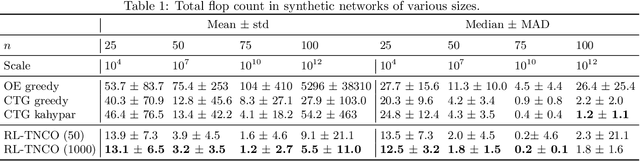
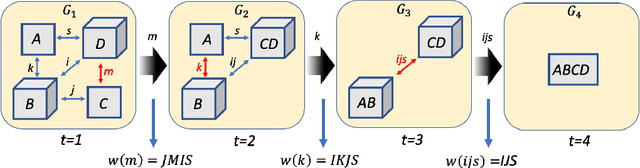

Quantum Computing (QC) stands to revolutionize computing, but is currently still limited. To develop and test quantum algorithms today, quantum circuits are often simulated on classical computers. Simulating a complex quantum circuit requires computing the contraction of a large network of tensors. The order (path) of contraction can have a drastic effect on the computing cost, but finding an efficient order is a challenging combinatorial optimization problem. We propose a Reinforcement Learning (RL) approach combined with Graph Neural Networks (GNN) to address the contraction ordering problem. The problem is extremely challenging due to the huge search space, the heavy-tailed reward distribution, and the challenging credit assignment. We show how a carefully implemented RL-agent that uses a GNN as the basic policy construct can address these challenges and obtain significant improvements over state-of-the-art techniques in three varieties of circuits, including the largest scale networks used in contemporary QC.
Whats Missing? Learning Hidden Markov Models When the Locations of Missing Observations are Unknown
Mar 12, 2022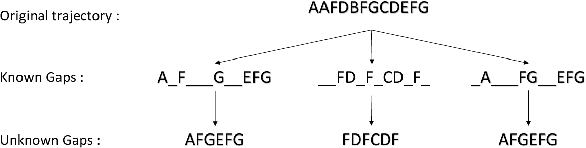
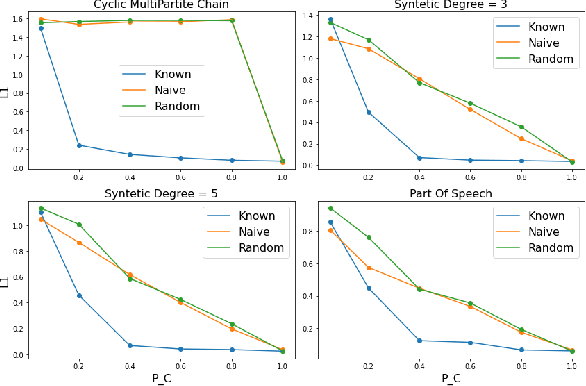
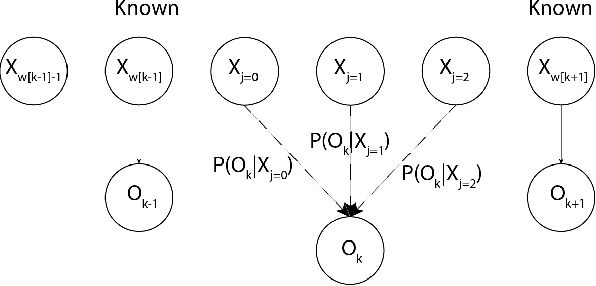
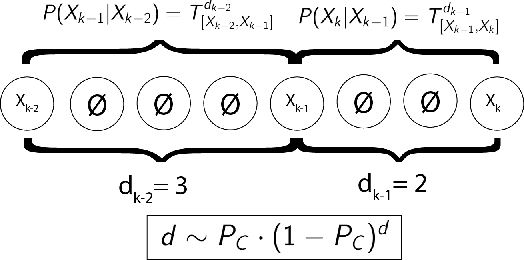
The Hidden Markov Model (HMM) is one of the most widely used statistical models for sequential data analysis, and it has been successfully applied in a large variety of domains. One of the key reasons for this versatility is the ability of HMMs to deal with missing data. However, standard HMM learning algorithms rely crucially on the assumption that the positions of the missing observations within the observation sequence are known. In some situations where such assumptions are not feasible, a number of special algorithms have been developed. Currently, these algorithms rely strongly on specific structural assumptions of the underlying chain, such as acyclicity, and are not applicable in the general case. In particular, there are numerous domains within medicine and computational biology, where the missing observation locations are unknown and acyclicity assumptions do not hold, thus presenting a barrier for the application of HMMs in those fields. In this paper we consider a general problem of learning HMMs from data with unknown missing observation locations (i.e., only the order of the non-missing observations are known). We introduce a generative model of the location omissions and propose two learning methods for this model, a (semi) analytic approach, and a Gibbs sampler. We evaluate and compare the algorithms in a variety of scenarios, measuring their reconstruction precision and robustness under model misspecification.
Learning to reason about and to act on physical cascading events
Feb 02, 2022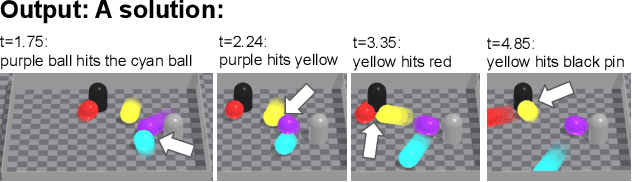
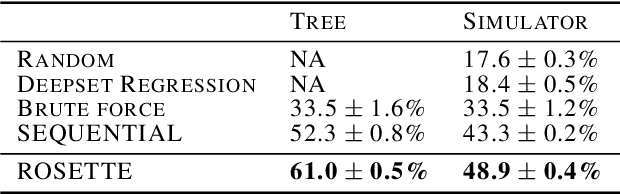
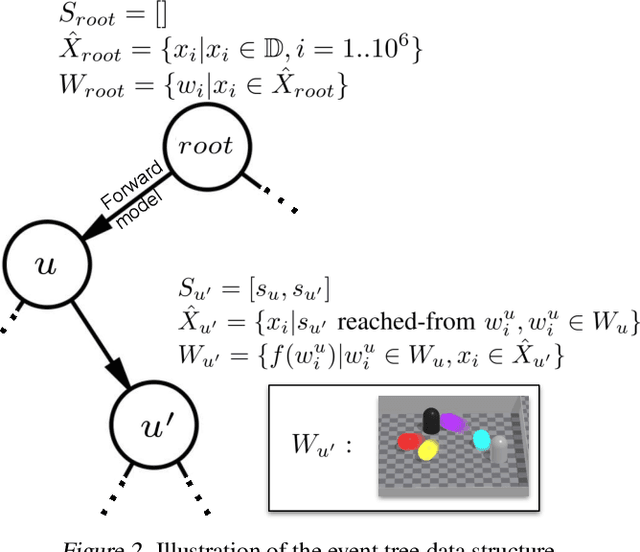

Reasoning and interacting with dynamic environments is a fundamental problem in AI, but it becomes extremely challenging when actions can trigger cascades of cross-dependent events. We introduce a new supervised learning setup called {\em Cascade} where an agent is shown a video of a physically simulated dynamic scene, and is asked to intervene and trigger a cascade of events, such that the system reaches a "counterfactual" goal. For instance, the agent may be asked to "Make the blue ball hit the red one, by pushing the green ball". The agent intervention is drawn from a continuous space, and cascades of events makes the dynamics highly non-linear. We combine semantic tree search with an event-driven forward model and devise an algorithm that learns to search in semantic trees in continuous spaces. We demonstrate that our approach learns to effectively follow instructions to intervene in previously unseen complex scenes. It can also reason about alternative outcomes, when provided an observed cascade of events.
Continuous Forecasting via Neural Eigen Decomposition of Stochastic Dynamics
Feb 02, 2022



Motivated by a real-world problem of blood coagulation control in Heparin-treated patients, we use Stochastic Differential Equations (SDEs) to formulate a new class of sequential prediction problems -- with an unknown latent space, unknown non-linear dynamics, and irregular sparse observations. We introduce the Neural Eigen-SDE (NESDE) algorithm for sequential prediction with sparse observations and adaptive dynamics. NESDE applies eigen-decomposition to the dynamics model to allow efficient frequent predictions given sparse observations. In addition, NESDE uses a learning mechanism for adaptive dynamics model, which handles changes in the dynamics both between sequences and within sequences. We demonstrate the accuracy and efficacy of NESDE for both synthetic problems and real-world data. In particular, to the best of our knowledge, we are the first to provide a patient-adapted prediction for blood coagulation following Heparin dosing in the MIMIC-IV dataset. Finally, we publish a simulated gym environment based on our prediction model, for experimentation in algorithms for blood coagulation control.