 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlapping Community Detection by Online Cluster Aggregation
Apr 26, 2015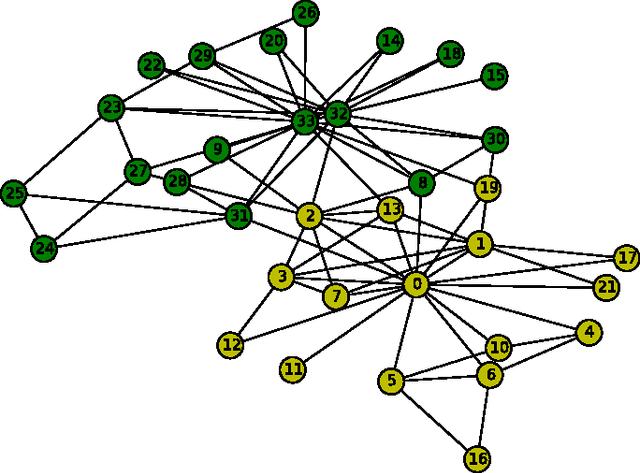
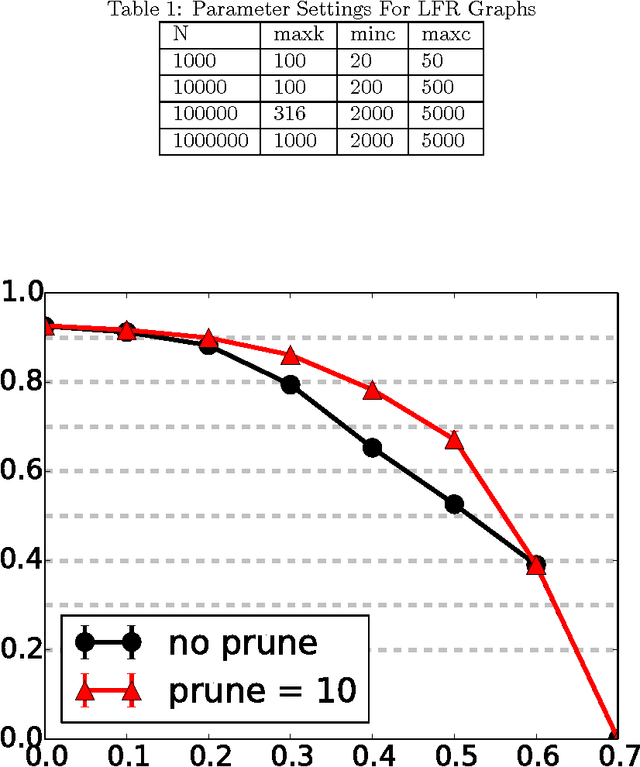

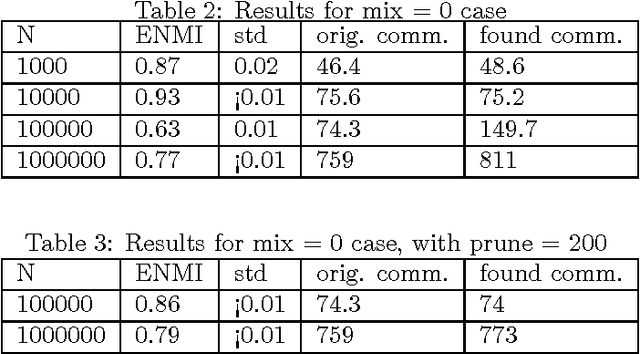
We present a new online algorithm for detecting overlapping communities. The main ingredients are a modification of an online k-means algorithm and a new approach to modelling overlap in communities. An evaluation on large benchmark graphs shows that the quality of discovered communities compares favorably to several methods in the recent literature, while the running time is significantly improved.
Actively Learning to Attract Followers on Twitter
Apr 16, 2015
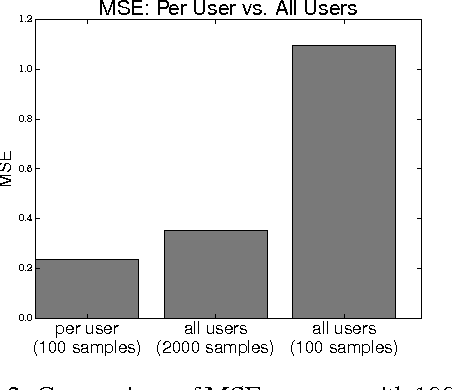
Twitter, a popular social network, presents great opportunities for on-line machine learning research. However, previous research has focused almost entirely on learning from passively collected data. We study the problem of learning to acquire followers through normative user behavior, as opposed to the mass following policies applied by many bots. We formalize the problem as a contextual bandit problem, in which we consider retweeting content to be the action chosen and each tweet (content) is accompanied by context. We design reward signals based on the change in followers. The result of our month long experiment with 60 agents suggests that (1) aggregating experience across agents can adversely impact prediction accuracy and (2) the Twitter community's response to different actions is non-stationary. Our findings suggest that actively learning on-line can provide deeper insights about how to attract followers than machine learning over passively collected data alone.
Thompson Sampling for Learning Parameterized Markov Decision Processes
Mar 31, 2015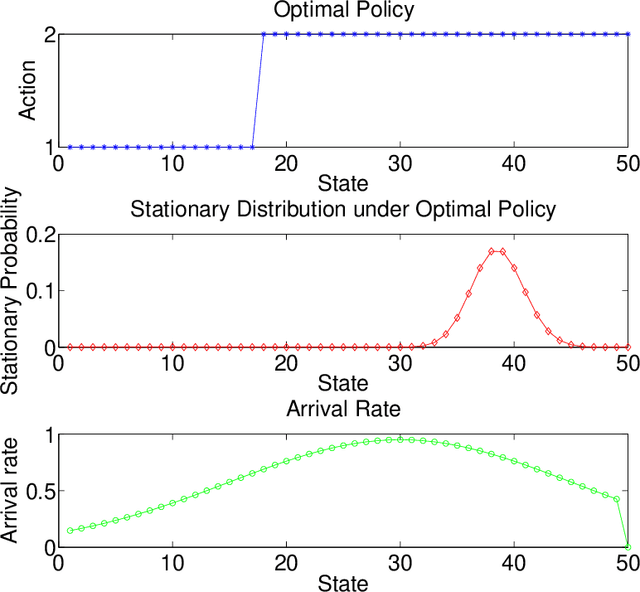
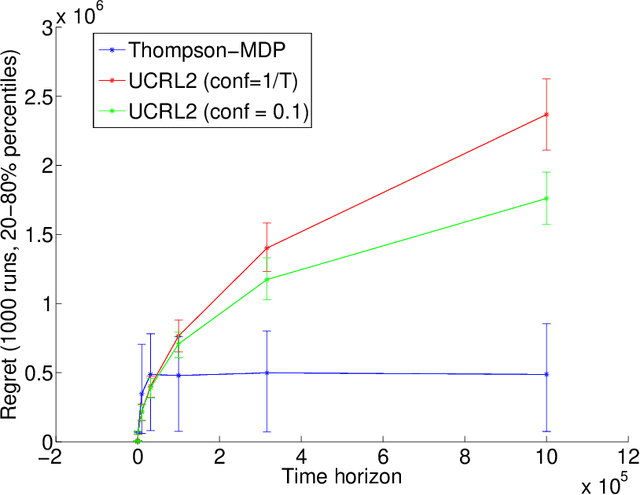
We consider reinforcement learning in parameterized Markov Decision Processes (MDPs), where the parameterization may induce correlation across transition probabilities or rewards. Consequently, observing a particular state transition might yield useful information about other, unobserved, parts of the MDP. We present a version of Thompson sampling for parameterized reinforcement learning problems, and derive a frequentist regret bound for priors over general parameter spaces. The result shows that the number of instants where suboptimal actions are chosen scales logarithmically with time, with high probability. It holds for prior distributions that put significant probability near the true model, without any additional, specific closed-form structure such as conjugate or product-form priors. The constant factor in the logarithmic scaling encodes the information complexity of learning the MDP in terms of the Kullback-Leibler geometry of the parameter space.
Off-policy evaluation for MDPs with unknown structure
Feb 11, 2015



Off-policy learning in dynamic decision problems is essential for providing strong evidence that a new policy is better than the one in use. But how can we prove superiority without testing the new policy? To answer this question, we introduce the G-SCOPE algorithm that evaluates a new policy based on data generated by the existing policy. Our algorithm is both computationally and sample efficient because it greedily learns to exploit factored structure in the dynamics of the environment. We present a finite sample analysis of our approach and show through experiments that the algorithm scales well on high-dimensional problems with few samples.
Contextual Markov Decision Processes
Feb 08, 2015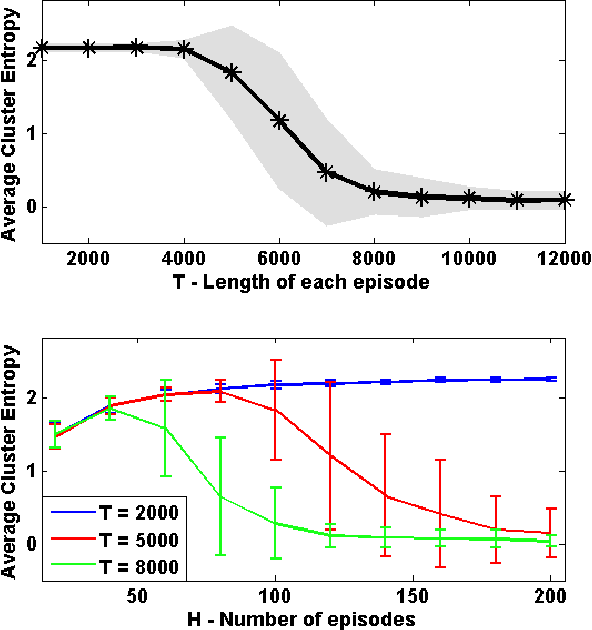
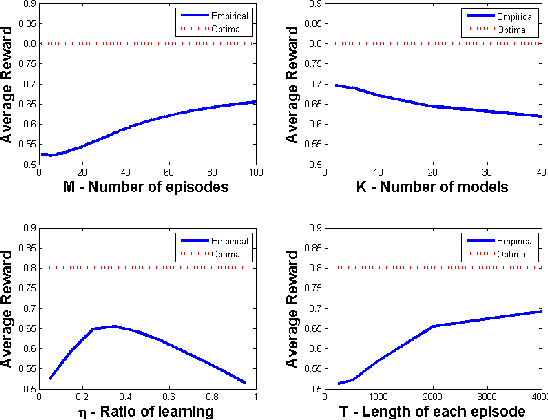
We consider a planning problem where the dynamics and rewards of the environment depend on a hidden static parameter referred to as the context. The objective is to learn a strategy that maximizes the accumulated reward across all contexts. The new model, called Contextual Markov Decision Process (CMDP), can model a customer's behavior when interacting with a website (the learner). The customer's behavior depends on gender, age, location, device, etc. Based on that behavior, the website objective is to determine customer characteristics, and to optimize the interaction between them. Our work focuses on one basic scenario--finite horizon with a small known number of possible contexts. We suggest a family of algorithms with provable guarantees that learn the underlying models and the latent contexts, and optimize the CMDPs. Bounds are obtained for specific naive implementations, and extensions of the framework are discussed, laying the ground for future research.
Distributed Robust Learning
Feb 07, 2015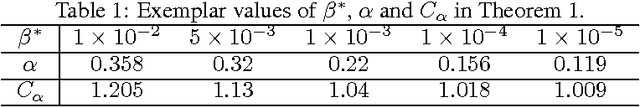
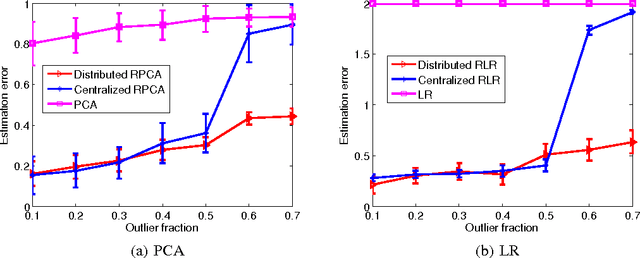
We propose a framework for distributed robust statistical learning on {\em big contaminated data}. The Distributed Robust Learning (DRL) framework can reduce the computational time of traditional robust learning methods by several orders of magnitude. We analyze the robustness property of DRL, showing that DRL not only preserves the robustness of the base robust learning method, but also tolerates contaminations on a constant fraction of results from computing nodes (node failures). More precisely, even in presence of the most adversarial outlier distribution over computing nodes, DRL still achieves a breakdown point of at least $ \lambda^*/2 $, where $ \lambda^* $ is the break down point of corresponding centralized algorithm. This is in stark contrast with naive division-and-averaging implementation, which may reduce the breakdown point by a factor of $ k $ when $ k $ computing nodes are used. We then specialize the DRL framework for two concrete cases: distributed robust principal component analysis and distributed robust regression. We demonstrate the efficiency and the robustness advantages of DRL through comprehensive simulations and predicting image tags on a large-scale image set.
Implicit Temporal Differences
Dec 21, 2014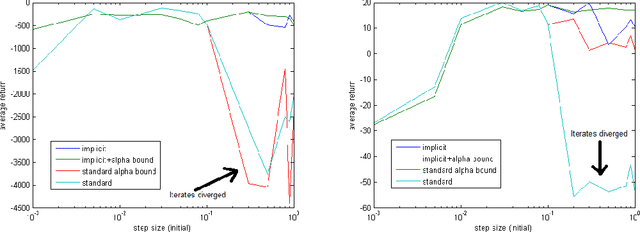
In reinforcement learning, the TD($\lambda$) algorithm is a fundamental policy evaluation method with an efficient online implementation that is suitable for large-scale problems. One practical drawback of TD($\lambda$) is its sensitivity to the choice of the step-size. It is an empirically well-known fact that a large step-size leads to fast convergence, at the cost of higher variance and risk of instability. In this work, we introduce the implicit TD($\lambda$) algorithm which has the same function and computational cost as TD($\lambda$), but is significantly more stable. We provide a theoretical explanation of this stability and an empirical evaluation of implicit TD($\lambda$) on typical benchmark tasks. Our results show that implicit TD($\lambda$) outperforms standard TD($\lambda$) and a state-of-the-art method that automatically tunes the step-size, and thus shows promise for wide applicability.
Optimizing the CVaR via Sampling
Nov 22, 2014

Conditional Value at Risk (CVaR) is a prominent risk measure that is being used extensively in various domains. We develop a new formula for the gradient of the CVaR in the form of a conditional expectation. Based on this formula, we propose a novel sampling-based estimator for the CVaR gradient, in the spirit of the likelihood-ratio method. We analyze the bias of the estimator, and prove the convergence of a corresponding stochastic gradient descent algorithm to a local CVaR optimum. Our method allows to consider CVaR optimization in new domains. As an example, we consider a reinforcement learning application, and learn a risk-sensitive controller for the game of Tetris.
Nonstochastic Multi-Armed Bandits with Graph-Structured Feedback
Sep 30, 2014
We present and study a partial-information model of online learning, where a decision maker repeatedly chooses from a finite set of actions, and observes some subset of the associated losses. This naturally models several situations where the losses of different actions are related, and knowing the loss of one action provides information on the loss of other actions. Moreover, it generalizes and interpolates between the well studied full-information setting (where all losses are revealed) and the bandit setting (where only the loss of the action chosen by the player is revealed). We provide several algorithms addressing different variants of our setting, and provide tight regret bounds depending on combinatorial properties of the information feedback structure.
Online Convex Optimization Against Adversaries with Memory and Application to Statistical Arbitrage
Jun 10, 2014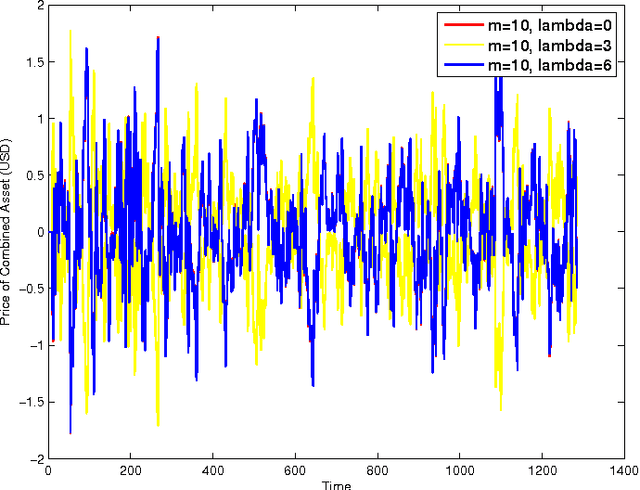
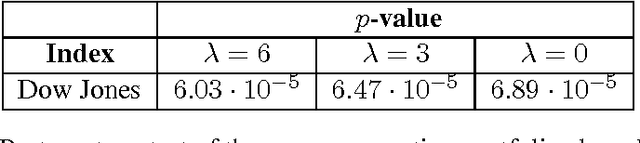
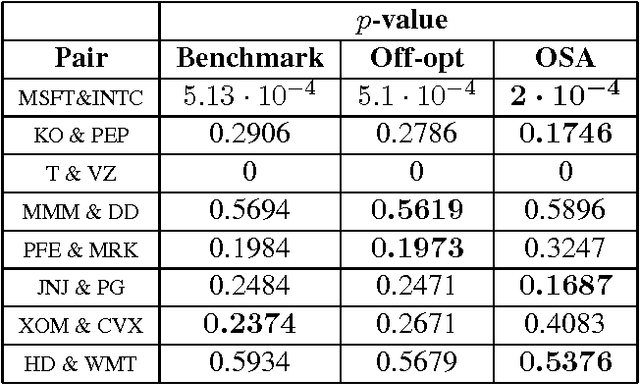
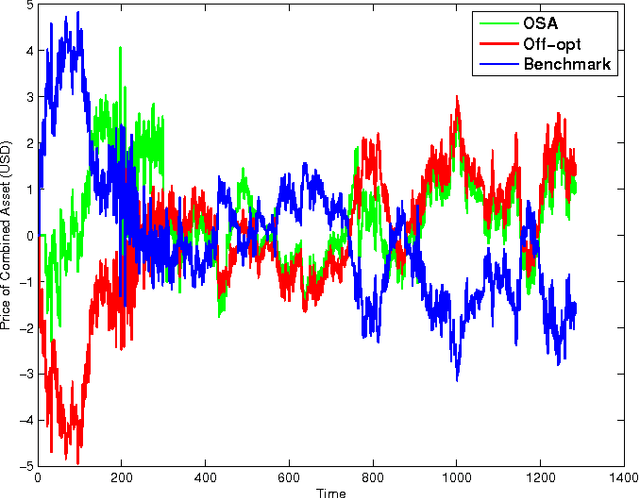
The framework of online learning with memory naturally captures learning problems with temporal constraints, and was previously studied for the experts setting. In this work we extend the notion of learning with memory to the general Online Convex Optimization (OCO) framework, and present two algorithms that attain low regret. The first algorithm applies to Lipschitz continuous loss functions, obtaining optimal regret bounds for both convex and strongly convex losses. The second algorithm attains the optimal regret bounds and applies more broadly to convex losses without requiring Lipschitz continuity, yet is more complicated to implement. We complement our theoretic results with an application to statistical arbitrage in finance: we devise algorithms for constructing mean-reverting portfolios.