 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-user Communication Networks: A Coordinated Multi-armed Bandit Approach
Aug 14, 2018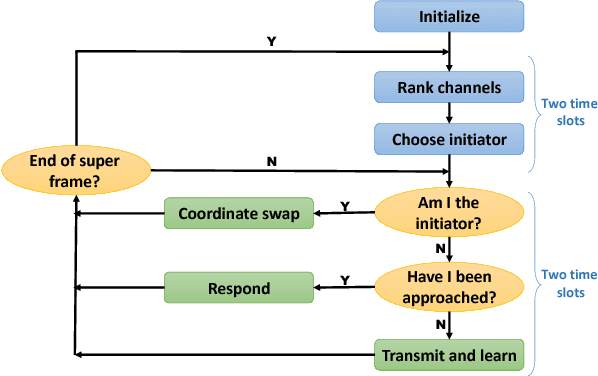

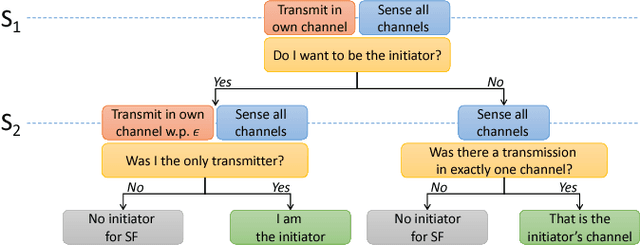
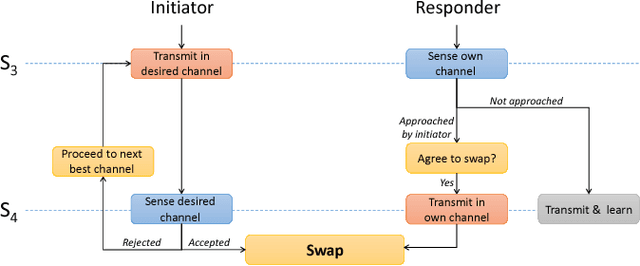
Communication networks shared by many users are a widespread challenge nowadays. In this paper we address several aspects of this challenge simultaneously: learning unknown stochastic network characteristics, sharing resources with other users while keeping coordination overhead to a minimum. The proposed solution combines Multi-Armed Bandit learning with a lightweight signalling-based coordination scheme, and ensures convergence to a stable allocation of resources. Our work considers single-user level algorithms for two scenarios: an unknown fixed number of users, and a dynamic number of users. Analytic performance guarantees, proving convergence to stable marriage configurations, are presented for both setups. The algorithms are designed based on a system-wide perspective, rather than focusing on single user welfare. Thus, maximal resource utilization is ensured. An extensive experimental analysis covers convergence to a stable configuration as well as reward maximization. Experiments are carried out over a wide range of setups, demonstrating the advantages of our approach over existing state-of-the-art methods.
Beyond the One Step Greedy Approach in Reinforcement Learning
Jul 30, 2018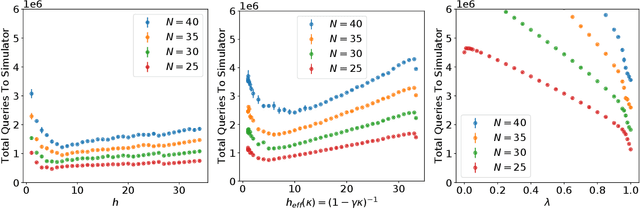
The famous Policy Iteration algorithm alternates between policy improvement and policy evaluation. Implementations of this algorithm with several variants of the latter evaluation stage, e.g, $n$-step and trace-based returns, have been analyzed in previous works. However, the case of multiple-step lookahead policy improvement, despite the recent increase in empirical evidence of its strength, has to our knowledge not been carefully analyzed yet. In this work, we introduce the first such analysis. Namely, we formulate variants of multiple-step policy improvement, derive new algorithms using these definitions and prove their convergence. Moreover, we show that recent prominent Reinforcement Learning algorithms are, in fact, instances of our framework. We thus shed light on their empirical success and give a recipe for deriving new algorithms for future study.
A General Approach to Multi-Armed Bandits Under Risk Criteria
Jun 04, 2018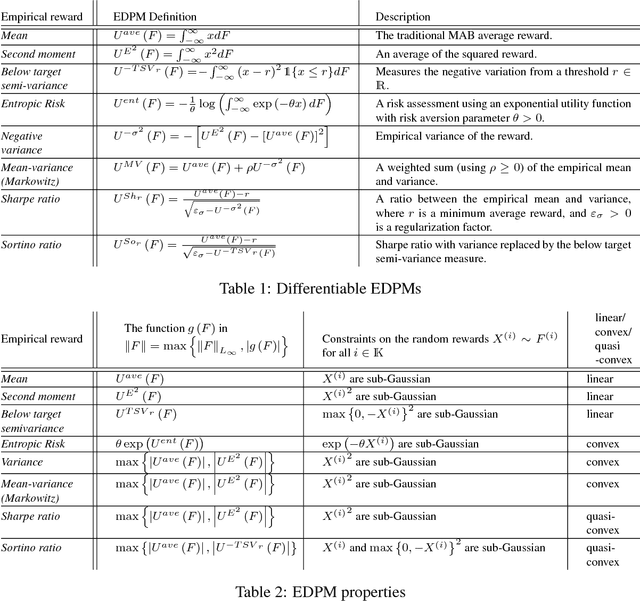
Different risk-related criteria have received recent interest in learning problems, where typically each case is treated in a customized manner. In this paper we provide a more systematic approach to analyzing such risk criteria within a stochastic multi-armed bandit (MAB) formulation. We identify a set of general conditions that yield a simple characterization of the oracle rule (which serves as the regret benchmark), and facilitate the design of upper confidence bound (UCB) learning policies. The conditions are derived from problem primitives, primarily focusing on the relation between the arm reward distributions and the (risk criteria) performance metric. Among other things, the work highlights some (possibly non-intuitive) subtleties that differentiate various criteria in conjunction with statistical properties of the arms. Our main findings are illustrated on several widely used objectives such as conditional value-at-risk, mean-variance, Sharpe-ratio, and more.
Finite Sample Analysis of Two-Timescale Stochastic Approximation with Applications to Reinforcement Learning
Jun 04, 2018

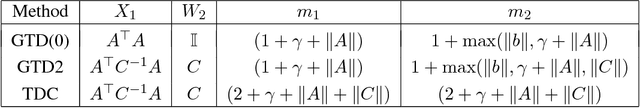
Two-timescale Stochastic Approximation (SA) algorithms are widely used in Reinforcement Learning (RL). Their iterates have two parts that are updated using distinct stepsizes. In this work, we develop a novel recipe for their finite sample analysis. Using this, we provide a concentration bound, which is the first such result for a two-timescale SA. The type of bound we obtain is known as `lock-in probability'. We also introduce a new projection scheme, in which the time between successive projections increases exponentially. This scheme allows one to elegantly transform a lock-in probability into a convergence rate result for projected two-timescale SA. From this latter result, we then extract key insights on stepsize selection. As an application, we finally obtain convergence rates for the projected two-timescale RL algorithms GTD(0), GTD2, and TDC.
Reward Constrained Policy Optimization
May 28, 2018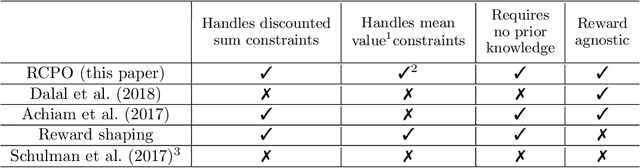
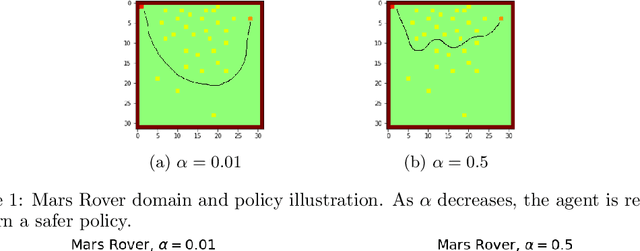
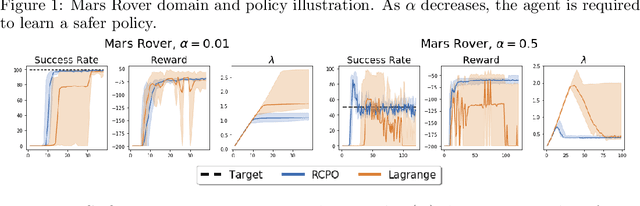
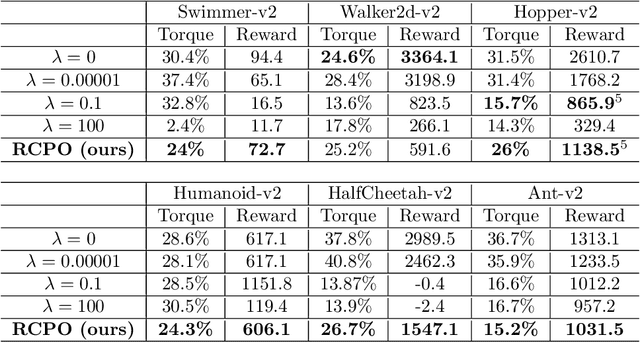
Teaching agents to perform tasks using Reinforcement Learning is no easy feat. As the goal of reinforcement learning agents is to maximize the accumulated reward, they often find loopholes and misspecifications in the reward signal which lead to unwanted behavior. To overcome this, often, regularization is employed through the technique of reward shaping - the agent is provided an additional weighted reward signal, meant to lead it towards a desired behavior. The weight is considered as a hyper-parameter and is selected through trial and error, a time consuming and computationally intensive task. In this work, we present a novel multi-timescale approach for constrained policy optimization, called, 'Reward Constrained Policy Optimization' (RCPO), which enables policy regularization without the use of reward shaping. We prove the convergence of our approach and provide empirical evidence of its ability to train constraint satisfying policies.
Nonlinear Distributional Gradient Temporal-Difference Learning
May 20, 2018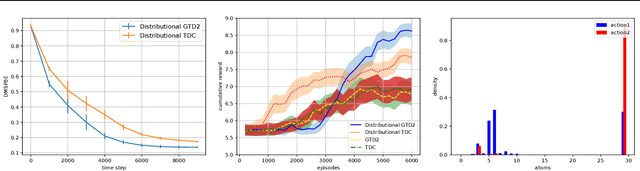
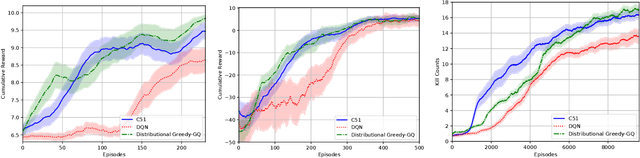
We devise a distributional variant of gradient temporal-difference (TD) learning. Distributional reinforcement learning has been demonstrated to outperform the regular one in the recent study \citep{bellemare2017distributional}. In our paper, we design two new algorithms called distributional GTD2 and distributional TDC using the Cram{\'e}r distance on the distributional version of the Bellman error objective function, which inherits advantages of both the nonlinear gradient TD algorithms and the distributional RL approach. We prove the asymptotic almost-sure convergence to a local optimal solution for general smooth function approximators, which includes neural networks that have been widely used in recent study to solve the real-life RL problems. In each step, the computational complexity is linear w.r.t.\ the number of the parameters of the function approximator, thus can be implemented efficiently for neural networks.
Interdependent Gibbs Samplers
Apr 19, 2018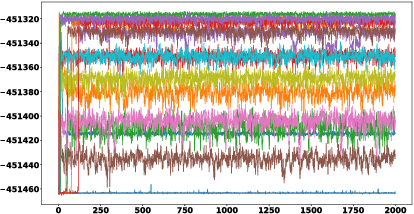
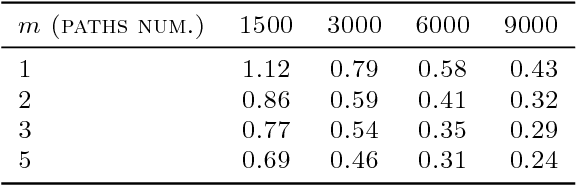
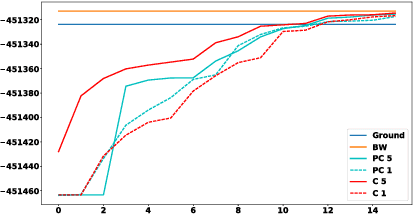

Gibbs sampling, as a model learning method, is known to produce the most accurate results available in a variety of domains, and is a de facto standard in these domains. Yet, it is also well known that Gibbs random walks usually have bottlenecks, sometimes termed "local maxima", and thus samplers often return suboptimal solutions. In this paper we introduce a variation of the Gibbs sampler which yields high likelihood solutions significantly more often than the regular Gibbs sampler. Specifically, we show that combining multiple samplers, with certain dependence (coupling) between them, results in higher likelihood solutions. This side-steps the well known issue of identifiability, which has been the obstacle to combining samplers in previous work. We evaluate the approach on a Latent Dirichlet Allocation model, and also on HMM's, where precise computation of likelihoods and comparisons to the standard EM algorithm are possible.
Deep Learning Reconstruction of Ultra-Short Pulses
Mar 15, 2018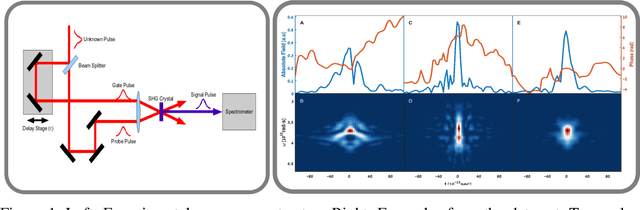
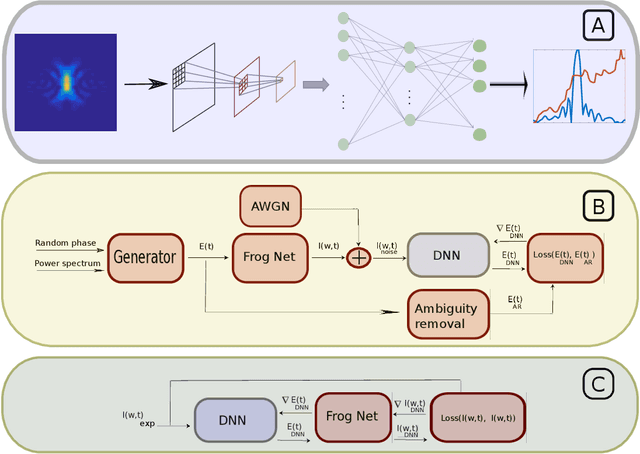
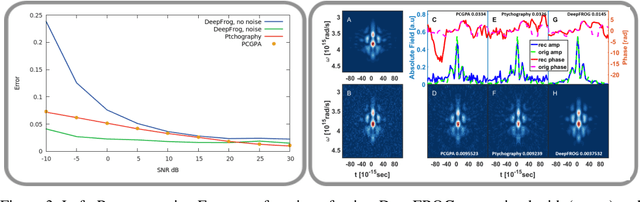
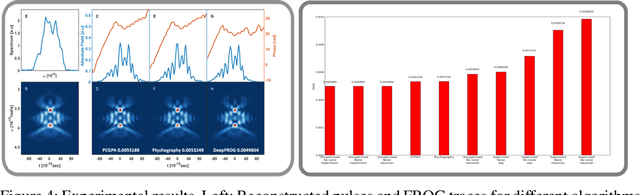
Ultra-short laser pulses with femtosecond to attosecond pulse duration are the shortest systematic events humans can create. Characterization (amplitude and phase) of these pulses is a key ingredient in ultrafast science, e.g., exploring chemical reactions and electronic phase transitions. Here, we propose and demonstrate, numerically and experimentally, the first deep neural network technique to reconstruct ultra-short optical pulses. We anticipate that this approach will extend the range of ultrashort laser pulses that can be characterized, e.g., enabling to diagnose very weak attosecond pulses.
Unit Commitment using Nearest Neighbor as a Short-Term Proxy
Feb 28, 2018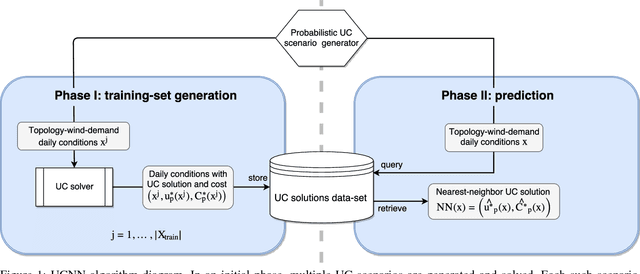
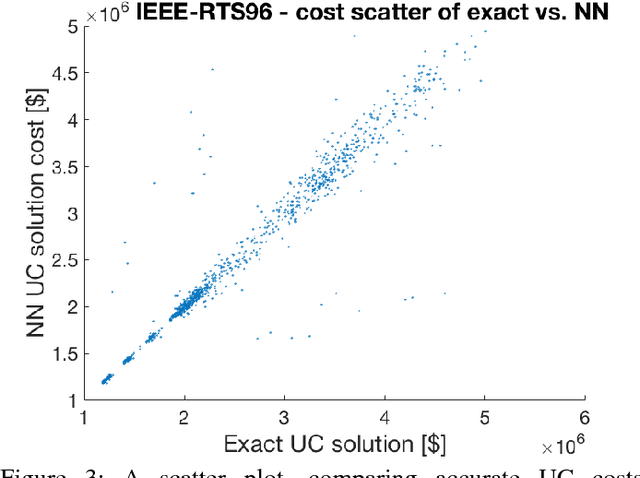
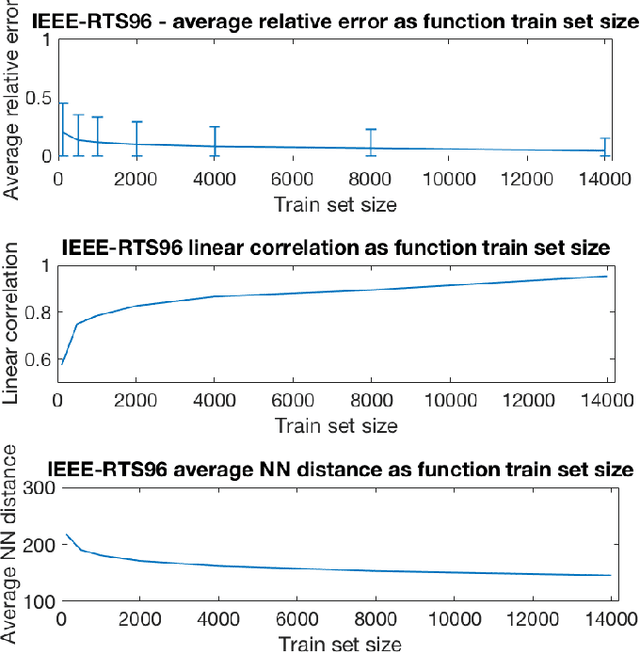
We devise the Unit Commitment Nearest Neighbor (UCNN) algorithm to be used as a proxy for quickly approximating outcomes of short-term decisions, to make tractable hierarchical long-term assessment and planning for large power systems. Experimental results on updated versions of IEEE-RTS79 and IEEE-RTS96 show high accuracy measured on operational cost, achieved in runtimes that are lower in several orders of magnitude than the traditional approach.
Train on Validation: Squeezing the Data Lemon
Feb 16, 2018

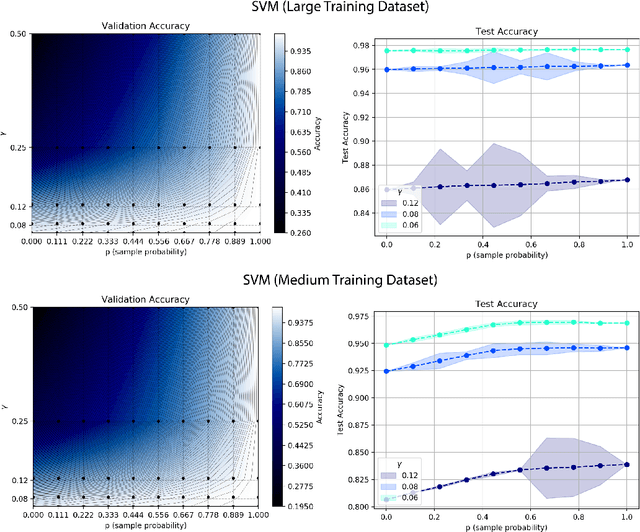
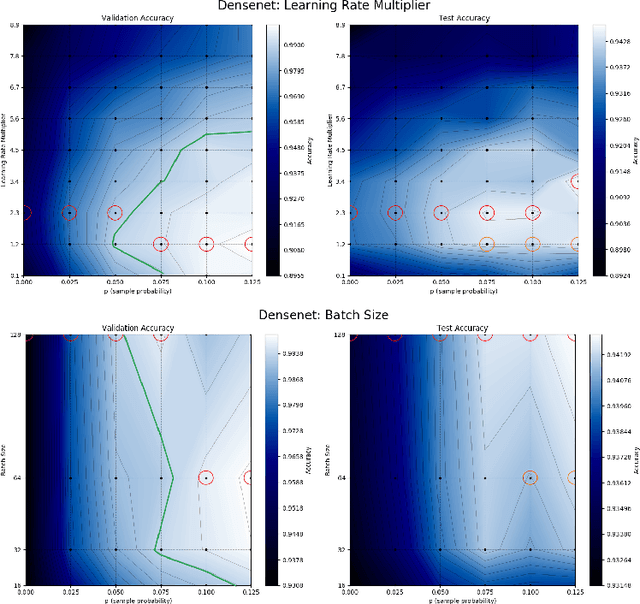
Model selection on validation data is an essential step in machine learning. While the mixing of data between training and validation is considered taboo, practitioners often violate it to increase performance. Here, we offer a simple, practical method for using the validation set for training, which allows for a continuous, controlled trade-off between performance and overfitting of model selection. We define the notion of on-average-validation-stable algorithms as one in which using small portions of validation data for training does not overfit the model selection process. We then prove that stable algorithms are also validation stable. Finally, we demonstrate our method on the MNIST and CIFAR-10 datasets using stable algorithms as well as state-of-the-art neural networks. Our results show significant increase in test performance with a minor trade-off in bias admitted to the model selection process.