 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
GAS: Enhancing Reward-Cost Balance of Generative Model-assisted Offline Safe RL
Feb 05, 2026Offline Safe Reinforcement Learning (OSRL) aims to learn a policy to achieve high performance in sequential decision-making while satisfying constraints, using only pre-collected datasets. Recent works, inspired by the strong capabilities of Generative Models (GMs), reformulate decision-making in OSRL as a conditional generative process, where GMs generate desirable actions conditioned on predefined reward and cost values. However, GM-assisted methods face two major challenges in OSRL: (1) lacking the ability to "stitch" optimal transitions from suboptimal trajectories within the dataset, and (2) struggling to balance reward targets with cost targets, particularly when they are conflict. To address these issues, we propose Goal-Assisted Stitching (GAS), a novel algorithm designed to enhance stitching capabilities while effectively balancing reward maximization and constraint satisfaction. To enhance the stitching ability, GAS first augments and relabels the dataset at the transition level, enabling the construction of high-quality trajectories from suboptimal ones. GAS also introduces novel goal functions, which estimate the optimal achievable reward and cost goals from the dataset. These goal functions, trained using expectile regression on the relabeled and augmented dataset, allow GAS to accommodate a broader range of reward-cost return pairs and achieve a better tradeoff between reward maximization and constraint satisfaction compared to human-specified values. The estimated goals then guide policy training, ensuring robust performance under constrained settings. Furthermore, to improve training stability and efficiency, we reshape the dataset to achieve a more uniform reward-cost return distribution. Empirical results validate the effectiveness of GAS, demonstrating superior performance in balancing reward maximization and constraint satisfaction compared to existing methods.
Puzzle it Out: Local-to-Global World Model for Offline Multi-Agent Reinforcement Learning
Jan 12, 2026Offline multi-agent reinforcement learning (MARL) aims to solve cooperative decision-making problems in multi-agent systems using pre-collected datasets. Existing offline MARL methods primarily constrain training within the dataset distribution, resulting in overly conservative policies that struggle to generalize beyond the support of the data. While model-based approaches offer a promising solution by expanding the original dataset with synthetic data generated from a learned world model, the high dimensionality, non-stationarity, and complexity of multi-agent systems make it challenging to accurately estimate the transitions and reward functions in offline MARL. Given the difficulty of directly modeling joint dynamics, we propose a local-to-global (LOGO) world model, a novel framework that leverages local predictions-which are easier to estimate-to infer global state dynamics, thus improving prediction accuracy while implicitly capturing agent-wise dependencies. Using the trained world model, we generate synthetic data to augment the original dataset, expanding the effective state-action space. To ensure reliable policy learning, we further introduce an uncertainty-aware sampling mechanism that adaptively weights synthetic data by prediction uncertainty, reducing approximation error propagation to policies. In contrast to conventional ensemble-based methods, our approach requires only an additional encoder for uncertainty estimation, significantly reducing computational overhead while maintaining accuracy. Extensive experiments across 8 scenarios against 8 baselines demonstrate that our method surpasses state-of-the-art baselines on standard offline MARL benchmarks, establishing a new model-based baseline for generalizable offline multi-agent learning.
A Generative Model Enhanced Multi-Agent Reinforcement Learning Method for Electric Vehicle Charging Navigation
Feb 27, 2025



With the widespread adoption of electric vehicles (EVs), navigating for EV drivers to select a cost-effective charging station has become an important yet challenging issue due to dynamic traffic conditions, fluctuating electricity prices, and potential competition from other EVs. The state-of-the-art deep reinforcement learning (DRL) algorithms for solving this task still require global information about all EVs at the execution stage, which not only increases communication costs but also raises privacy issues among EV drivers. To overcome these drawbacks, we introduce a novel generative model-enhanced multi-agent DRL algorithm that utilizes only the EV's local information while achieving performance comparable to these state-of-the-art algorithms. Specifically, the policy network is implemented on the EV side, and a Conditional Variational Autoencoder-Long Short Term Memory (CVAE-LSTM)-based recommendation model is developed to provide recommendation information. Furthermore, a novel future charging competition encoder is designed to effectively compress global information, enhancing training performance. The multi-gradient descent algorithm (MGDA) is also utilized to adaptively balance the weight between the two parts of the training objective, resulting in a more stable training process. Simulations are conducted based on a practical area in Xi\'an, China. Experimental results show that our proposed algorithm, which relies on local information, outperforms existing local information-based methods and achieves less than 8\% performance loss compared to global information-based methods.
Reinforcement Learning with Intrinsically Motivated Feedback Graph for Lost-sales Inventory Control
Jun 26, 2024


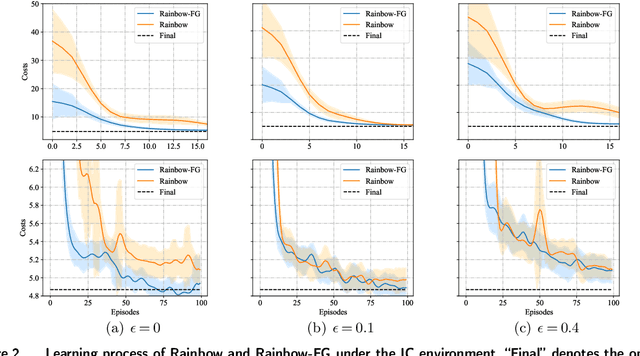
Reinforcement learning (RL) has proven to be well-performed and general-purpose in the inventory control (IC). However, further improvement of RL algorithms in the IC domain is impeded due to two limitations of online experience. First, online experience is expensive to acquire in real-world applications. With the low sample efficiency nature of RL algorithms, it would take extensive time to train the RL policy to convergence. Second, online experience may not reflect the true demand due to the lost sales phenomenon typical in IC, which makes the learning process more challenging. To address the above challenges, we propose a decision framework that combines reinforcement learning with feedback graph (RLFG) and intrinsically motivated exploration (IME) to boost sample efficiency. In particular, we first take advantage of the inherent properties of lost-sales IC problems and design the feedback graph (FG) specially for lost-sales IC problems to generate abundant side experiences aid RL updates. Then we conduct a rigorous theoretical analysis of how the designed FG reduces the sample complexity of RL methods. Based on the theoretical insights, we design an intrinsic reward to direct the RL agent to explore to the state-action space with more side experiences, further exploiting FG's power. Experimental results demonstrate that our method greatly improves the sample efficiency of applying RL in IC. Our code is available at https://anonymous.4open.science/r/RLIMFG4IC-811D/
Individual Contributions as Intrinsic Exploration Scaffolds for Multi-agent Reinforcement Learning
May 28, 2024



In multi-agent reinforcement learning (MARL), effective exploration is critical, especially in sparse reward environments. Although introducing global intrinsic rewards can foster exploration in such settings, it often complicates credit assignment among agents. To address this difficulty, we propose Individual Contributions as intrinsic Exploration Scaffolds (ICES), a novel approach to motivate exploration by assessing each agent's contribution from a global view. In particular, ICES constructs exploration scaffolds with Bayesian surprise, leveraging global transition information during centralized training. These scaffolds, used only in training, help to guide individual agents towards actions that significantly impact the global latent state transitions. Additionally, ICES separates exploration policies from exploitation policies, enabling the former to utilize privileged global information during training. Extensive experiments on cooperative benchmark tasks with sparse rewards, including Google Research Football (GRF) and StarCraft Multi-agent Challenge (SMAC), demonstrate that ICES exhibits superior exploration capabilities compared with baselines. The code is publicly available at https://github.com/LXXXXR/ICES.