 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTubiFM: Unified Item, Carousel, and Search Ranking for Streaming Discovery
May 22, 2026Personalized discovery systems often train separate models for item ranking, carousel ranking, and search, even though these tasks expose complementary signals from the same viewer journey: watches shape carousel and item ranking, search queries reveal intent even when they do not lead to a catalog match, and watch history helps interpret search as rewatching, continuation, or new discovery. We introduce the user story, a serialized representation that turns a user's cross-surface history - attributes, sessions, watch events with surface and carousel context, and search events - into a single token sequence. By interleaving pretrained language tokens with domain-specific event tokens, user stories let heterogeneous recommendation and search tasks be expressed as prompted next-token prediction over a shared grammar. TubiFM is one instantiation of this approach: a Llama 3.2 1B-based model trained on user stories and prompted to rank items, carousels, or search results without task-specific architectures. In offline evaluation, this single model outperforms specialist baselines across item, carousel, and search ranking. In online A/B tests, TubiFM significantly improves search total viewing time (TVT) by $+3.9\%$ and carousel TVT by $+0.30\%$. Item ranking is statistically neutral on TVT ($+0.14\%$), but matches a mature production stack; across all three tasks, TubiFM serves on L40S GPUs and reduces p99 ranking latency from 500ms to 200ms. These results show that shared user stories can improve discovery while simplifying ranking systems.
Inverse Reinforcement Learning Under Noisy Observations
Oct 27, 2017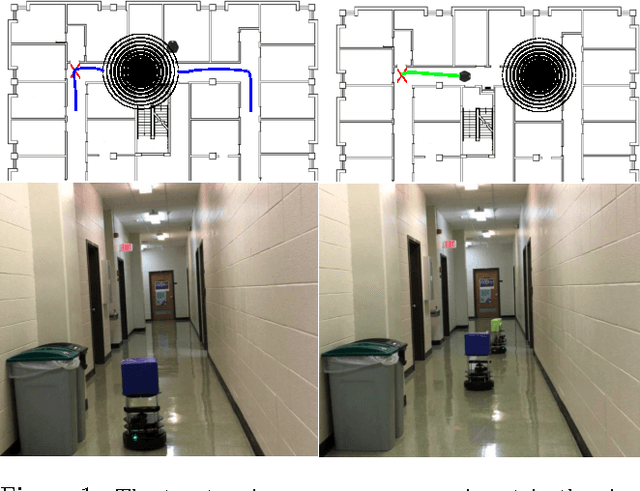
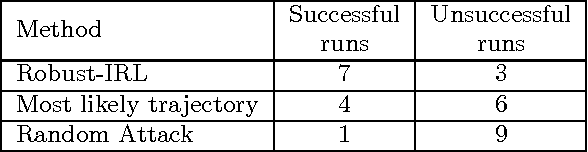
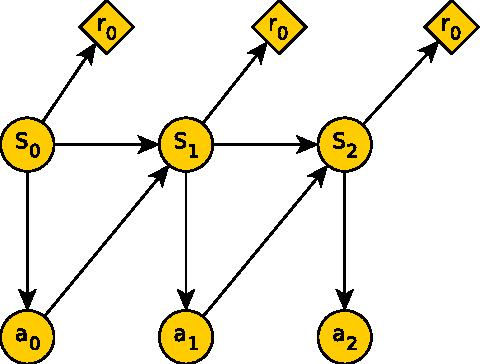
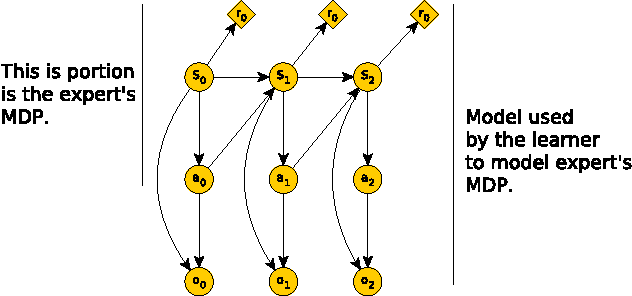
We consider the problem of performing inverse reinforcement learning when the trajectory of the expert is not perfectly observed by the learner. Instead, a noisy continuous-time observation of the trajectory is provided to the learner. This problem exhibits wide-ranging applications and the specific application we consider here is the scenario in which the learner seeks to penetrate a perimeter patrolled by a robot. The learner's field of view is limited due to which it cannot observe the patroller's complete trajectory. Instead, we allow the learner to listen to the expert's movement sound, which it can also use to estimate the expert's state and action using an observation model. We treat the expert's state and action as hidden data and present an algorithm based on expectation maximization and maximum entropy principle to solve the non-linear, non-convex problem. Related work considers discrete-time observations and an observation model that does not include actions. In contrast, our technique takes expectations over both state and action of the expert, enabling learning even in the presence of extreme noise and broader applications.
* Full version of the extended abstract published in AAMAS 2017 conference, pages 1733 - 1735