 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTubiFM: Unified Item, Carousel, and Search Ranking for Streaming Discovery
May 22, 2026Personalized discovery systems often train separate models for item ranking, carousel ranking, and search, even though these tasks expose complementary signals from the same viewer journey: watches shape carousel and item ranking, search queries reveal intent even when they do not lead to a catalog match, and watch history helps interpret search as rewatching, continuation, or new discovery. We introduce the user story, a serialized representation that turns a user's cross-surface history - attributes, sessions, watch events with surface and carousel context, and search events - into a single token sequence. By interleaving pretrained language tokens with domain-specific event tokens, user stories let heterogeneous recommendation and search tasks be expressed as prompted next-token prediction over a shared grammar. TubiFM is one instantiation of this approach: a Llama 3.2 1B-based model trained on user stories and prompted to rank items, carousels, or search results without task-specific architectures. In offline evaluation, this single model outperforms specialist baselines across item, carousel, and search ranking. In online A/B tests, TubiFM significantly improves search total viewing time (TVT) by $+3.9\%$ and carousel TVT by $+0.30\%$. Item ranking is statistically neutral on TVT ($+0.14\%$), but matches a mature production stack; across all three tasks, TubiFM serves on L40S GPUs and reduces p99 ranking latency from 500ms to 200ms. These results show that shared user stories can improve discovery while simplifying ranking systems.
Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata
Sep 15, 2023



Content metadata plays a very important role in movie recommender systems as it provides valuable information about various aspects of a movie such as genre, cast, plot synopsis, box office summary, etc. Analyzing the metadata can help understand the user preferences to generate personalized recommendations and item cold starting. In this talk, we will focus on one particular type of metadata - \textit{genre} labels. Genre labels associated with a movie or a TV series help categorize a collection of titles into different themes and correspondingly setting up the audience expectation. We present some of the challenges associated with using genre label information and propose a new way of examining the genre information that we call as the \textit{Genre Spectrum}. The Genre Spectrum helps capture the various nuanced genres in a title and our offline and online experiments corroborate the effectiveness of the approach. Furthermore, we also talk about applications of LLMs in augmenting content metadata which could eventually be used to achieve effective organization of recommendations in user's 2-D home-grid.
A Fast-Optimal Guaranteed Algorithm For Learning Sub-Interval Relationships in Time Series
Jun 03, 2019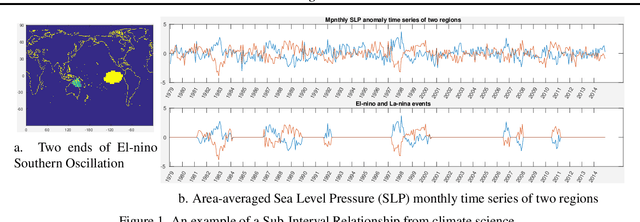
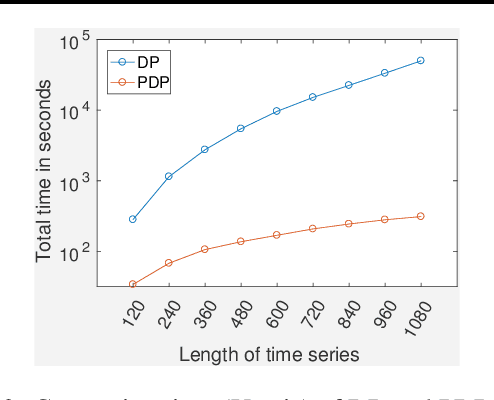
Traditional approaches focus on finding relationships between two entire time series, however, many interesting relationships exist in small sub-intervals of time and remain feeble during other sub-intervals. We define the notion of a sub-interval relationship (SIR) to capture such interactions that are prominent only in certain sub-intervals of time. To that end, we propose a fast-optimal guaranteed algorithm to find most interesting SIR relationship in a pair of time series. Lastly, we demonstrate the utility of our method in climate science domain based on a real-world dataset along with its scalability scope and obtain useful domain insights.
Mining Sub-Interval Relationships In Time Series Data
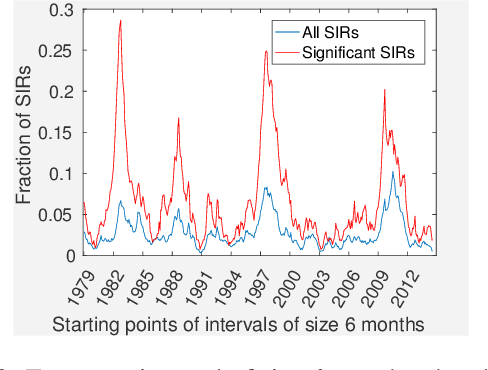
Feb 16, 2018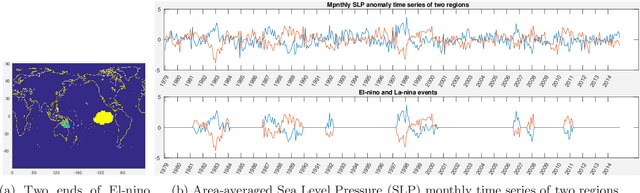
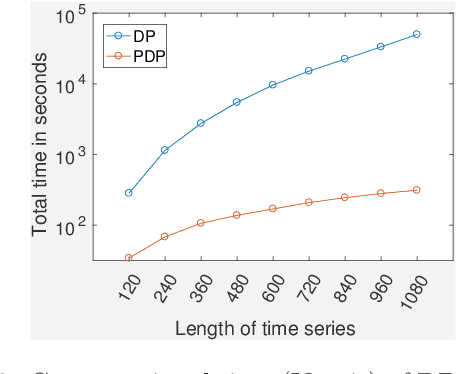
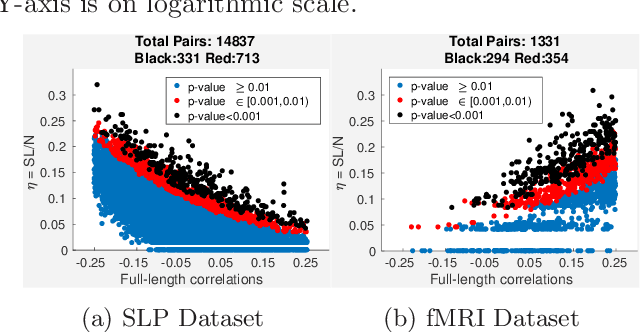

Time-series data is being increasingly collected and stud- ied in several areas such as neuroscience, climate science, transportation, and social media. Discovery of complex patterns of relationships between individual time-series, using data-driven approaches can improve our understanding of real-world systems. While traditional approaches typically study relationships between two entire time series, many interesting relationships in real-world applications exist in small sub-intervals of time while remaining absent or feeble during other sub-intervals. In this paper, we define the notion of a sub-interval relationship (SIR) to capture inter- actions between two time series that are prominent only in certain sub-intervals of time. We propose a novel and efficient approach to find most interesting SIR in a pair of time series. We evaluate our proposed approach on two real-world datasets from climate science and neuroscience domain and demonstrated the scalability and computational efficiency of our proposed approach. We further evaluated our discovered SIRs based on a randomization based procedure. Our results indicated the existence of several such relationships that are statistically significant, some of which were also found to have physical interpretation.