 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Text Classification: A Comprehensive Review
Apr 06, 2020
Deep learning based models have surpassed classical machine learning based approaches in various text classification tasks, including sentiment analysis, news categorization, question answering, and natural language inference. In this work, we provide a detailed review of more than 150 deep learning based models for text classification developed in recent years, and discuss their technical contributions, similarities, and strengths. We also provide a summary of more than 40 popular datasets widely used for text classification. Finally, we provide a quantitative analysis of the performance of different deep learning models on popular benchmarks, and discuss future research directions.
Palm-GAN: Generating Realistic Palmprint Images Using Total-Variation Regularized GAN
Mar 21, 2020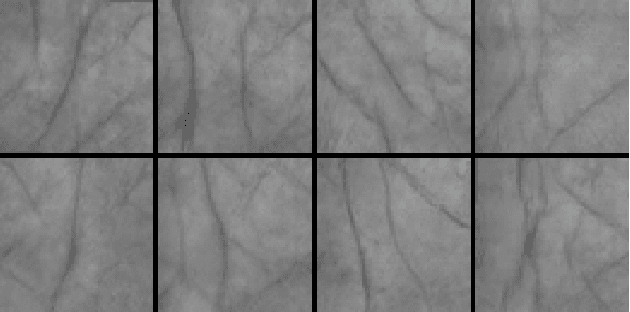
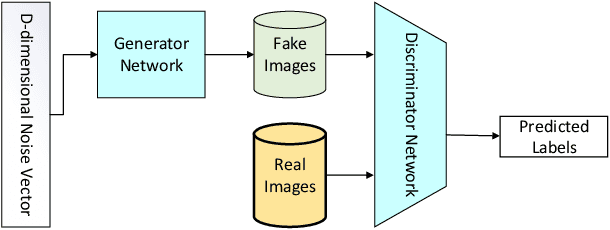
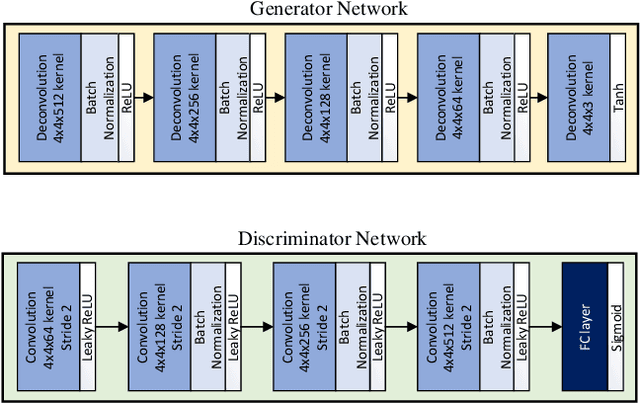
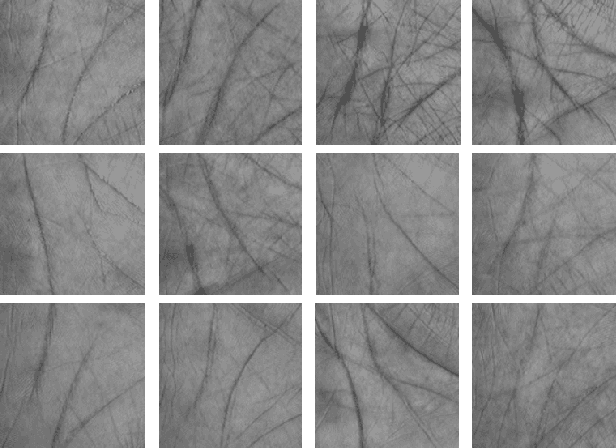
Generating realistic palmprint (more generally biometric) images has always been an interesting and, at the same time, challenging problem. Classical statistical models fail to generate realistic-looking palmprint images, as they are not powerful enough to capture the complicated texture representation of palmprint images. In this work, we present a deep learning framework based on generative adversarial networks (GAN), which is able to generate realistic palmprint images. To help the model learn more realistic images, we proposed to add a suitable regularization to the loss function, which imposes the line connectivity of generated palmprint images. This is very desirable for palmprints, as the principal lines in palm are usually connected. We apply this framework to a popular palmprint databases, and generate images which look very realistic, and similar to the samples in this database. Through experimental results, we show that the generated palmprint images look very realistic, have a good diversity, and are able to capture different parts of the prior distribution. We also report the Frechet Inception distance (FID) of the proposed model, and show that our model is able to achieve really good quantitative performance in terms of FID score.
Regularized Submodular Maximization at Scale
Feb 10, 2020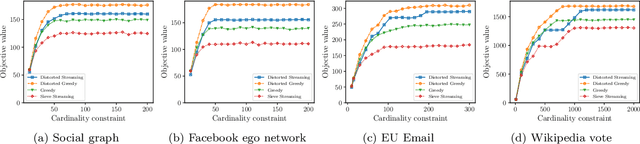
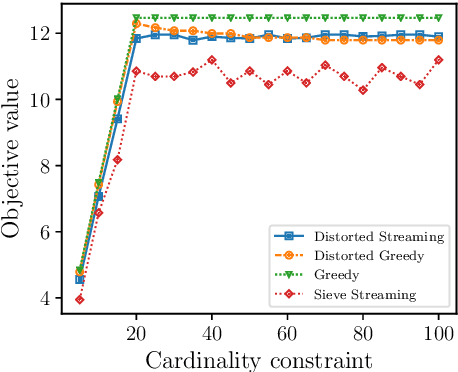
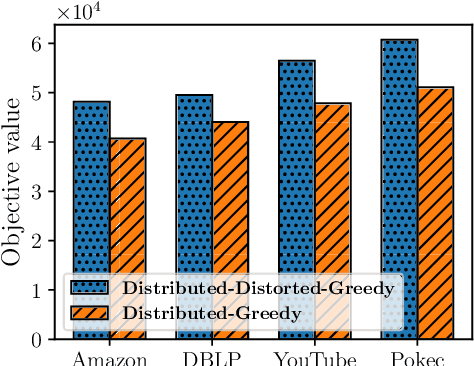
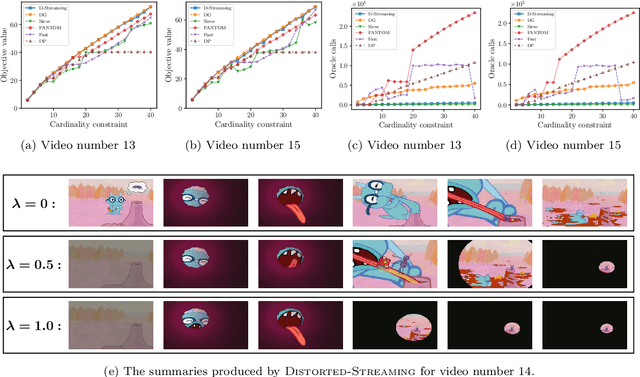
In this paper, we propose scalable methods for maximizing a regularized submodular function $f = g - \ell$ expressed as the difference between a monotone submodular function $g$ and a modular function $\ell$. Indeed, submodularity is inherently related to the notions of diversity, coverage, and representativeness. In particular, finding the mode of many popular probabilistic models of diversity, such as determinantal point processes, submodular probabilistic models, and strongly log-concave distributions, involves maximization of (regularized) submodular functions. Since a regularized function $f$ can potentially take on negative values, the classic theory of submodular maximization, which heavily relies on the non-negativity assumption of submodular functions, may not be applicable. To circumvent this challenge, we develop the first one-pass streaming algorithm for maximizing a regularized submodular function subject to a $k$-cardinality constraint. It returns a solution $S$ with the guarantee that $f(S)\geq(\phi^{-2}-\epsilon) \cdot g(OPT)-\ell (OPT)$, where $\phi$ is the golden ratio. Furthermore, we develop the first distributed algorithm that returns a solution $S$ with the guarantee that $\mathbb{E}[f(S)] \geq (1-\epsilon) [(1-e^{-1}) \cdot g(OPT)-\ell(OPT)]$ in $O(1/ \epsilon)$ rounds of MapReduce computation, without keeping multiple copies of the entire dataset in each round (as it is usually done). We should highlight that our result, even for the unregularized case where the modular term $\ell$ is zero, improves the memory and communication complexity of the existing work by a factor of $O(1/ \epsilon)$ while arguably provides a simpler distributed algorithm and a unifying analysis. We also empirically study the performance of our scalable methods on a set of real-life applications, including finding the mode of distributions, data summarization, and product recommendation.
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
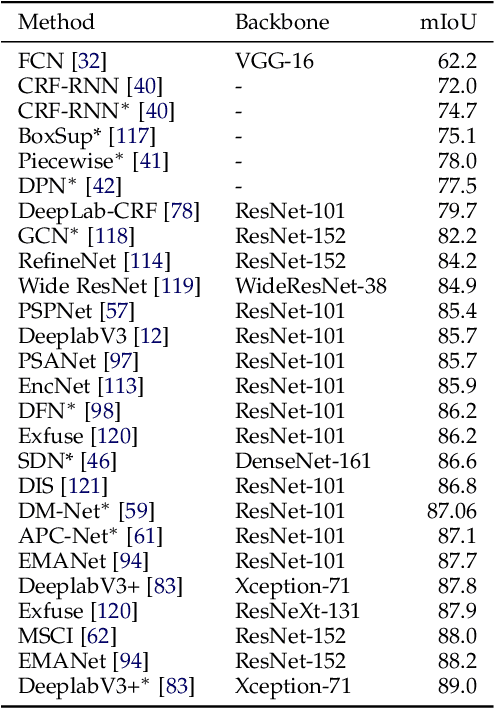
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
Biometric Recognition Using Deep Learning: A Survey
Nov 30, 2019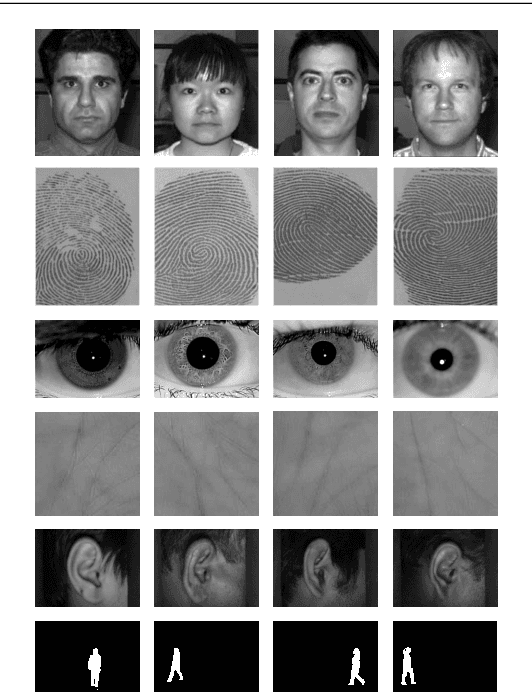
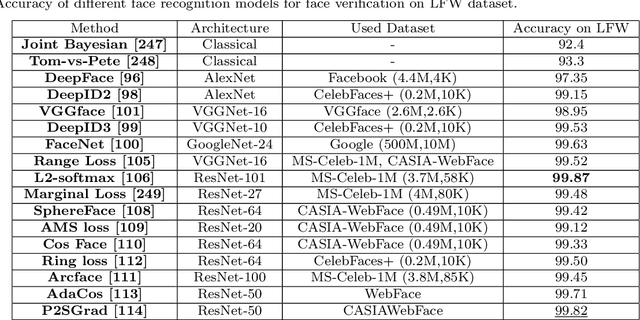
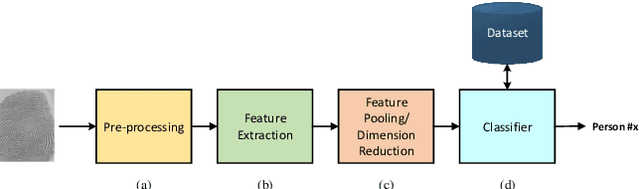
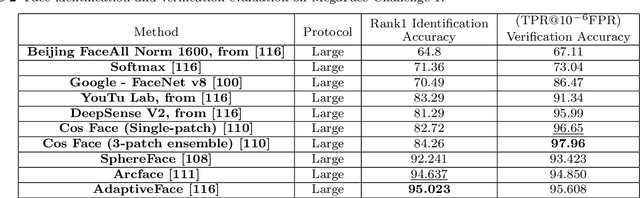
Deep learning-based models have been very successful in achieving state-of-the-art results in many of the computer vision, speech recognition, and natural language processing tasks in the last few years. These models seem a natural fit for handling the ever-increasing scale of biometric recognition problems, from cellphone authentication to airport security systems. Deep learning-based models have increasingly been leveraged to improve the accuracy of different biometric recognition systems in recent years. In this work, we provide a comprehensive survey of more than 120 promising works on biometric recognition (including face, fingerprint, iris, palmprint, ear, voice, signature, and gait recognition), which deploy deep learning models, and show their strengths and potentials in different applications. For each biometric, we first introduce the available datasets that are widely used in the literature and their characteristics. We will then talk about several promising deep learning works developed for that biometric, and show their performance on popular public benchmarks. We will also discuss some of the main challenges while using these models for biometric recognition, and possible future directions to which research in this area is headed.
Hotel2vec: Learning Attribute-Aware Hotel Embeddings with Self-Supervision
Sep 30, 2019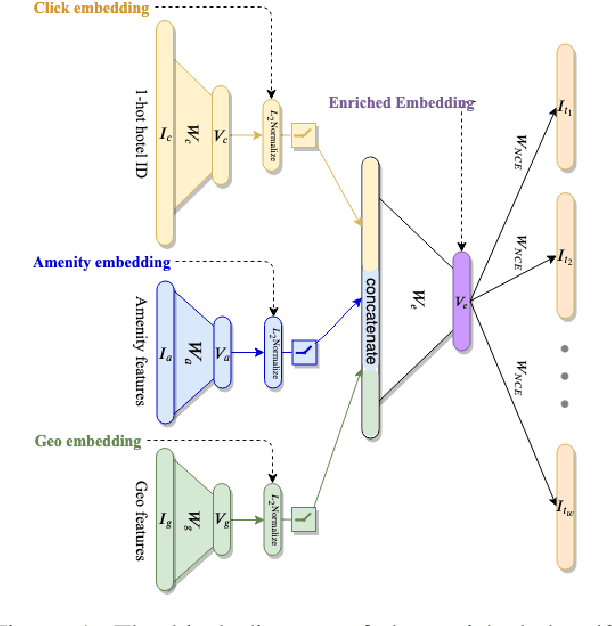
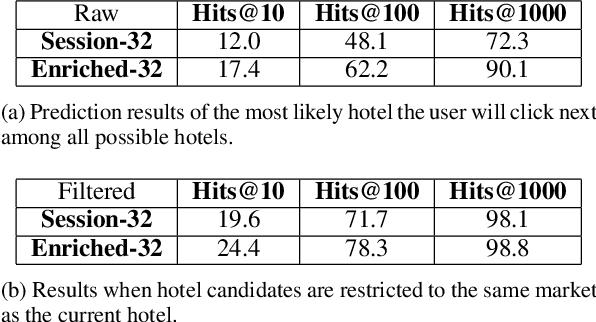

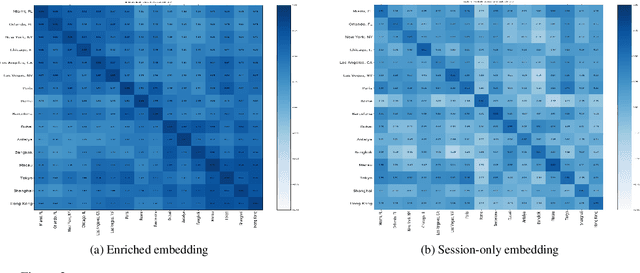
We propose a neural network architecture for learning vector representations of hotels. Unlike previous works, which typically only use user click information for learning item embeddings, we propose a framework that combines several sources of data, including user clicks, hotel attributes (e.g., property type, star rating, average user rating), amenity information (e.g., the hotel has free Wi-Fi or free breakfast), and geographic information. During model training, a joint embedding is learned from all of the above information. We show that including structured attributes about hotels enables us to make better predictions in a downstream task than when we rely exclusively on click data. We train our embedding model on more than 40 million user click sessions from a leading online travel platform and learn embeddings for more than one million hotels. Our final learned embeddings integrate distinct sub-embeddings for user clicks, hotel attributes, and geographic information, providing an interpretable representation that can be used flexibly depending on the application. We show empirically that our model generates high-quality representations that boost the performance of a hotel recommendation system in addition to other applications. An important advantage of the proposed neural model is that it addresses the cold-start problem for hotels with insufficient historical click information by incorporating additional hotel attributes which are available for all hotels.
Masked-RPCA: Sparse and Low-rank Decomposition Under Overlaying Model and Application to Moving Object Detection
Sep 17, 2019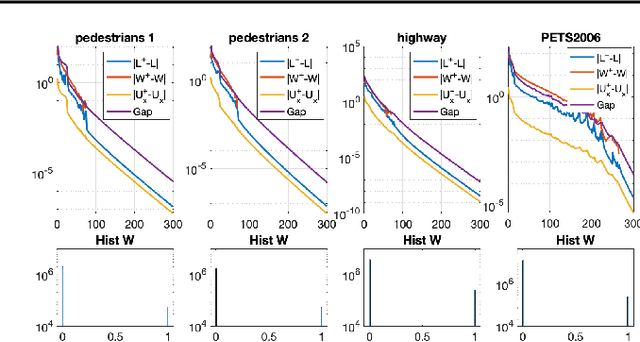
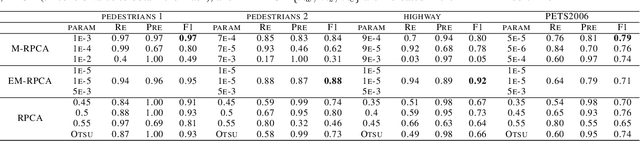

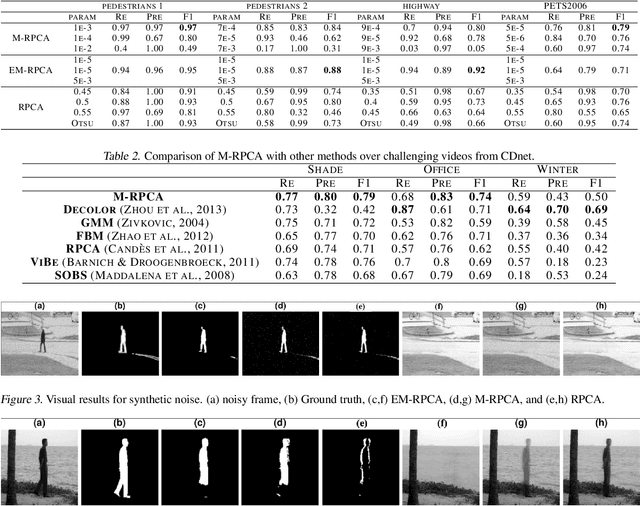
Foreground detection in a given video sequence is a pivotal step in many computer vision applications such as video surveillance system. Robust Principal Component Analysis (RPCA) performs low-rank and sparse decomposition and accomplishes such a task when the background is stationary and the foreground is dynamic and relatively small. A fundamental issue with RPCA is the assumption that the low-rank and sparse components are added at each element, whereas in reality, the moving foreground is overlaid on the background. We propose the representation via masked decomposition (i.e. an overlaying model) where each element either belongs to the low-rank or the sparse component, decided by a mask. We propose the Masked-RPCA algorithm to recover the mask and the low-rank components simultaneously, utilizing linearizing and alternating direction techniques. We further extend our formulation to be robust to dynamic changes in the background and enforce spatial connectivity in the foreground component. Our study shows significant improvement of the detected mask compared to post-processing on the sparse component obtained by other frameworks.
FingerNet: Pushing The Limits of Fingerprint Recognition Using Convolutional Neural Network
Jul 28, 2019
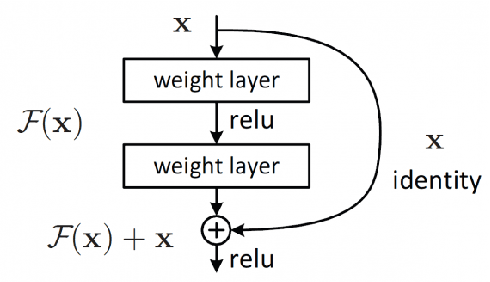


Fingerprint recognition has been utilized for cellphone authentication, airport security and beyond. Many different features and algorithms have been proposed to improve fingerprint recognition. In this paper, we propose an end-to-end deep learning framework for fingerprint recognition using convolutional neural networks (CNNs) which can jointly learn the feature representation and perform recognition. We train our model on a large-scale fingerprint recognition dataset, and improve over previous approaches in terms of accuracy. Our proposed model is able to achieve a very high recognition accuracy on a well-known fingerprint dataset. We believe this framework can be widely used for biometrics recognition tasks, making more scalable and accurate systems possible. We have also used a visualization technique to highlight the important areas in an input fingerprint image, that mostly impact the recognition results.
DeepIris: Iris Recognition Using A Deep Learning Approach
Jul 22, 2019
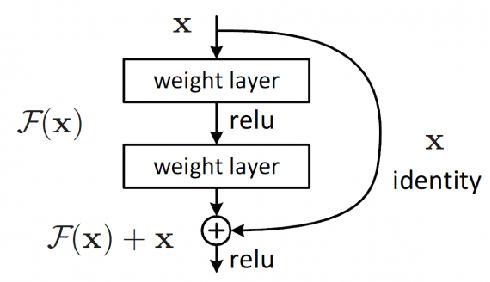

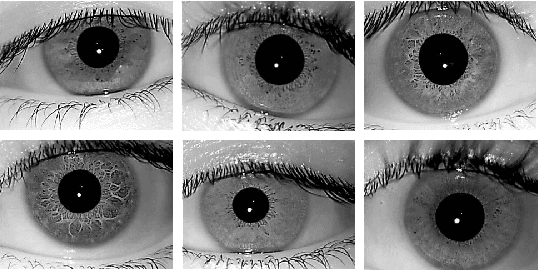
Iris recognition has been an active research area during last few decades, because of its wide applications in security, from airports to homeland security border control. Different features and algorithms have been proposed for iris recognition in the past. In this paper, we propose an end-to-end deep learning framework for iris recognition based on residual convolutional neural network (CNN), which can jointly learn the feature representation and perform recognition. We train our model on a well-known iris recognition dataset using only a few training images from each class, and show promising results and improvements over previous approaches. We also present a visualization technique which is able to detect the important areas in iris images which can mostly impact the recognition results. We believe this framework can be widely used for other biometrics recognition tasks, helping to have a more scalable and accurate systems.
Deep-Sentiment: Sentiment Analysis Using Ensemble of CNN and Bi-LSTM Models
Apr 08, 2019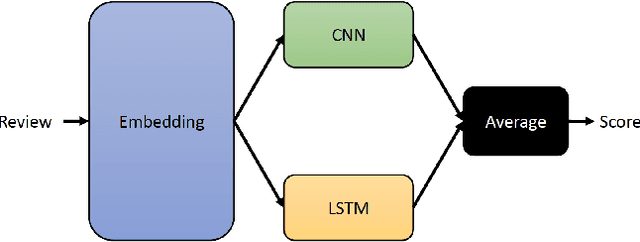
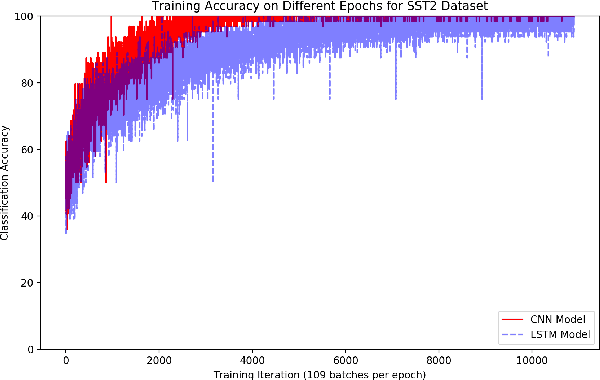
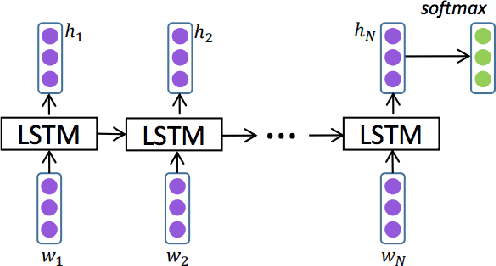
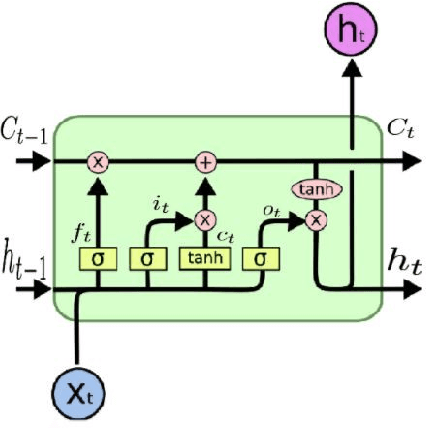
With the popularity of social networks, and e-commerce websites, sentiment analysis has become a more active area of research in the past few years. On a high level, sentiment analysis tries to understand the public opinion about a specific product or topic, or trends from reviews or tweets. Sentiment analysis plays an important role in better understanding customer/user opinion, and also extracting social/political trends. There has been a lot of previous works for sentiment analysis, some based on hand-engineering relevant textual features, and others based on different neural network architectures. In this work, we present a model based on an ensemble of long-short-term-memory (LSTM), and convolutional neural network (CNN), one to capture the temporal information of the data, and the other one to extract the local structure thereof. Through experimental results, we show that using this ensemble model we can outperform both individual models. We are also able to achieve a very high accuracy rate compared to the previous works.