 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropagating Sparse Depth via Depth Foundation Model for Out-of-Distribution Depth Completion
Aug 07, 2025



Depth completion is a pivotal challenge in computer vision, aiming at reconstructing the dense depth map from a sparse one, typically with a paired RGB image. Existing learning based models rely on carefully prepared but limited data, leading to significant performance degradation in out-of-distribution (OOD) scenarios. Recent foundation models have demonstrated exceptional robustness in monocular depth estimation through large-scale training, and using such models to enhance the robustness of depth completion models is a promising solution. In this work, we propose a novel depth completion framework that leverages depth foundation models to attain remarkable robustness without large-scale training. Specifically, we leverage a depth foundation model to extract environmental cues, including structural and semantic context, from RGB images to guide the propagation of sparse depth information into missing regions. We further design a dual-space propagation approach, without any learnable parameters, to effectively propagates sparse depth in both 3D and 2D spaces to maintain geometric structure and local consistency. To refine the intricate structure, we introduce a learnable correction module to progressively adjust the depth prediction towards the real depth. We train our model on the NYUv2 and KITTI datasets as in-distribution datasets and extensively evaluate the framework on 16 other datasets. Our framework performs remarkably well in the OOD scenarios and outperforms existing state-of-the-art depth completion methods. Our models are released in https://github.com/shenglunch/PSD.
Full Matching on Low Resolution for Disparity Estimation
Dec 10, 2020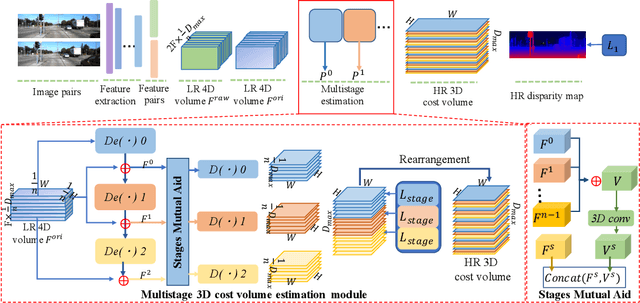
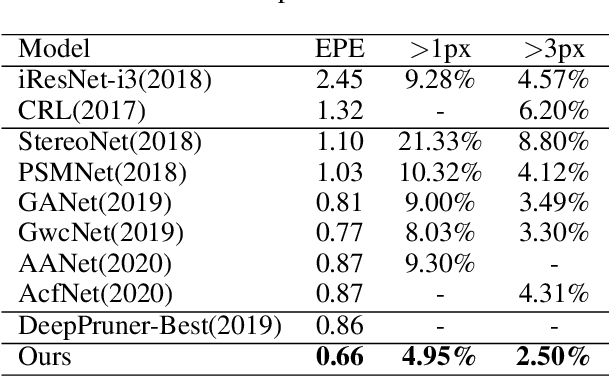
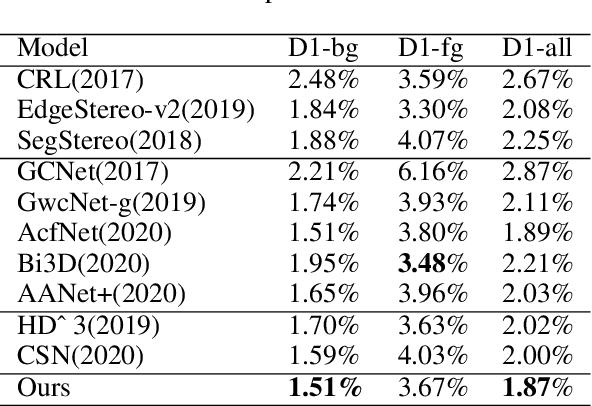

A Multistage Full Matching disparity estimation scheme (MFM) is proposed in this work. We demonstrate that decouple all similarity scores directly from the low-resolution 4D volume step by step instead of estimating low-resolution 3D cost volume through focusing on optimizing the low-resolution 4D volume iteratively leads to more accurate disparity. To this end, we first propose to decompose the full matching task into multiple stages of the cost aggregation module. Specifically, we decompose the high-resolution predicted results into multiple groups, and every stage of the newly designed cost aggregation module learns only to estimate the results for a group of points. This alleviates the problem of feature internal competitive when learning similarity scores of all candidates from one low-resolution 4D volume output from one stage. Then, we propose the strategy of \emph{Stages Mutual Aid}, which takes advantage of the relationship of multiple stages to boost similarity scores estimation of each stage, to solve the unbalanced prediction of multiple stages caused by serial multistage framework. Experiment results demonstrate that the proposed method achieves more accurate disparity estimation results and outperforms state-of-the-art methods on Scene Flow, KITTI 2012 and KITTI 2015 datasets.
Direct Depth Learning Network for Stereo Matching
Dec 10, 2020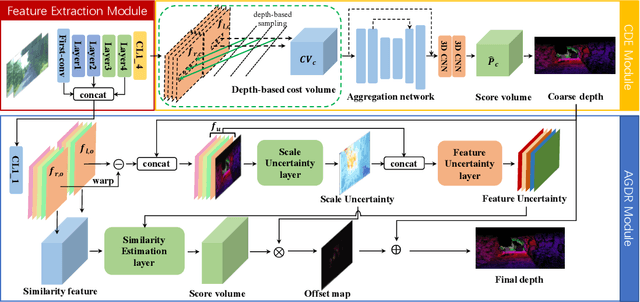
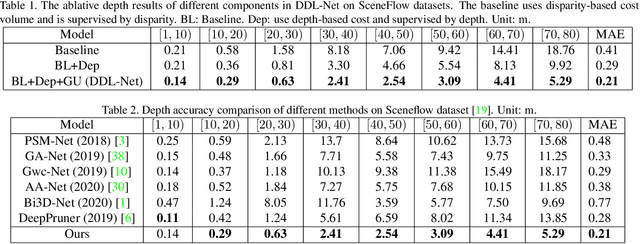
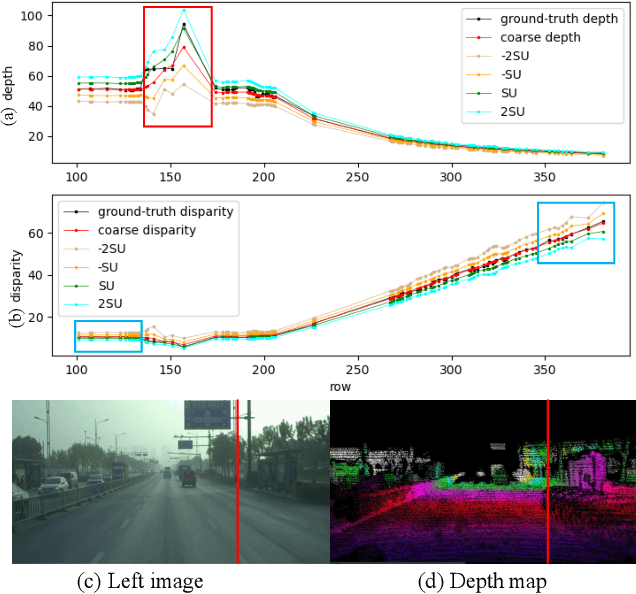
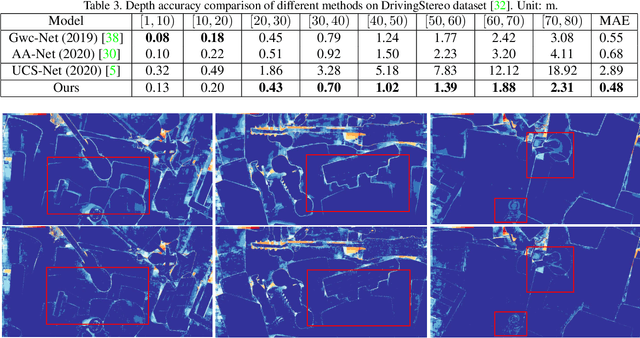
Being a crucial task of autonomous driving, Stereo matching has made great progress in recent years. Existing stereo matching methods estimate disparity instead of depth. They treat the disparity errors as the evaluation metric of the depth estimation errors, since the depth can be calculated from the disparity according to the triangulation principle. However, we find that the error of the depth depends not only on the error of the disparity but also on the depth range of the points. Therefore, even if the disparity error is low, the depth error is still large, especially for the distant points. In this paper, a novel Direct Depth Learning Network (DDL-Net) is designed for stereo matching. DDL-Net consists of two stages: the Coarse Depth Estimation stage and the Adaptive-Grained Depth Refinement stage, which are all supervised by depth instead of disparity. Specifically, Coarse Depth Estimation stage uniformly samples the matching candidates according to depth range to construct cost volume and output coarse depth. Adaptive-Grained Depth Refinement stage performs further matching near the coarse depth to correct the imprecise matching and wrong matching. To make the Adaptive-Grained Depth Refinement stage robust to the coarse depth and adaptive to the depth range of the points, the Granularity Uncertainty is introduced to Adaptive-Grained Depth Refinement stage. Granularity Uncertainty adjusts the matching range and selects the candidates' features according to coarse prediction confidence and depth range. We verify the performance of DDL-Net on SceneFlow dataset and DrivingStereo dataset by different depth metrics. Results show that DDL-Net achieves an average improvement of 25% on the SceneFlow dataset and $12\%$ on the DrivingStereo dataset comparing the classical methods. More importantly, we achieve state-of-the-art accuracy at a large distance.