 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Recommendation in the Era of Large Language Models: Opportunities and Challenges
May 30, 2026The field of recommender systems (RS) is currently undergoing two profound paradigm shifts. From the perspective of objectives, the goal has shifted beyond mere recommendation accuracy to comprehensive trustworthiness, encompassing multiple dimensions such as robustness, fairness, and privacy preservation. From a technical perspective, Large Language Models (LLMs) have been extensively integrated into RS, reshaping the foundations of recommendation through richer semantic understanding, stronger intent reasoning, and more flexible user interactions. The convergence of these two shifts prompts a timely and pivotal question: how does the integration of LLMs reshape the landscape of trustworthy recommendation? In this work, we present a systematic review of trustworthy LLM-empowered recommendation. By comprehensively analyzing over 200 recent studies, we reveal that the introduction of LLMs acts as a double-edged sword. While their advanced mechanisms and user-friendly interfaces offer unprecedented opportunities to enhance trustworthiness, they simultaneously introduce new risks, such as novel forms of bias and hallucination-induced issues. To characterize this dual impact, we systematically identify 13 opportunities and 18 challenges across six fundamental dimensions of trustworthiness, and accordingly organize the existing literature into a novel taxonomy. We also provide a comprehensive review of commonly used datasets and evaluation metrics to facilitate empirical validation. Finally, we identify critical open challenges and outline future directions, hoping to inspire future research on this emerging topic.
BEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models
Jan 30, 2026Recent years have witnessed a rapid surge in research leveraging Large Language Models (LLMs) for recommendation. These methods typically employ supervised fine-tuning (SFT) to adapt LLMs to recommendation scenarios, and utilize beam search during inference to efficiently retrieve $B$ top-ranked recommended items. However, we identify a critical training-inference inconsistency: while SFT optimizes the overall probability of positive items, it does not guarantee that such items will be retrieved by beam search even if they possess high overall probabilities. Due to the greedy pruning mechanism, beam search can prematurely discard a positive item once its prefix probability is insufficient. To address this inconsistency, we propose BEAR (Beam-SEarch-Aware Regularization), a novel fine-tuning objective that explicitly accounts for beam search behavior during training. Rather than directly simulating beam search for each instance during training, which is computationally prohibitive, BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-$B$ candidate tokens at each decoding step. This objective effectively mitigates the risk of incorrect pruning while incurring negligible computational overhead compared to standard SFT. Extensive experiments across four real-world datasets demonstrate that BEAR significantly outperforms strong baselines. Code will be released upon acceptance.
Talos: Optimizing Top-$K$ Accuracy in Recommender Systems
Jan 27, 2026Recommender systems (RS) aim to retrieve a small set of items that best match individual user preferences. Naturally, RS place primary emphasis on the quality of the Top-$K$ results rather than performance across the entire item set. However, estimating Top-$K$ accuracy (e.g., Precision@$K$, Recall@$K$) requires determining the ranking positions of items, which imposes substantial computational overhead and poses significant challenges for optimization. In addition, RS often suffer from distribution shifts due to evolving user preferences or data biases, further complicating the task. To address these issues, we propose Talos, a loss function that is specifically designed to optimize the Talos recommendation accuracy. Talos leverages a quantile technique that replaces the complex ranking-dependent operations into simpler comparisons between predicted scores and learned score thresholds. We further develop a sampling-based regression algorithm for efficient and accurate threshold estimation, and introduce a constraint term to maintain optimization stability by preventing score inflation. Additionally, we incorporate a tailored surrogate function to address discontinuity and enhance robustness against distribution shifts. Comprehensive theoretical analyzes and empirical experiments are conducted to demonstrate the effectiveness, efficiency, convergence, and distributional robustness of Talos. The code is available at https://github.com/cynthia-shengjia/WWW-2026-Talos.
Advancing Loss Functions in Recommender Systems: A Comparative Study with a Rényi Divergence-Based Solution
Jun 18, 2025Loss functions play a pivotal role in optimizing recommendation models. Among various loss functions, Softmax Loss (SL) and Cosine Contrastive Loss (CCL) are particularly effective. Their theoretical connections and differences warrant in-depth exploration. This work conducts comprehensive analyses of these losses, yielding significant insights: 1) Common strengths -- both can be viewed as augmentations of traditional losses with Distributional Robust Optimization (DRO), enhancing robustness to distributional shifts; 2) Respective limitations -- stemming from their use of different distribution distance metrics in DRO optimization, SL exhibits high sensitivity to false negative instances, whereas CCL suffers from low data utilization. To address these limitations, this work proposes a new loss function, DrRL, which generalizes SL and CCL by leveraging R\'enyi-divergence in DRO optimization. DrRL incorporates the advantageous structures of both SL and CCL, and can be demonstrated to effectively mitigate their limitations. Extensive experiments have been conducted to validate the superiority of DrRL on both recommendation accuracy and robustness.
Boosting Unsupervised Domain Adaptation with Soft Pseudo-label and Curriculum Learning
Dec 03, 2021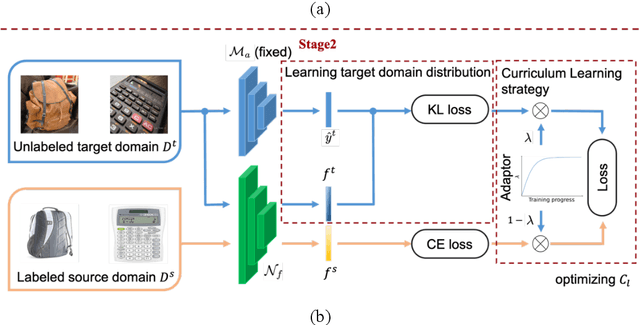
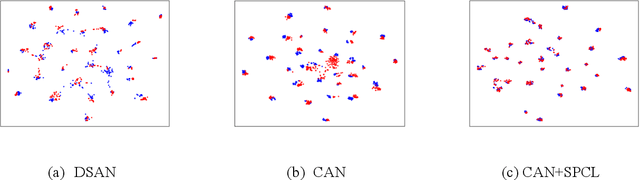
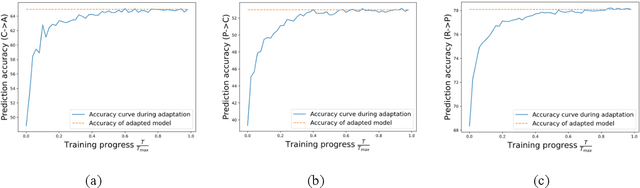
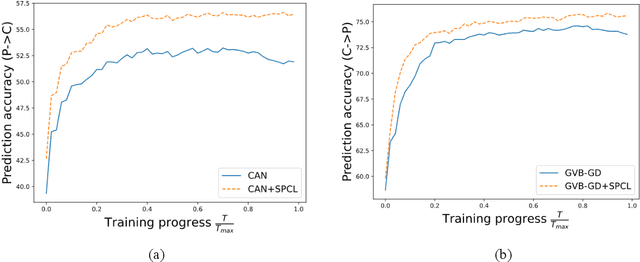
By leveraging data from a fully labeled source domain, unsupervised domain adaptation (UDA) improves classification performance on an unlabeled target domain through explicit discrepancy minimization of data distribution or adversarial learning. As an enhancement, category alignment is involved during adaptation to reinforce target feature discrimination by utilizing model prediction. However, there remain unexplored problems about pseudo-label inaccuracy incurred by wrong category predictions on target domain, and distribution deviation caused by overfitting on source domain. In this paper, we propose a model-agnostic two-stage learning framework, which greatly reduces flawed model predictions using soft pseudo-label strategy and avoids overfitting on source domain with a curriculum learning strategy. Theoretically, it successfully decreases the combined risk in the upper bound of expected error on the target domain. At the first stage, we train a model with distribution alignment-based UDA method to obtain soft semantic label on target domain with rather high confidence. To avoid overfitting on source domain, at the second stage, we propose a curriculum learning strategy to adaptively control the weighting between losses from the two domains so that the focus of the training stage is gradually shifted from source distribution to target distribution with prediction confidence boosted on the target domain. Extensive experiments on two well-known benchmark datasets validate the universal effectiveness of our proposed framework on promoting the performance of the top-ranked UDA algorithms and demonstrate its consistent superior performance.