 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Mar 12, 2026We introduce $Ψ_0$ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, \ours\;decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: First, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations. Then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that \ours\ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10$\times$ as much data by over 40\% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.
Failure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Jan 12, 2026Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.
Attention over Self-attention:Intention-aware Re-ranking with Dynamic Transformer Encoders for Recommendation
Jan 14, 2022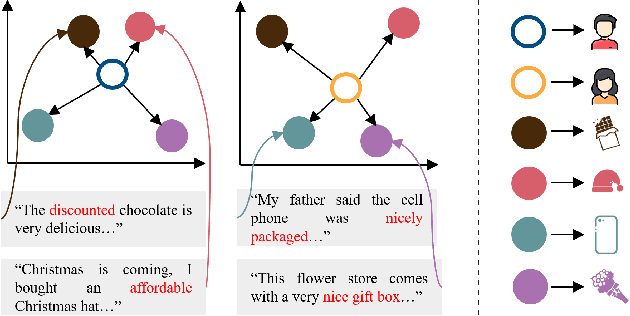
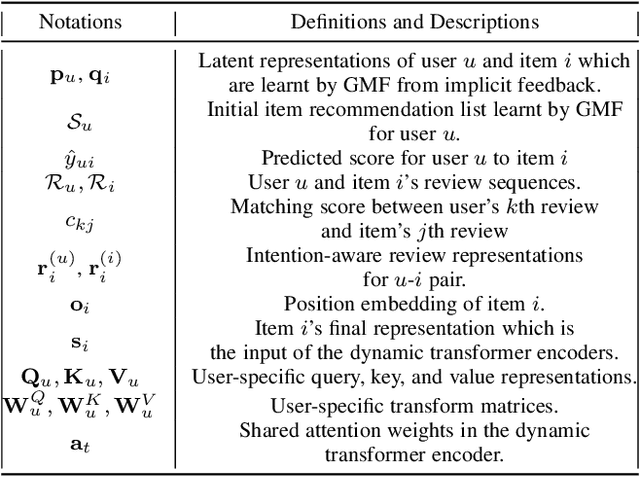
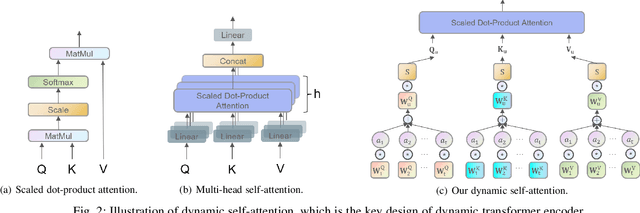
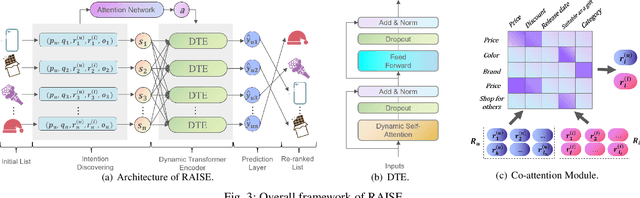
Re-ranking models refine the item recommendation list generated by the prior global ranking model with intra-item relationships. However, most existing re-ranking solutions refine recommendation list based on the implicit feedback with a shared re-ranking model, which regrettably ignore the intra-item relationships under diverse user intentions. In this paper, we propose a novel Intention-aware Re-ranking Model with Dynamic Transformer Encoder (RAISE), aiming to perform user-specific prediction for each target user based on her intentions. Specifically, we first propose to mine latent user intentions from text reviews with an intention discovering module (IDM). By differentiating the importance of review information with a co-attention network, the latent user intention can be explicitly modeled for each user-item pair. We then introduce a dynamic transformer encoder (DTE) to capture user-specific intra-item relationships among item candidates by seamlessly accommodating the learnt latent user intentions via IDM. As such, RAISE is able to perform user-specific prediction without increasing the depth (number of blocks) and width (number of heads) of the prediction model. Empirical study on four public datasets shows the superiority of our proposed RAISE, with up to 13.95%, 12.30%, and 13.03% relative improvements evaluated by Precision, MAP, and NDCG respectively.