 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability-aware Prompt Reformulation Learning for Text-to-Image Generation
Mar 27, 2024Text-to-image generation systems have emerged as revolutionary tools in the realm of artistic creation, offering unprecedented ease in transforming textual prompts into visual art. However, the efficacy of these systems is intricately linked to the quality of user-provided prompts, which often poses a challenge to users unfamiliar with prompt crafting. This paper addresses this challenge by leveraging user reformulation data from interaction logs to develop an automatic prompt reformulation model. Our in-depth analysis of these logs reveals that user prompt reformulation is heavily dependent on the individual user's capability, resulting in significant variance in the quality of reformulation pairs. To effectively use this data for training, we introduce the Capability-aware Prompt Reformulation (CAPR) framework. CAPR innovatively integrates user capability into the reformulation process through two key components: the Conditional Reformulation Model (CRM) and Configurable Capability Features (CCF). CRM reformulates prompts according to a specified user capability, as represented by CCF. The CCF, in turn, offers the flexibility to tune and guide the CRM's behavior. This enables CAPR to effectively learn diverse reformulation strategies across various user capacities and to simulate high-capability user reformulation during inference. Extensive experiments on standard text-to-image generation benchmarks showcase CAPR's superior performance over existing baselines and its remarkable robustness on unseen systems. Furthermore, comprehensive analyses validate the effectiveness of different components. CAPR can facilitate user-friendly interaction with text-to-image systems and make advanced artistic creation more achievable for a broader range of users.
Evaluation Ethics of LLMs in Legal Domain
Mar 17, 2024



In recent years, the utilization of large language models for natural language dialogue has gained momentum, leading to their widespread adoption across various domains. However, their universal competence in addressing challenges specific to specialized fields such as law remains a subject of scrutiny. The incorporation of legal ethics into the model has been overlooked by researchers. We asserts that rigorous ethic evaluation is essential to ensure the effective integration of large language models in legal domains, emphasizing the need to assess domain-specific proficiency and domain-specific ethic. To address this, we propose a novelty evaluation methodology, utilizing authentic legal cases to evaluate the fundamental language abilities, specialized legal knowledge and legal robustness of large language models (LLMs). The findings from our comprehensive evaluation contribute significantly to the academic discourse surrounding the suitability and performance of large language models in legal domains.
Intersectional Two-sided Fairness in Recommendation
Feb 15, 2024



Fairness of recommender systems (RS) has attracted increasing attention recently. Based on the involved stakeholders, the fairness of RS can be divided into user fairness, item fairness, and two-sided fairness which considers both user and item fairness simultaneously. However, we argue that the intersectional two-sided unfairness may still exist even if the RS is two-sided fair, which is observed and shown by empirical studies on real-world data in this paper, and has not been well-studied previously. To mitigate this problem, we propose a novel approach called Intersectional Two-sided Fairness Recommendation (ITFR). Our method utilizes a sharpness-aware loss to perceive disadvantaged groups, and then uses collaborative loss balance to develop consistent distinguishing abilities for different intersectional groups. Additionally, predicted score normalization is leveraged to align positive predicted scores to fairly treat positives in different intersectional groups. Extensive experiments and analyses on three public datasets show that our proposed approach effectively alleviates the intersectional two-sided unfairness and consistently outperforms previous state-of-the-art methods.
Aligning the Capabilities of Large Language Models with the Context of Information Retrieval via Contrastive Feedback
Sep 29, 2023



Information Retrieval (IR), the process of finding information to satisfy user's information needs, plays an essential role in modern people's lives. Recently, large language models (LLMs) have demonstrated remarkable capabilities across various tasks, some of which are important for IR. Nonetheless, LLMs frequently confront the issue of generating responses that lack specificity. This has limited the overall effectiveness of LLMs for IR in many cases. To address these issues, we present an unsupervised alignment framework called Reinforcement Learning from Contrastive Feedback (RLCF), which empowers LLMs to generate both high-quality and context-specific responses that suit the needs of IR tasks. Specifically, we construct contrastive feedback by comparing each document with its similar documents, and then propose a reward function named Batched-MRR to teach LLMs to generate responses that captures the fine-grained information that distinguish documents from their similar ones. To demonstrate the effectiveness of RLCF, we conducted experiments in two typical applications of LLMs in IR, i.e., data augmentation and summarization. The experimental results show that RLCF can effectively improve the performance of LLMs in IR context.
An Intent Taxonomy of Legal Case Retrieval
Jul 25, 2023



Legal case retrieval is a special Information Retrieval~(IR) task focusing on legal case documents. Depending on the downstream tasks of the retrieved case documents, users' information needs in legal case retrieval could be significantly different from those in Web search and traditional ad-hoc retrieval tasks. While there are several studies that retrieve legal cases based on text similarity, the underlying search intents of legal retrieval users, as shown in this paper, are more complicated than that yet mostly unexplored. To this end, we present a novel hierarchical intent taxonomy of legal case retrieval. It consists of five intent types categorized by three criteria, i.e., search for Particular Case(s), Characterization, Penalty, Procedure, and Interest. The taxonomy was constructed transparently and evaluated extensively through interviews, editorial user studies, and query log analysis. Through a laboratory user study, we reveal significant differences in user behavior and satisfaction under different search intents in legal case retrieval. Furthermore, we apply the proposed taxonomy to various downstream legal retrieval tasks, e.g., result ranking and satisfaction prediction, and demonstrate its effectiveness. Our work provides important insights into the understanding of user intents in legal case retrieval and potentially leads to better retrieval techniques in the legal domain, such as intent-aware ranking strategies and evaluation methodologies.
Unbiased Delayed Feedback Label Correction for Conversion Rate Prediction
Jul 24, 2023



Conversion rate prediction is critical to many online applications such as digital display advertising. To capture dynamic data distribution, industrial systems often require retraining models on recent data daily or weekly. However, the delay of conversion behavior usually leads to incorrect labeling, which is called delayed feedback problem. Existing work may fail to introduce the correct information about false negative samples due to data sparsity and dynamic data distribution. To directly introduce the correct feedback label information, we propose an Unbiased delayed feedback Label Correction framework (ULC), which uses an auxiliary model to correct labels for observed negative feedback samples. Firstly, we theoretically prove that the label-corrected loss is an unbiased estimate of the oracle loss using true labels. Then, as there are no ready training data for label correction, counterfactual labeling is used to construct artificial training data. Furthermore, since counterfactual labeling utilizes only partial training data, we design an embedding-based alternative training method to enhance performance. Comparative experiments on both public and private datasets and detailed analyses show that our proposed approach effectively alleviates the delayed feedback problem and consistently outperforms the previous state-of-the-art methods.
THUIR2 at NTCIR-16 Session Search Task
Jul 01, 2023



Our team(THUIR2) participated in both FOSS and POSS subtasks of the NTCIR-161 Session Search (SS) Task. This paper describes our approaches and results. In the FOSS subtask, we submit five runs using learning-to-rank and fine-tuned pre-trained language models. We fine-tuned the pre-trained language model with ad-hoc data and session information and assembled them by a learning-to-rank method. The assembled model achieves the best performance among all participants in the preliminary evaluation. In the POSS subtask, we used an assembled model which also achieves the best performance in the preliminary evaluation.
I^3 Retriever: Incorporating Implicit Interaction in Pre-trained Language Models for Passage Retrieval
Jun 04, 2023



Passage retrieval is a fundamental task in many information systems, such as web search and question answering, where both efficiency and effectiveness are critical concerns. In recent years, neural retrievers based on pre-trained language models (PLM), such as dual-encoders, have achieved huge success. Yet, studies have found that the performance of dual-encoders are often limited due to the neglecting of the interaction information between queries and candidate passages. Therefore, various interaction paradigms have been proposed to improve the performance of vanilla dual-encoders. Particularly, recent state-of-the-art methods often introduce late-interaction during the model inference process. However, such late-interaction based methods usually bring extensive computation and storage cost on large corpus. Despite their effectiveness, the concern of efficiency and space footprint is still an important factor that limits the application of interaction-based neural retrieval models. To tackle this issue, we incorporate implicit interaction into dual-encoders, and propose I^3 retriever. In particular, our implicit interaction paradigm leverages generated pseudo-queries to simulate query-passage interaction, which jointly optimizes with query and passage encoders in an end-to-end manner. It can be fully pre-computed and cached, and its inference process only involves simple dot product operation of the query vector and passage vector, which makes it as efficient as the vanilla dual encoders. We conduct comprehensive experiments on MSMARCO and TREC2019 Deep Learning Datasets, demonstrating the I^3 retriever's superiority in terms of both effectiveness and efficiency. Moreover, the proposed implicit interaction is compatible with special pre-training and knowledge distillation for passage retrieval, which brings a new state-of-the-art performance.
Brain Topography Adaptive Network for Satisfaction Modeling in Interactive Information Access System
Aug 17, 2022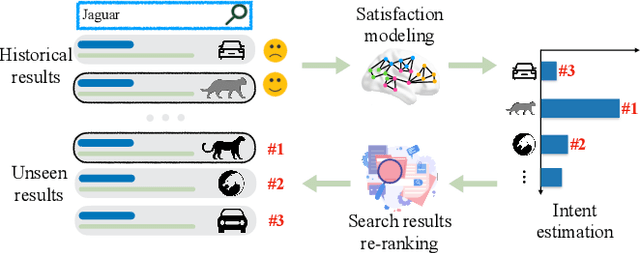
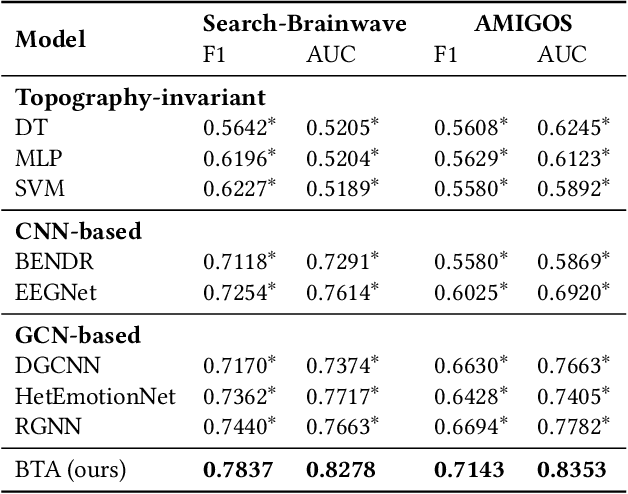
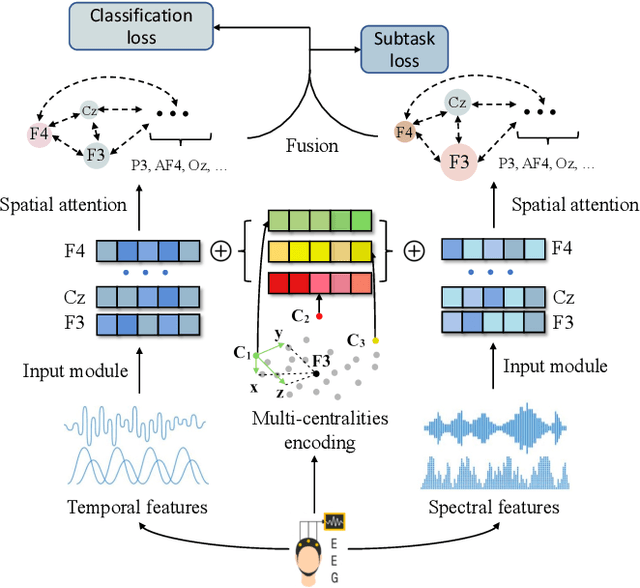

With the growth of information on the Web, most users heavily rely on information access systems (e.g., search engines, recommender systems, etc.) in their daily lives. During this procedure, modeling users' satisfaction status plays an essential part in improving their experiences with the systems. In this paper, we aim to explore the benefits of using Electroencephalography (EEG) signals for satisfaction modeling in interactive information access system design. Different from existing EEG classification tasks, the arisen of satisfaction involves multiple brain functions, such as arousal, prototypicality, and appraisals, which are related to different brain topographical areas. Thus modeling user satisfaction raises great challenges to existing solutions. To address this challenge, we propose BTA, a Brain Topography Adaptive network with a multi-centrality encoding module and a spatial attention mechanism module to capture cognitive connectivities in different spatial distances. We explore the effectiveness of BTA for satisfaction modeling in two popular information access scenarios, i.e., search and recommendation. Extensive experiments on two real-world datasets verify the effectiveness of introducing brain topography adaptive strategy in satisfaction modeling. Furthermore, we also conduct search result re-ranking task and video rating prediction task based on the satisfaction inferred from brain signals on search and recommendation scenarios, respectively. Experimental results show that brain signals extracted with BTA help improve the performance of interactive information access systems significantly.
Disentangled Modeling of Domain and Relevance for Adaptable Dense Retrieval
Aug 11, 2022
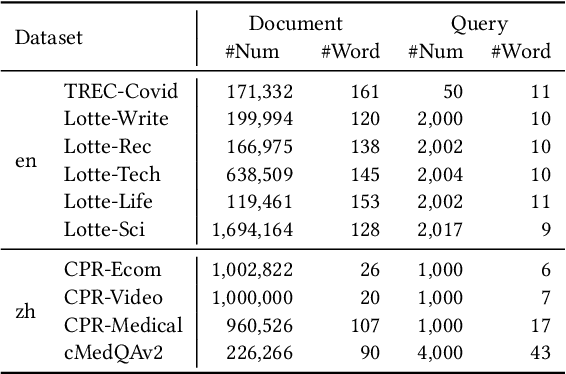
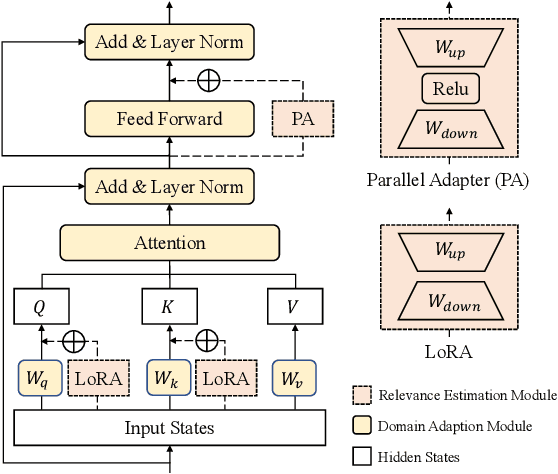
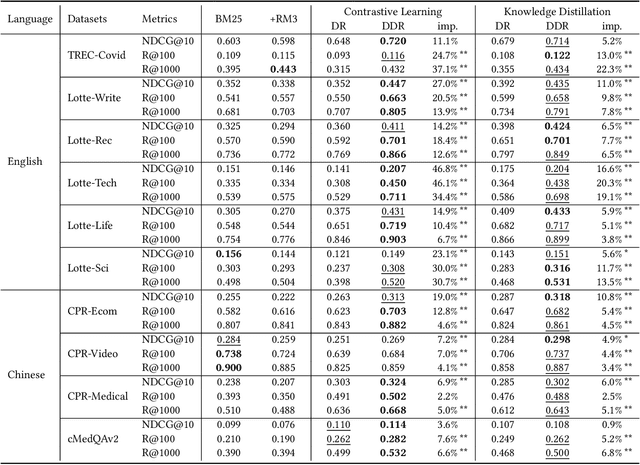
Recent advance in Dense Retrieval (DR) techniques has significantly improved the effectiveness of first-stage retrieval. Trained with large-scale supervised data, DR models can encode queries and documents into a low-dimensional dense space and conduct effective semantic matching. However, previous studies have shown that the effectiveness of DR models would drop by a large margin when the trained DR models are adopted in a target domain that is different from the domain of the labeled data. One of the possible reasons is that the DR model has never seen the target corpus and thus might be incapable of mitigating the difference between the training and target domains. In practice, unfortunately, training a DR model for each target domain to avoid domain shift is often a difficult task as it requires additional time, storage, and domain-specific data labeling, which are not always available. To address this problem, in this paper, we propose a novel DR framework named Disentangled Dense Retrieval (DDR) to support effective and flexible domain adaptation for DR models. DDR consists of a Relevance Estimation Module (REM) for modeling domain-invariant matching patterns and several Domain Adaption Modules (DAMs) for modeling domain-specific features of multiple target corpora. By making the REM and DAMs disentangled, DDR enables a flexible training paradigm in which REM is trained with supervision once and DAMs are trained with unsupervised data. Comprehensive experiments in different domains and languages show that DDR significantly improves ranking performance compared to strong DR baselines and substantially outperforms traditional retrieval methods in most scenarios.