 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSDVec: a Toolbox for Incremental and Scalable Word Embedding
Jun 10, 2016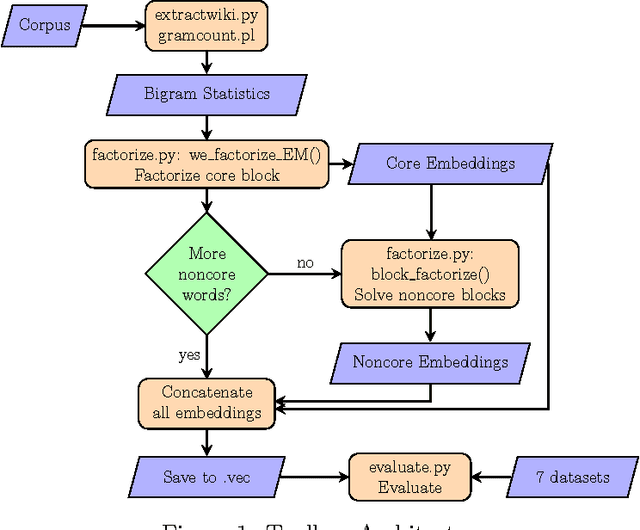

PSDVec is a Python/Perl toolbox that learns word embeddings, i.e. the mapping of words in a natural language to continuous vectors which encode the semantic/syntactic regularities between the words. PSDVec implements a word embedding learning method based on a weighted low-rank positive semidefinite approximation. To scale up the learning process, we implement a blockwise online learning algorithm to learn the embeddings incrementally. This strategy greatly reduces the learning time of word embeddings on a large vocabulary, and can learn the embeddings of new words without re-learning the whole vocabulary. On 9 word similarity/analogy benchmark sets and 2 Natural Language Processing (NLP) tasks, PSDVec produces embeddings that has the best average performance among popular word embedding tools. PSDVec provides a new option for NLP practitioners.
A Generative Word Embedding Model and its Low Rank Positive Semidefinite Solution
Aug 16, 2015
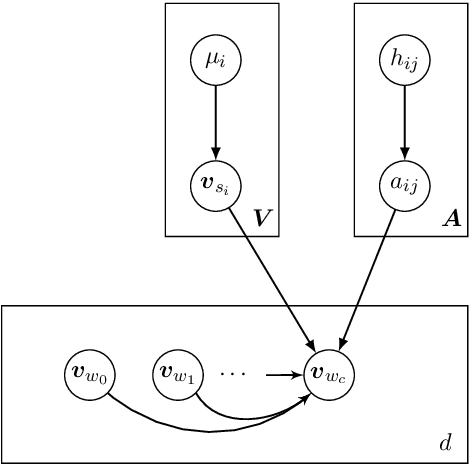
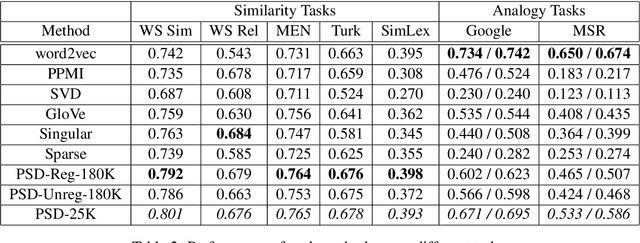

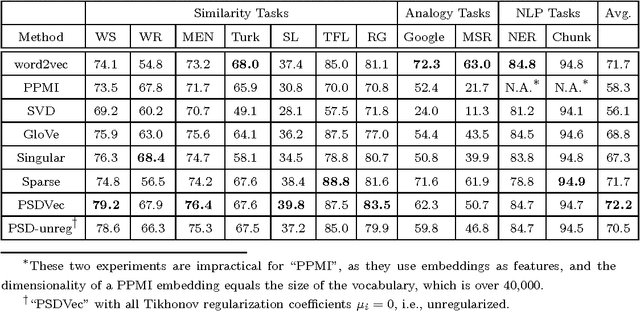
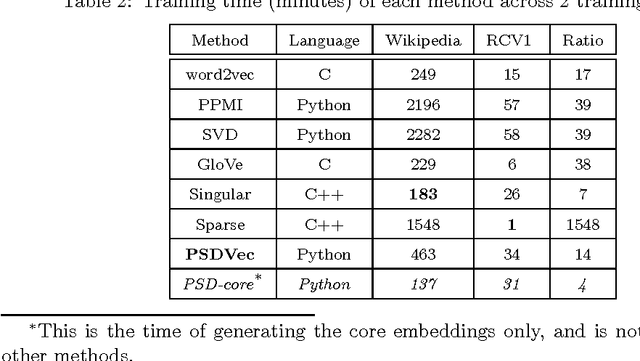
Most existing word embedding methods can be categorized into Neural Embedding Models and Matrix Factorization (MF)-based methods. However some models are opaque to probabilistic interpretation, and MF-based methods, typically solved using Singular Value Decomposition (SVD), may incur loss of corpus information. In addition, it is desirable to incorporate global latent factors, such as topics, sentiments or writing styles, into the word embedding model. Since generative models provide a principled way to incorporate latent factors, we propose a generative word embedding model, which is easy to interpret, and can serve as a basis of more sophisticated latent factor models. The model inference reduces to a low rank weighted positive semidefinite approximation problem. Its optimization is approached by eigendecomposition on a submatrix, followed by online blockwise regression, which is scalable and avoids the information loss in SVD. In experiments on 7 common benchmark datasets, our vectors are competitive to word2vec, and better than other MF-based methods.
On the Equivalence of Factorized Information Criterion Regularization and the Chinese Restaurant Process Prior
Jul 01, 2015Factorized Information Criterion (FIC) is a recently developed information criterion, based on which a novel model selection methodology, namely Factorized Asymptotic Bayesian (FAB) Inference, has been developed and successfully applied to various hierarchical Bayesian models. The Dirichlet Process (DP) prior, and one of its well known representations, the Chinese Restaurant Process (CRP), derive another line of model selection methods. FIC can be viewed as a prior distribution over the latent variable configurations. Under this view, we prove that when the parameter dimensionality $D_{c}=2$, FIC is equivalent to CRP. We argue that when $D_{c}>2$, FIC avoids an inherent problem of DP/CRP, i.e. the data likelihood will dominate the impact of the prior, and thus the model selection capability will weaken as $D_{c}$ increases. However, FIC overestimates the data likelihood. As a result, FIC may be overly biased towards models with less components. We propose a natural generalization of FIC, which finds a middle ground between CRP and FIC, and may yield more accurate model selection results than FIC.
Factorized Asymptotic Bayesian Inference for Factorial Hidden Markov Models
Jun 26, 2015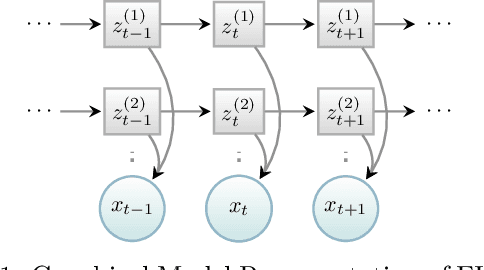
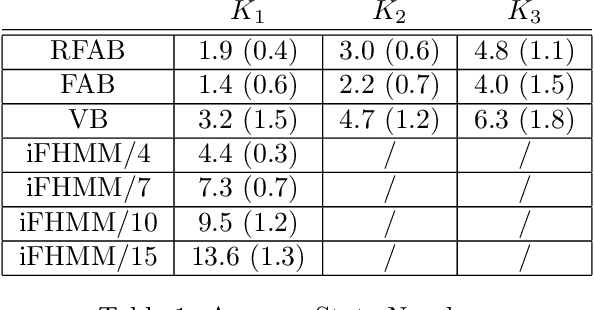
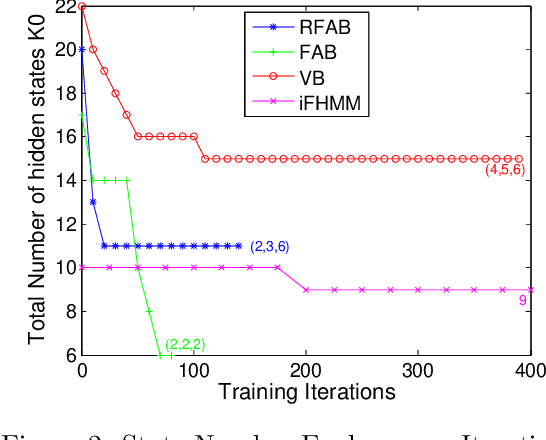
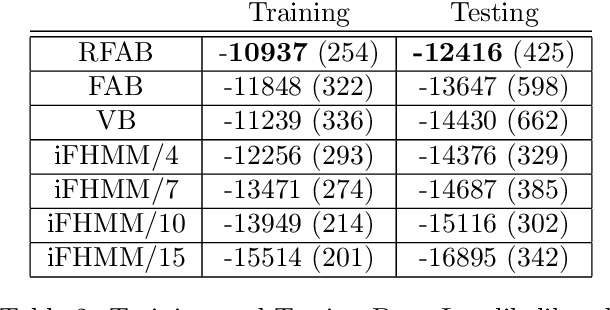
Factorial hidden Markov models (FHMMs) are powerful tools of modeling sequential data. Learning FHMMs yields a challenging simultaneous model selection issue, i.e., selecting the number of multiple Markov chains and the dimensionality of each chain. Our main contribution is to address this model selection issue by extending Factorized Asymptotic Bayesian (FAB) inference to FHMMs. First, we offer a better approximation of marginal log-likelihood than the previous FAB inference. Our key idea is to integrate out transition probabilities, yet still apply the Laplace approximation to emission probabilities. Second, we prove that if there are two very similar hidden states in an FHMM, i.e. one is redundant, then FAB will almost surely shrink and eliminate one of them, making the model parsimonious. Experimental results show that FAB for FHMMs significantly outperforms state-of-the-art nonparametric Bayesian iFHMM and Variational FHMM in model selection accuracy, with competitive held-out perplexity.
Cascade hash tables: a series of multilevel double hashing schemes with O worst case lookup time
Jun 25, 2015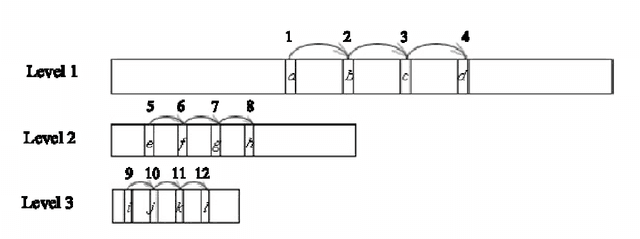
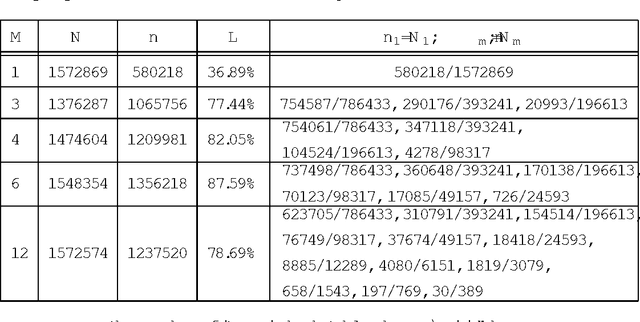
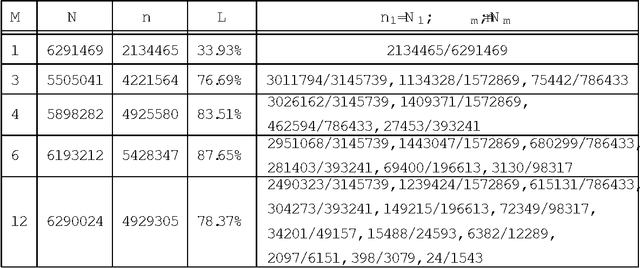
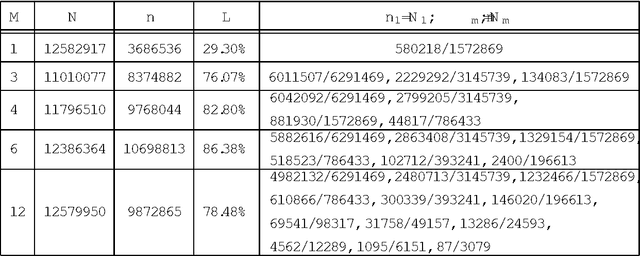
In this paper, the author proposes a series of multilevel double hashing schemes called cascade hash tables. They use several levels of hash tables. In each table, we use the common double hashing scheme. Higher level hash tables work as fail-safes of lower level hash tables. By this strategy, it could effectively reduce collisions in hash insertion. Thus it gains a constant worst case lookup time with a relatively high load factor(70%-85%) in random experiments. Different parameters of cascade hash tables are tested.