 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation by On-the-Fly Native Ensemble
Sep 08, 2018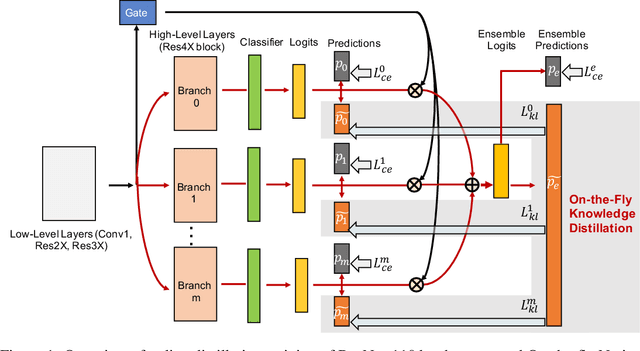
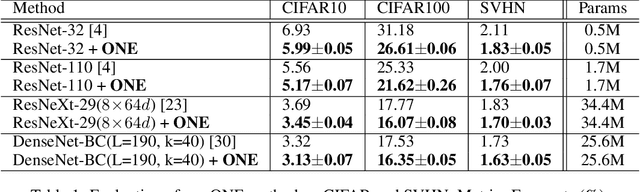

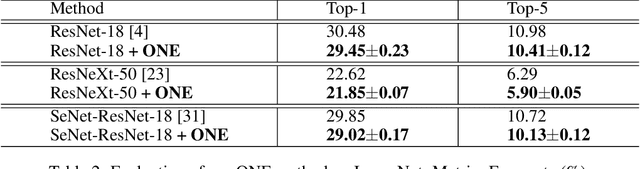
Knowledge distillation is effective to train small and generalisable network models for meeting the low-memory and fast running requirements. Existing offline distillation methods rely on a strong pre-trained teacher, which enables favourable knowledge discovery and transfer but requires a complex two-phase training procedure. Online counterparts address this limitation at the price of lacking a highcapacity teacher. In this work, we present an On-the-fly Native Ensemble (ONE) strategy for one-stage online distillation. Specifically, ONE trains only a single multi-branch network while simultaneously establishing a strong teacher on-the- fly to enhance the learning of target network. Extensive evaluations show that ONE improves the generalisation performance a variety of deep neural networks more significantly than alternative methods on four image classification dataset: CIFAR10, CIFAR100, SVHN, and ImageNet, whilst having the computational efficiency advantages.
Unsupervised Person Re-identification by Deep Learning Tracklet Association
Sep 08, 2018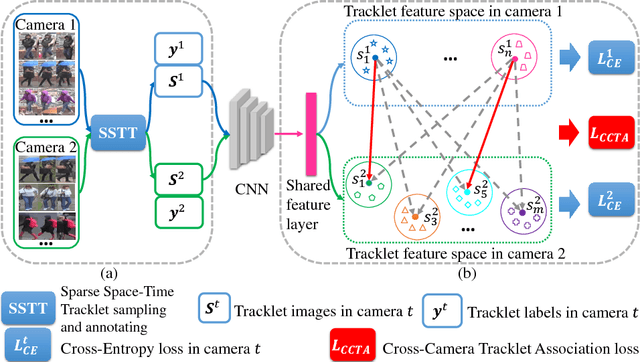
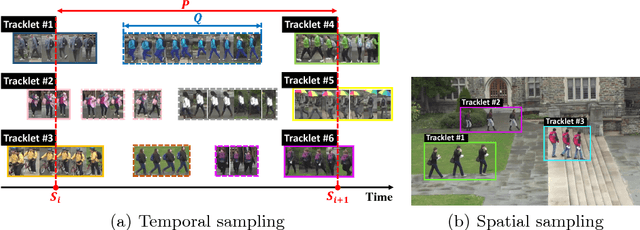
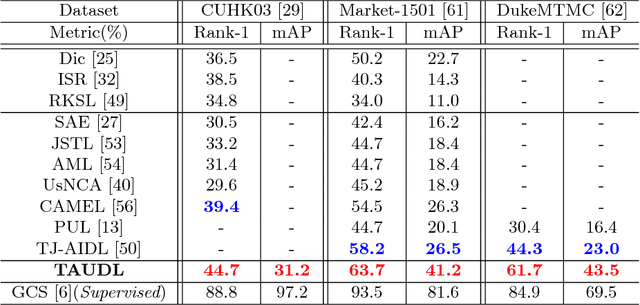
Mostexistingpersonre-identification(re-id)methods relyon supervised model learning on per-camera-pair manually labelled pairwise training data. This leads to poor scalability in practical re-id deployment due to the lack of exhaustive identity labelling of image positive and negative pairs for every camera pair. In this work, we address this problem by proposing an unsupervised re-id deep learning approach capable of incrementally discovering and exploiting the underlying re-id discriminative information from automatically generated person tracklet data from videos in an end-to-end model optimisation. We formulate a Tracklet Association Unsupervised Deep Learning (TAUDL) framework characterised by jointly learning per-camera (within-camera) tracklet association (labelling) and cross-camera tracklet correlation by maximising the discovery of most likely tracklet relationships across camera views. Extensive experiments demonstrate the superiority of the proposed TAUDL model over the state-of-the-art unsupervised and domain adaptation re- id methods using six person re-id benchmarking datasets.
Surveillance Face Recognition Challenge
Aug 29, 2018
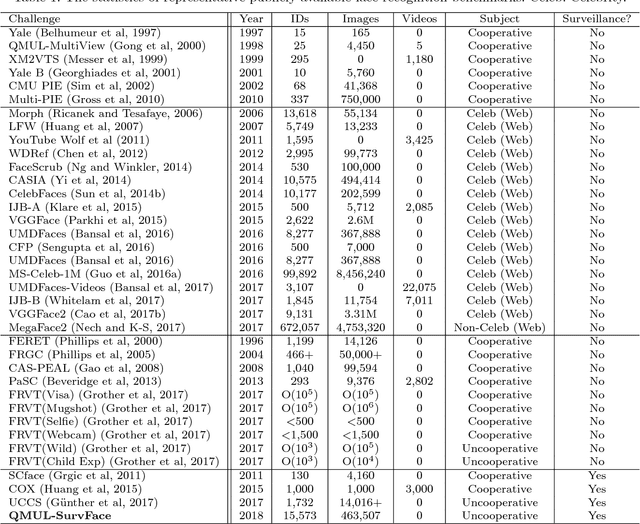
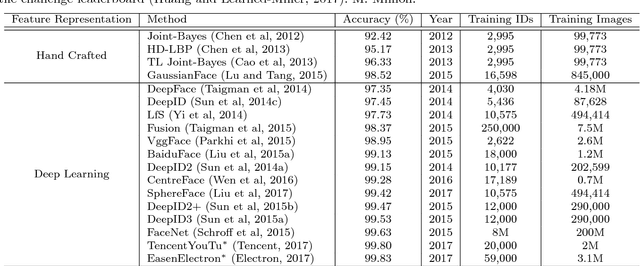
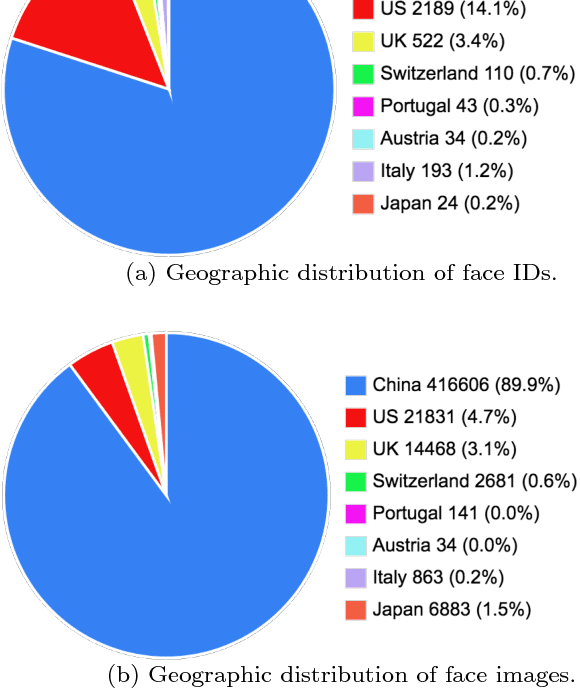
Face recognition (FR) is one of the most extensively investigated problems in computer vision. Significant progress in FR has been made due to the recent introduction of the larger scale FR challenges, particularly with constrained social media web images, e.g. high-resolution photos of celebrity faces taken by professional photo-journalists. However, the more challenging FR in unconstrained and low-resolution surveillance images remains largely under-studied. To facilitate more studies on developing FR models that are effective and robust for low-resolution surveillance facial images, we introduce a new Surveillance Face Recognition Challenge, which we call the QMUL-SurvFace benchmark. This new benchmark is the largest and more importantly the only true surveillance FR benchmark to our best knowledge, where low-resolution images are not synthesised by artificial down-sampling of native high-resolution images. This challenge contains 463,507 face images of 15,573 distinct identities captured in real-world uncooperative surveillance scenes over wide space and time. As a consequence, it presents an extremely challenging FR benchmark. We benchmark the FR performance on this challenge using five representative deep learning face recognition models, in comparison to existing benchmarks. We show that the current state of the arts are still far from being satisfactory to tackle the under-investigated surveillance FR problem in practical forensic scenarios. Face recognition is generally more difficult in an open-set setting which is typical for surveillance scenarios, owing to a large number of non-target people (distractors) appearing open spaced scenes. This is evidently so that on the new Surveillance FR Challenge, the top-performing CentreFace deep learning FR model on the MegaFace benchmark can now only achieve 13.2% success rate (at Rank-20) at a 10% false alarm rate.
Deep Association Learning for Unsupervised Video Person Re-identification
Aug 22, 2018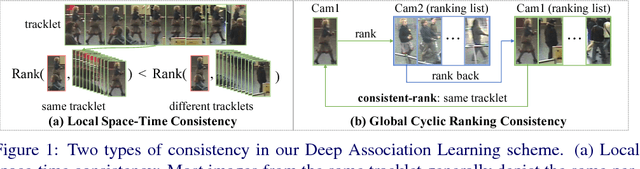
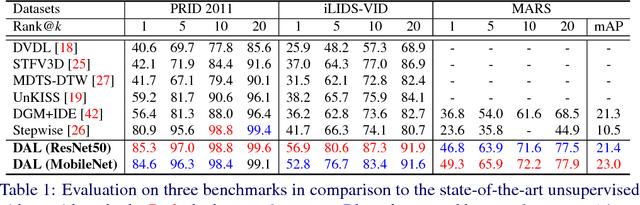
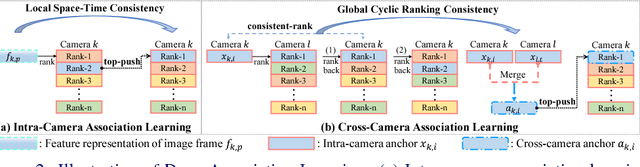

Deep learning methods have started to dominate the research progress of video-based person re-identification (re-id). However, existing methods mostly consider supervised learning, which requires exhaustive manual efforts for labelling cross-view pairwise data. Therefore, they severely lack scalability and practicality in real-world video surveillance applications. In this work, to address the video person re-id task, we formulate a novel Deep Association Learning (DAL) scheme, the first end-to-end deep learning method using none of the identity labels in model initialisation and training. DAL learns a deep re-id matching model by jointly optimising two margin-based association losses in an end-to-end manner, which effectively constrains the association of each frame to the best-matched intra-camera representation and cross-camera representation. Existing standard CNNs can be readily employed within our DAL scheme. Experiment results demonstrate that our proposed DAL significantly outperforms current state-of-the-art unsupervised video person re-id methods on three benchmarks: PRID 2011, iLIDS-VID and MARS.
Person Search by Multi-Scale Matching
Jul 23, 2018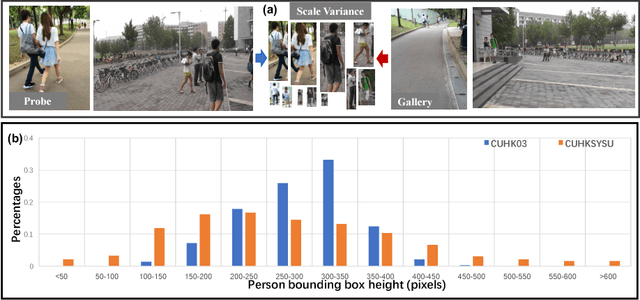

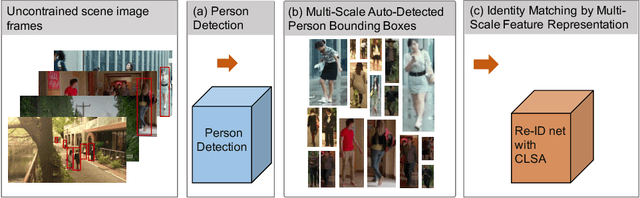
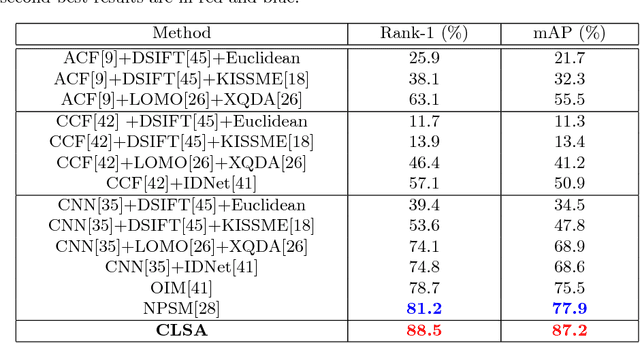
We consider the problem of person search in unconstrained scene images. Existing methods usually focus on improving the person detection accuracy to mitigate negative effects imposed by misalignment, mis-detections, and false alarms resulted from noisy people auto-detection. In contrast to previous studies, we show that sufficiently reliable person instance cropping is achievable by slightly improved state-of-the-art deep learning object detectors (e.g. Faster-RCNN), and the under-studied multi-scale matching problem in person search is a more severe barrier. In this work, we address this multi-scale person search challenge by proposing a Cross-Level Semantic Alignment (CLSA) deep learning approach capable of learning more discriminative identity feature representations in a unified end-to-end model. This is realised by exploiting the in-network feature pyramid structure of a deep neural network enhanced by a novel cross pyramid-level semantic alignment loss function. This favourably eliminates the need for constructing a computationally expensive image pyramid and a complex multi-branch network architecture. Extensive experiments show the modelling advantages and performance superiority of CLSA over the state-of-the-art person search and multi-scale matching methods on two large person search benchmarking datasets: CUHK-SYSU and PRW.
Deep Reinforcement Learning Attention Selection for Person Re-Identification
Jul 07, 2018

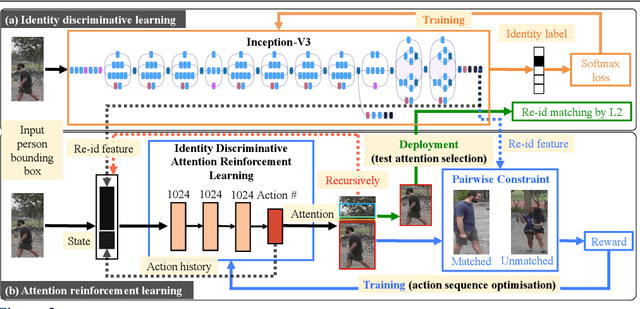
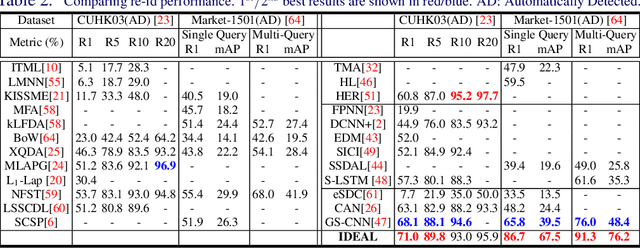
Existing person re-identification (re-id) methods assume the provision of accurately cropped person bounding boxes with minimum background noise, mostly by manually cropping. This is significantly breached in practice when person bounding boxes must be detected automatically given a very large number of images and/or videos processed. Compared to carefully cropped manually, auto-detected bounding boxes are far less accurate with random amount of background clutter which can degrade notably person re-id matching accuracy. In this work, we develop a joint learning deep model that optimises person re-id attention selection within any auto-detected person bounding boxes by reinforcement learning of background clutter minimisation subject to re-id label pairwise constraints. Specifically, we formulate a novel unified re-id architecture called Identity DiscriminativE Attention reinforcement Learning (IDEAL) to accurately select re-id attention in auto-detected bounding boxes for optimising re-id performance. Our model can improve re-id accuracy comparable to that from exhaustive human manual cropping of bounding boxes with additional advantages from identity discriminative attention selection that specially benefits re-id tasks beyond human knowledge. Extensive comparative evaluations demonstrate the re-id advantages of the proposed IDEAL model over a wide range of state-of-the-art re-id methods on two auto-detected re-id benchmarks CUHK03 and Market-1501.
Person Re-Identification in Identity Regression Space
Jun 25, 2018
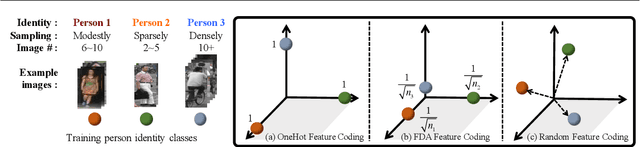
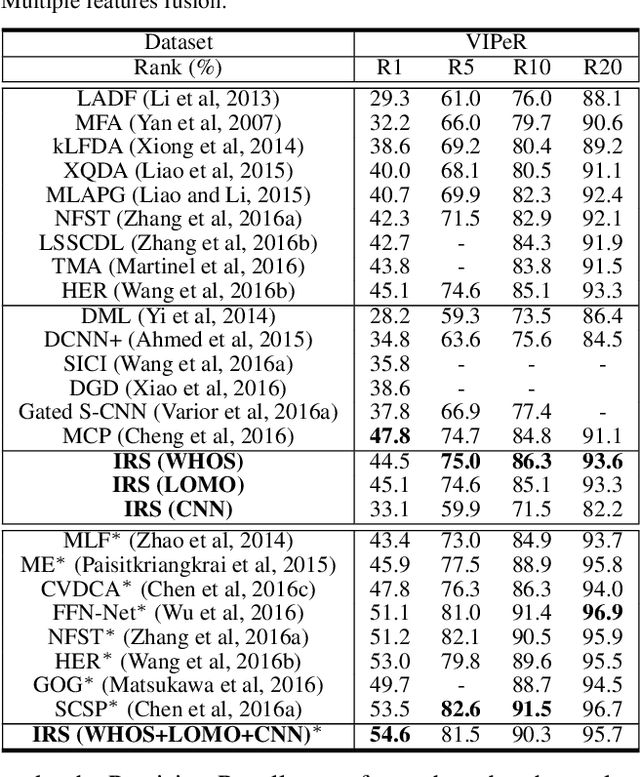
Most existing person re-identification (re-id) methods are unsuitable for real-world deployment due to two reasons: Unscalability to large population size, and Inadaptability over time. In this work, we present a unified solution to address both problems. Specifically, we propose to construct an Identity Regression Space (IRS) based on embedding different training person identities (classes) and formulate re-id as a regression problem solved by identity regression in the IRS. The IRS approach is characterised by a closed-form solution with high learning efficiency and an inherent incremental learning capability with human-in-the-loop. Extensive experiments on four benchmarking datasets(VIPeR, CUHK01, CUHK03 and Market-1501) show that the IRS model not only outperforms state-of-the-art re-id methods, but also is more scalable to large re-id population size by rapidly updating model and actively selecting informative samples with reduced human labelling effort.
Human-In-The-Loop Person Re-Identification
May 04, 2018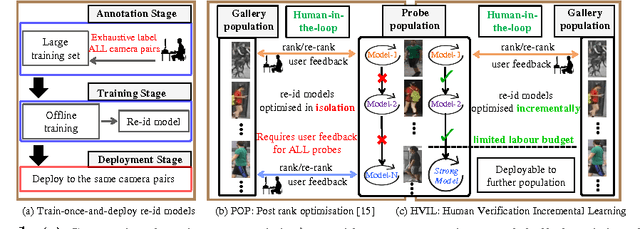
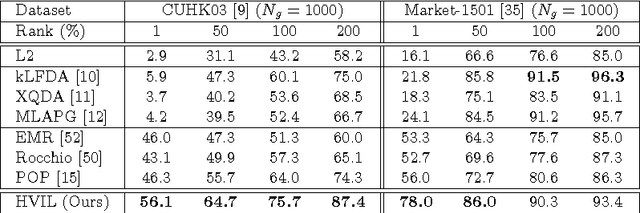

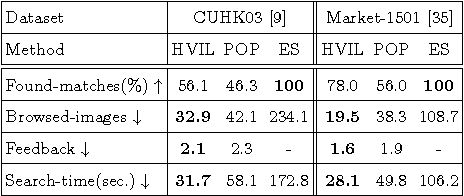
Current person re-identification (re-id) methods assume that (1) pre-labelled training data are available for every camera pair, (2) the gallery size for re-identification is moderate. Both assumptions scale poorly to real-world applications when camera network size increases and gallery size becomes large. Human verification of automatic model ranked re-id results becomes inevitable. In this work, a novel human-in-the-loop re-id model based on Human Verification Incremental Learning (HVIL) is formulated which does not require any pre-labelled training data to learn a model, therefore readily scalable to new camera pairs. This HVIL model learns cumulatively from human feedback to provide instant improvement to re-id ranking of each probe on-the-fly enabling the model scalable to large gallery sizes. We further formulate a Regularised Metric Ensemble Learning (RMEL) model to combine a series of incrementally learned HVIL models into a single ensemble model to be used when human feedback becomes unavailable.
Imbalanced Deep Learning by Minority Class Incremental Rectification
Apr 28, 2018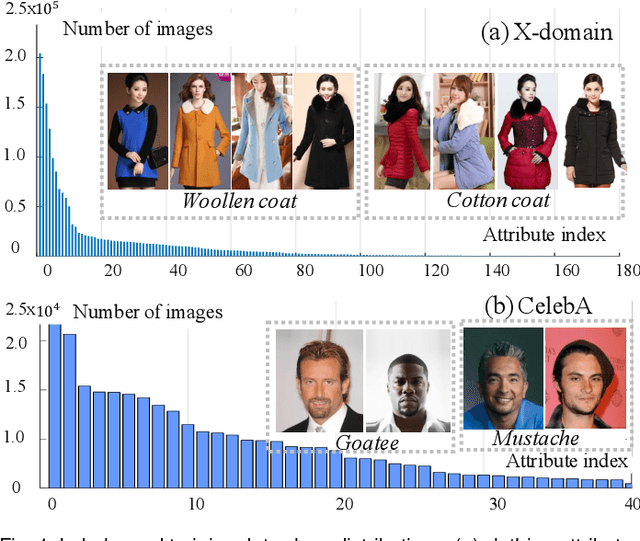
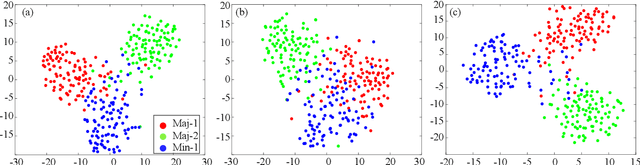
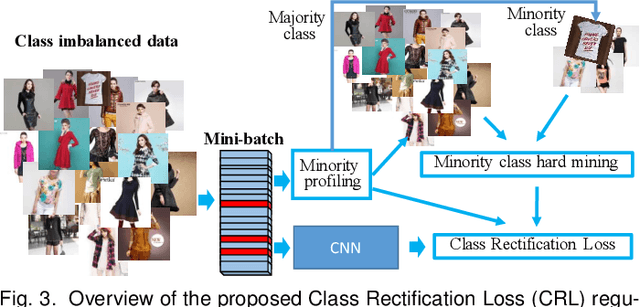
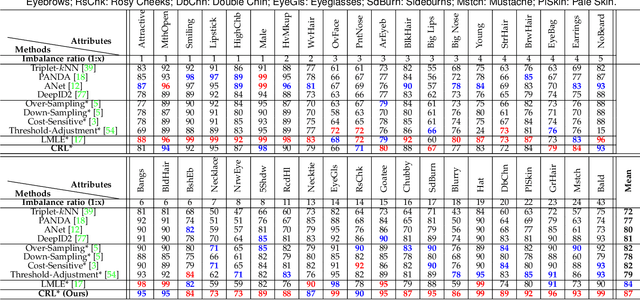
Model learning from class imbalanced training data is a long-standing and significant challenge for machine learning. In particular, existing deep learning methods consider mostly either class balanced data or moderately imbalanced data in model training, and ignore the challenge of learning from significantly imbalanced training data. To address this problem, we formulate a class imbalanced deep learning model based on batch-wise incremental minority (sparsely sampled) class rectification by hard sample mining in majority (frequently sampled) classes during model training. This model is designed to minimise the dominant effect of majority classes by discovering sparsely sampled boundaries of minority classes in an iterative batch-wise learning process. To that end, we introduce a Class Rectification Loss (CRL) function that can be deployed readily in deep network architectures. Extensive experimental evaluations are conducted on three imbalanced person attribute benchmark datasets (CelebA, X-Domain, DeepFashion) and one balanced object category benchmark dataset (CIFAR-100). These experimental results demonstrate the performance advantages and model scalability of the proposed batch-wise incremental minority class rectification model over the existing state-of-the-art models for addressing the problem of imbalanced data learning.
Scalable Deep Learning Logo Detection
Apr 02, 2018
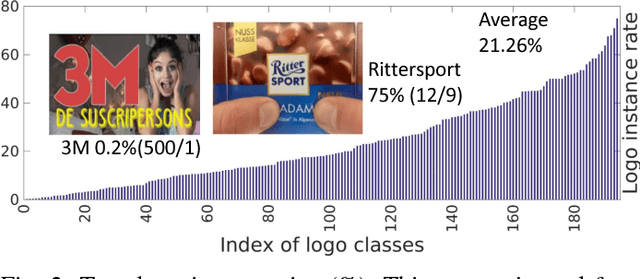


Existing logo detection methods usually consider a small number of logo classes and limited images per class with a strong assumption of requiring tedious object bounding box annotations, therefore not scalable to real-world dynamic applications. In this work, we tackle these challenges by exploring the webly data learning principle without the need for exhaustive manual labelling. Specifically, we propose a novel incremental learning approach, called Scalable Logo Self-co-Learning (SL^2), capable of automatically self-discovering informative training images from noisy web data for progressively improving model capability in a cross-model co-learning manner. Moreover, we introduce a very large (2,190,757 images of 194 logo classes) logo dataset "WebLogo-2M" by an automatic web data collection and processing method. Extensive comparative evaluations demonstrate the superiority of the proposed SL^2 method over the state-of-the-art strongly and weakly supervised detection models and contemporary webly data learning approaches.