 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity Characterization for Linear Contextual MDPs
Feb 05, 2024Contextual Markov decision processes (CMDPs) describe a class of reinforcement learning problems in which the transition kernels and reward functions can change over time with different MDPs indexed by a context variable. While CMDPs serve as an important framework to model many real-world applications with time-varying environments, they are largely unexplored from theoretical perspective. In this paper, we study CMDPs under two linear function approximation models: Model I with context-varying representations and common linear weights for all contexts; and Model II with common representations for all contexts and context-varying linear weights. For both models, we propose novel model-based algorithms and show that they enjoy guaranteed $\epsilon$-suboptimality gap with desired polynomial sample complexity. In particular, instantiating our result for the first model to the tabular CMDP improves the existing result by removing the reachability assumption. Our result for the second model is the first-known result for such a type of function approximation models. Comparison between our results for the two models further indicates that having context-varying features leads to much better sample efficiency than having common representations for all contexts under linear CMDPs.
Quickest Change Detection in Autoregressive Models
Oct 13, 2023



The problem of quickest change detection (QCD) in autoregressive (AR) models is investigated. A system is being monitored with sequentially observed samples. At some unknown time, a disturbance signal occurs and changes the distribution of the observations. The disturbance signal follows an AR model, which is dependent over time. Before the change, observations only consist of measurement noise, and are independent and identically distributed (i.i.d.). After the change, observations consist of the disturbance signal and the measurement noise, are dependent over time, which essentially follow a continuous-state hidden Markov model (HMM). The goal is to design a stopping time to detect the disturbance signal as quickly as possible subject to false alarm constraints. Existing approaches for general non-i.i.d. settings and discrete-state HMMs cannot be applied due to their high computational complexity and memory consumption, and they usually assume some asymptotic stability condition. In this paper, the asymptotic stability condition is firstly theoretically proved for the AR model by a novel design of forward variable and auxiliary Markov chain. A computationally efficient Ergodic CuSum algorithm that can be updated recursively is then constructed and is further shown to be asymptotically optimal. The data-driven setting where the disturbance signal parameters are unknown is further investigated, and an online and computationally efficient gradient ascent CuSum algorithm is designed. The algorithm is constructed by iteratively updating the estimate of the unknown parameters based on the maximum likelihood principle and the gradient ascent approach. The lower bound on its average running length to false alarm is also derived for practical false alarm control. Simulation results are provided to demonstrate the performance of the proposed algorithms.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023



In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Distributionally Robust Optimization Efficiently Solves Offline Reinforcement Learning
May 22, 2023

Offline reinforcement learning aims to find the optimal policy from a pre-collected dataset without active exploration. This problem is faced with major challenges, such as a limited amount of data and distribution shift. Existing studies employ the principle of pessimism in face of uncertainty, and penalize rewards for less visited state-action pairs. In this paper, we directly model the uncertainty in the transition kernel using an uncertainty set, and then employ the approach of distributionally robust optimization that optimizes the worst-case performance over the uncertainty set. We first design a Hoeffding-style uncertainty set, which guarantees that the true transition kernel lies in the uncertainty set with high probability. We theoretically prove that it achieves an $\epsilon$-accuracy with a sample complexity of $\mathcal{O}\left((1-\gamma)^{-4}\epsilon^{-2}SC^{\pi^*} \right)$, where $\gamma$ is the discount factor, $C^{\pi^*}$ is the single-policy concentrability for any comparator policy $\pi^*$, and $S$ is the number of states. We further design a Bernstein-style uncertainty set, which does not necessarily guarantee the true transition kernel lies in the uncertainty set. We show an improved and near-optimal sample complexity of $\mathcal{O}\left((1-\gamma)^{-3}\epsilon^{-2}\left(SC^{\pi^*}+(\mu_{\min})^{-1}\right) \right)$, where $\mu_{\min}$ denotes the minimal non-zero entry of the behavior distribution. In addition, the computational complexity of our algorithms is the same as one of the LCB-based methods in the literature. Our results demonstrate that distributionally robust optimization method can also efficiently solve offline reinforcement learning.
Model-Free Robust Average-Reward Reinforcement Learning
May 17, 2023



Robust Markov decision processes (MDPs) address the challenge of model uncertainty by optimizing the worst-case performance over an uncertainty set of MDPs. In this paper, we focus on the robust average-reward MDPs under the model-free setting. We first theoretically characterize the structure of solutions to the robust average-reward Bellman equation, which is essential for our later convergence analysis. We then design two model-free algorithms, robust relative value iteration (RVI) TD and robust RVI Q-learning, and theoretically prove their convergence to the optimal solution. We provide several widely used uncertainty sets as examples, including those defined by the contamination model, total variation, Chi-squared divergence, Kullback-Leibler (KL) divergence and Wasserstein distance.
Robust Average-Reward Markov Decision Processes
Jan 02, 2023


In robust Markov decision processes (MDPs), the uncertainty in the transition kernel is addressed by finding a policy that optimizes the worst-case performance over an uncertainty set of MDPs. While much of the literature has focused on discounted MDPs, robust average-reward MDPs remain largely unexplored. In this paper, we focus on robust average-reward MDPs, where the goal is to find a policy that optimizes the worst-case average reward over an uncertainty set. We first take an approach that approximates average-reward MDPs using discounted MDPs. We prove that the robust discounted value function converges to the robust average-reward as the discount factor $\gamma$ goes to $1$, and moreover, when $\gamma$ is large, any optimal policy of the robust discounted MDP is also an optimal policy of the robust average-reward. We further design a robust dynamic programming approach, and theoretically characterize its convergence to the optimum. Then, we investigate robust average-reward MDPs directly without using discounted MDPs as an intermediate step. We derive the robust Bellman equation for robust average-reward MDPs, prove that the optimal policy can be derived from its solution, and further design a robust relative value iteration algorithm that provably finds its solution, or equivalently, the optimal robust policy.
A Robust and Constrained Multi-Agent Reinforcement Learning Framework for Electric Vehicle AMoD Systems
Sep 17, 2022

Electric vehicles (EVs) play critical roles in autonomous mobility-on-demand (AMoD) systems, but their unique charging patterns increase the model uncertainties in AMoD systems (e.g. state transition probability). Since there usually exists a mismatch between the training and test (true) environments, incorporating model uncertainty into system design is of critical importance in real-world applications. However, model uncertainties have not been considered explicitly in EV AMoD system rebalancing by existing literature yet and remain an urgent and challenging task. In this work, we design a robust and constrained multi-agent reinforcement learning (MARL) framework with transition kernel uncertainty for the EV rebalancing and charging problem. We then propose a robust and constrained MARL algorithm (ROCOMA) that trains a robust EV rebalancing policy to balance the supply-demand ratio and the charging utilization rate across the whole city under state transition uncertainty. Experiments show that the ROCOMA can learn an effective and robust rebalancing policy. It outperforms non-robust MARL methods when there are model uncertainties. It increases the system fairness by 19.6% and decreases the rebalancing costs by 75.8%.
Robust Constrained Reinforcement Learning
Sep 14, 2022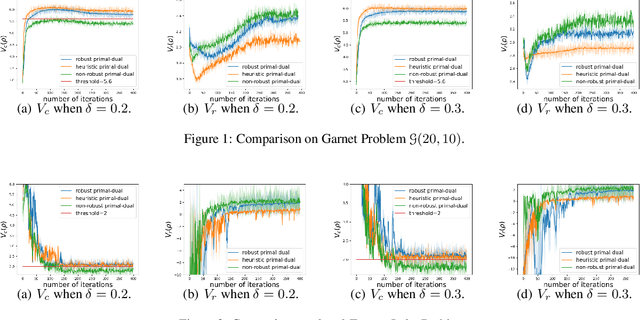
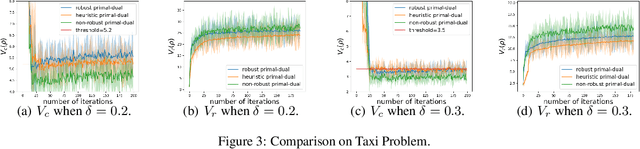
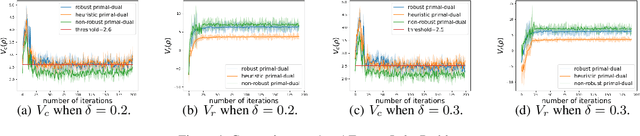
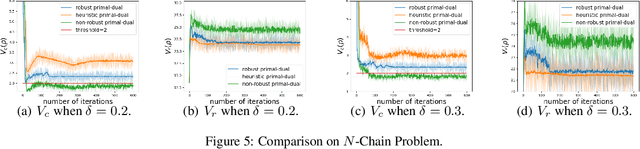
Constrained reinforcement learning is to maximize the expected reward subject to constraints on utilities/costs. However, the training environment may not be the same as the test one, due to, e.g., modeling error, adversarial attack, non-stationarity, resulting in severe performance degradation and more importantly constraint violation. We propose a framework of robust constrained reinforcement learning under model uncertainty, where the MDP is not fixed but lies in some uncertainty set, the goal is to guarantee that constraints on utilities/costs are satisfied for all MDPs in the uncertainty set, and to maximize the worst-case reward performance over the uncertainty set. We design a robust primal-dual approach, and further theoretically develop guarantee on its convergence, complexity and robust feasibility. We then investigate a concrete example of $\delta$-contamination uncertainty set, design an online and model-free algorithm and theoretically characterize its sample complexity.
Finite-Time Error Bounds for Greedy-GQ
Sep 06, 2022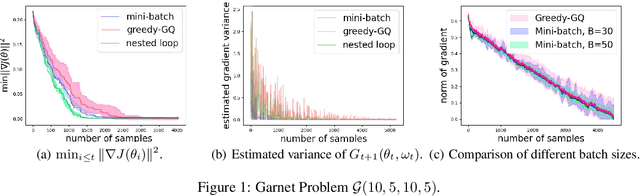
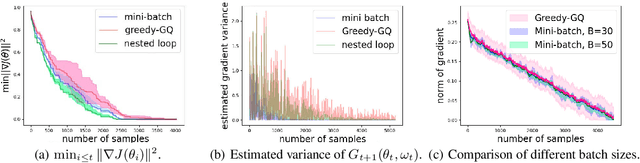
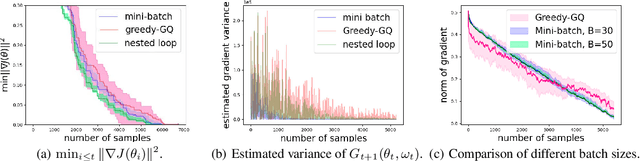
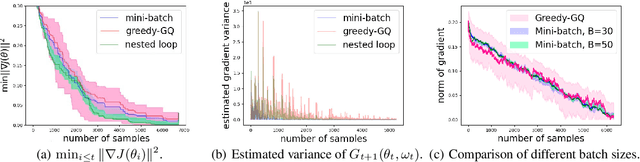
Greedy-GQ with linear function approximation, originally proposed in \cite{maei2010toward}, is a value-based off-policy algorithm for optimal control in reinforcement learning, and it has a non-linear two timescale structure with a non-convex objective function. This paper develops its finite-time error bounds. We show that the Greedy-GQ algorithm converges as fast as $\mathcal{O}({1}/{\sqrt{T}})$ under the i.i.d.\ setting and $\mathcal{O}({\log T}/{\sqrt{T}})$ under the Markovian setting. We further design a variant of the vanilla Greedy-GQ algorithm using the nested-loop approach, and show that its sample complexity is $\mathcal{O}({\log(1/\epsilon)\epsilon^{-2}})$, which matches with the one of the vanilla Greedy-GQ. Our finite-time error bounds match with one of the stochastic gradient descent algorithms for general smooth non-convex optimization problems. Our finite-sample analysis provides theoretical guidance on choosing step-sizes for faster convergence in practice and suggests the trade-off between the convergence rate and the quality of the obtained policy. Our techniques in this paper provide a general approach for finite-sample analysis of non-convex two timescale value-based reinforcement learning algorithms.
Quickest Anomaly Detection in Sensor Networks With Unlabeled Samples
Sep 04, 2022



The problem of quickest anomaly detection in networks with unlabeled samples is studied. At some unknown time, an anomaly emerges in the network and changes the data-generating distribution of some unknown sensor. The data vector received by the fusion center at each time step undergoes some unknown and arbitrary permutation of its entries (unlabeled samples). The goal of the fusion center is to detect the anomaly with minimal detection delay subject to false alarm constraints. With unlabeled samples, existing approaches that combines local cumulative sum (CuSum) statistics cannot be used anymore. Several major questions include whether detection is still possible without the label information, if so, what is the fundamental limit and how to achieve that. Two cases with static and dynamic anomaly are investigated, where the sensor affected by the anomaly may or may not change with time. For the two cases, practical algorithms based on the ideas of mixture likelihood ratio and/or maximum likelihood estimate are constructed. Their average detection delays and false alarm rates are theoretically characterized. Universal lower bounds on the average detection delay for a given false alarm rate are also derived, which further demonstrate the asymptotic optimality of the two algorithms.