 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Action Recognition using Semantic Body Part Actions
Dec 14, 2016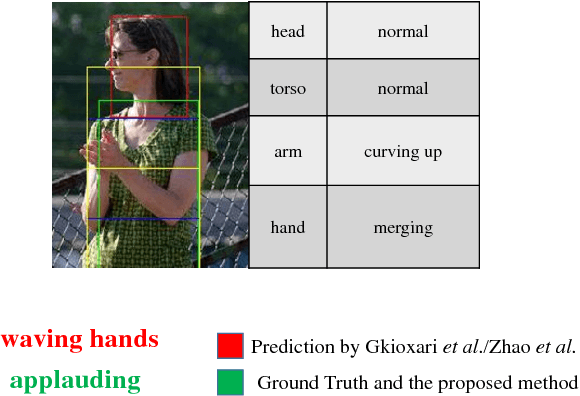
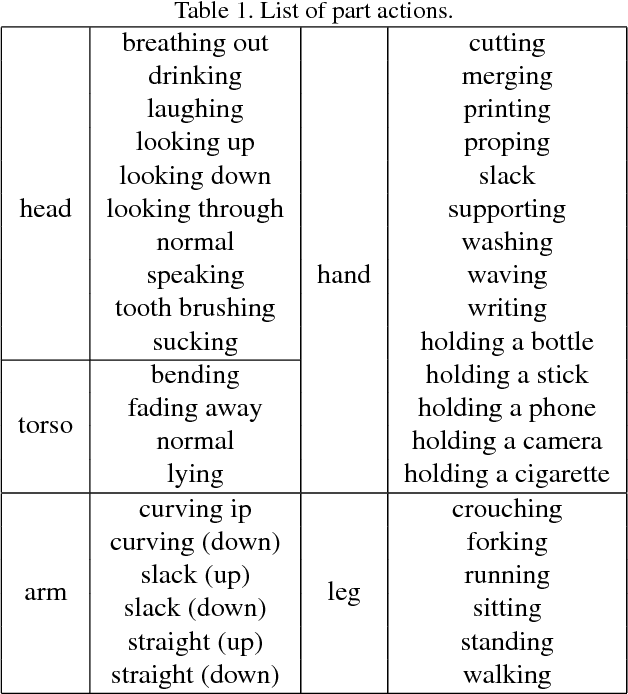
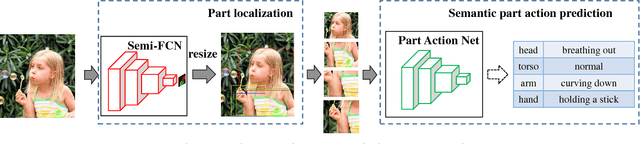
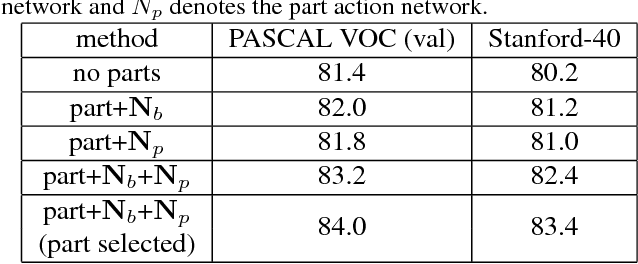
In this paper, we propose a novel single image action recognition algorithm which is based on the idea of semantic body part actions. Unlike existing bottom up methods, we argue that the human action is a combination of meaningful body part actions. In detail, we divide human body into five parts: head, torso, arms, hands and legs. And for each of the body parts, we define several semantic body part actions, e.g., hand holding, hand waving. These semantic body part actions are strongly related to the body actions, e.g., writing, and jogging. Based on the idea, we propose a deep neural network based system: first, body parts are localized by a Semi-FCN network. Second, for each body parts, a Part Action Res-Net is used to predict semantic body part actions. And finally, we use SVM to fuse the body part actions and predict the entire body action. Experiments on two dataset: PASCAL VOC 2012 and Stanford-40 report mAP improvement from the state-of-the-art by 3.8% and 2.6% respectively.
Haze Visibility Enhancement: A Survey and Quantitative Benchmarking
Jul 21, 2016
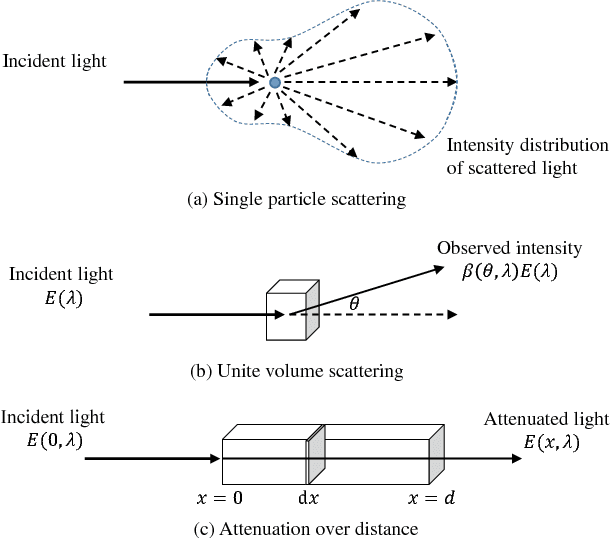
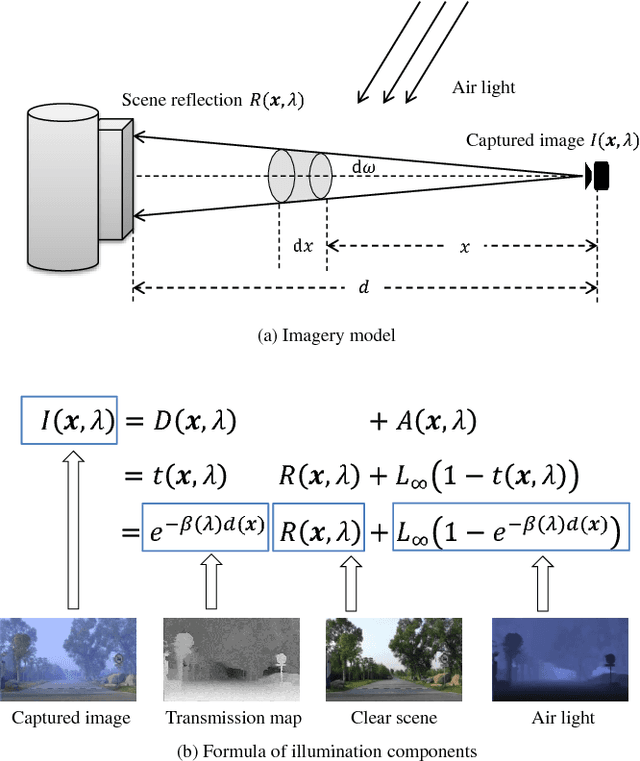
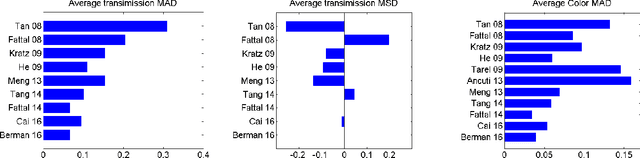
This paper provides a comprehensive survey of methods dealing with visibility enhancement of images taken in hazy or foggy scenes. The survey begins with discussing the optical models of atmospheric scattering media and image formation. This is followed by a survey of existing methods, which are grouped to multiple image methods, polarizing filters based methods, methods with known depth, and single-image methods. We also provide a benchmark of a number of well known single-image methods, based on a recent dataset provided by Fattal and our newly generated scattering media dataset that contains ground truth images for quantitative evaluation. To our knowledge, this is the first benchmark using numerical metrics to evaluate dehazing techniques. This benchmark allows us to objectively compare the results of existing methods and to better identify the strengths and limitations of each method.
Multiview Rectification of Folded Documents
Jun 01, 2016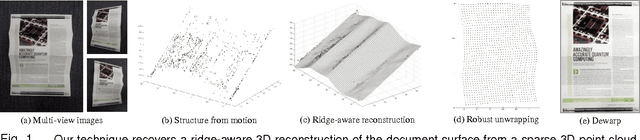


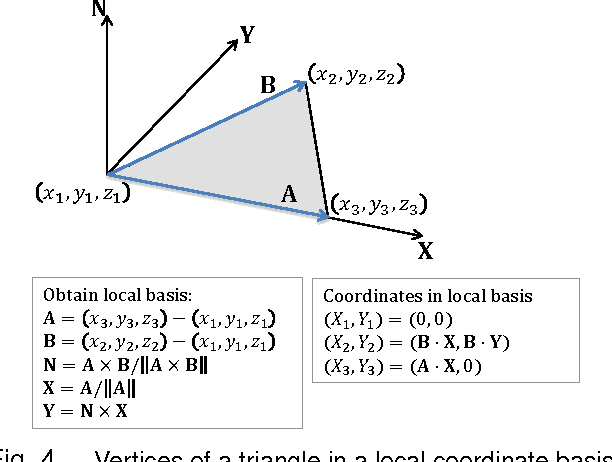
Digitally unwrapping images of paper sheets is crucial for accurate document scanning and text recognition. This paper presents a method for automatically rectifying curved or folded paper sheets from a few images captured from multiple viewpoints. Prior methods either need expensive 3D scanners or model deformable surfaces using over-simplified parametric representations. In contrast, our method uses regular images and is based on general developable surface models that can represent a wide variety of paper deformations. Our main contribution is a new robust rectification method based on ridge-aware 3D reconstruction of a paper sheet and unwrapping the reconstructed surface using properties of developable surfaces via $\ell_1$ conformal mapping. We present results on several examples including book pages, folded letters and shopping receipts.
Perceptually Consistent Color-to-Gray Image Conversion
May 06, 2016

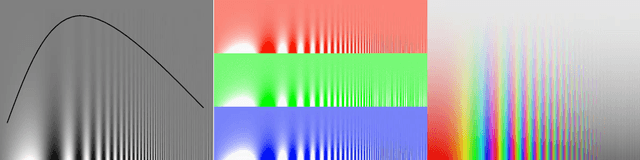

In this paper, we propose a color to grayscale image conversion algorithm (C2G) that aims to preserve the perceptual properties of the color image as much as possible. To this end, we propose measures for two perceptual properties based on contemporary research in vision science: brightness and multi-scale contrast. The brightness measurement is based on the idea that the brightness of a grayscale image will affect the perception of the probability of color information. The color contrast measurement is based on the idea that the contrast of a given pixel to its surroundings can be measured as a linear combination of color contrast at different scales. Based on these measures we propose a graph based optimization framework to balance the brightness and contrast measurements. To solve the optimization, an $\ell_1$-norm based method is provided which converts color discontinuities to brightness discontinuities. To validate our methods, we evaluate against the existing \cadik and Color250 datasets, and against NeoColor, a new dataset that improves over existing C2G datasets. NeoColor contains around 300 images from typical C2G scenarios, including: commercial photograph, printing, books, magazines, masterpiece artworks and computer designed graphics. We show improvements in metrics of performance, and further through a user study, we validate the performance of both the algorithm and the metric.
Waterdrop Stereo
Apr 04, 2016
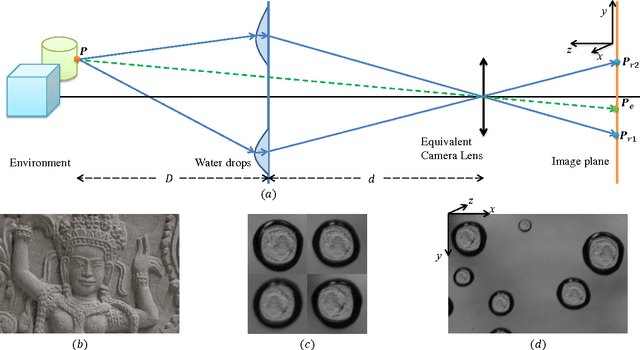

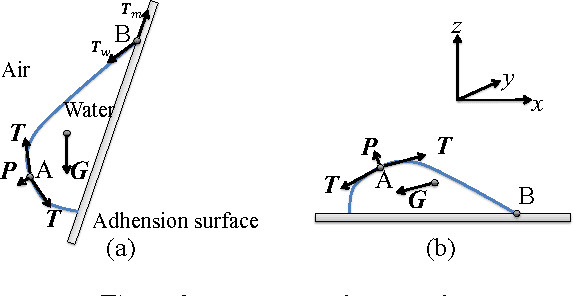
This paper introduces depth estimation from water drops. The key idea is that a single water drop adhered to window glass is totally transparent and convex, and thus optically acts like a fisheye lens. If we have more than one water drop in a single image, then through each of them we can see the environment with different view points, similar to stereo. To realize this idea, we need to rectify every water drop imagery to make radially distorted planar surfaces look flat. For this rectification, we consider two physical properties of water drops: (1) A static water drop has constant volume, and its geometric convex shape is determined by the balance between the tension force and gravity. This implies that the 3D geometric shape can be obtained by minimizing the overall potential energy, which is the sum of the tension energy and the gravitational potential energy. (2) The imagery inside a water-drop is determined by the water-drop 3D shape and total reflection at the boundary. This total reflection generates a dark band commonly observed in any adherent water drops. Hence, once the 3D shape of water drops are recovered, we can rectify the water drop images through backward raytracing. Subsequently, we can compute depth using stereo. In addition to depth estimation, we can also apply image refocusing. Experiments on real images and a quantitative evaluation show the effectiveness of our proposed method. To our best knowledge, never before have adherent water drops been used to estimate depth.