 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildSplatter: Feed-forward 3D Gaussian Splatting with Appearance Control from Unconstrained Images
Apr 23, 2026We propose WildSplatter, a feed-forward 3D Gaussian Splatting (3DGS) model for unconstrained images with unknown camera parameters and varying lighting conditions. 3DGS is an effective scene representation that enables high-quality, real-time rendering; however, it typically requires iterative optimization and multi-view images captured under consistent lighting with known camera parameters. WildSplatter is trained on unconstrained photo collections and jointly learns 3D Gaussians and appearance embeddings conditioned on input images. This design enables flexible modulation of Gaussian colors to represent significant variations in lighting and appearance. Our method reconstructs 3D Gaussians from sparse input views in under one second, while also enabling appearance control under diverse lighting conditions. Experimental results demonstrate that our approach outperforms existing pose-free 3DGS methods on challenging real-world datasets with varying illumination.
UFV-Splatter: Pose-Free Feed-Forward 3D Gaussian Splatting Adapted to Unfavorable Views
Jul 30, 2025This paper presents a pose-free, feed-forward 3D Gaussian Splatting (3DGS) framework designed to handle unfavorable input views. A common rendering setup for training feed-forward approaches places a 3D object at the world origin and renders it from cameras pointed toward the origin -- i.e., from favorable views, limiting the applicability of these models to real-world scenarios involving varying and unknown camera poses. To overcome this limitation, we introduce a novel adaptation framework that enables pretrained pose-free feed-forward 3DGS models to handle unfavorable views. We leverage priors learned from favorable images by feeding recentered images into a pretrained model augmented with low-rank adaptation (LoRA) layers. We further propose a Gaussian adapter module to enhance the geometric consistency of the Gaussians derived from the recentered inputs, along with a Gaussian alignment method to render accurate target views for training. Additionally, we introduce a new training strategy that utilizes an off-the-shelf dataset composed solely of favorable images. Experimental results on both synthetic images from the Google Scanned Objects dataset and real images from the OmniObject3D dataset validate the effectiveness of our method in handling unfavorable input views.
NLOS-NeuS: Non-line-of-sight Neural Implicit Surface
Mar 22, 2023



Non-line-of-sight (NLOS) imaging is conducted to infer invisible scenes from indirect light on visible objects. The neural transient field (NeTF) was proposed for representing scenes as neural radiance fields in NLOS scenes. We propose NLOS neural implicit surface (NLOS-NeuS), which extends the NeTF to neural implicit surfaces with a signed distance function (SDF) for reconstructing three-dimensional surfaces in NLOS scenes. We introduce two constraints as loss functions for correctly learning an SDF to avoid non-zero level-set surfaces. We also introduce a lower bound constraint of an SDF based on the geometry of the first-returning photons. The experimental results indicate that these constraints are essential for learning a correct SDF in NLOS scenes. Compared with previous methods with discretized representation, NLOS-NeuS with the neural continuous representation enables us to reconstruct smooth surfaces while preserving fine details in NLOS scenes. To the best of our knowledge, this is the first study on neural implicit surfaces with volume rendering in NLOS scenes.
Deep Depth from Focal Stack with Defocus Model for Camera-Setting Invariance
Feb 26, 2022



We propose a learning-based depth from focus/defocus (DFF), which takes a focal stack as input for estimating scene depth. Defocus blur is a useful cue for depth estimation. However, the size of the blur depends on not only scene depth but also camera settings such as focus distance, focal length, and f-number. Current learning-based methods without any defocus models cannot estimate a correct depth map if camera settings are different at training and test times. Our method takes a plane sweep volume as input for the constraint between scene depth, defocus images, and camera settings, and this intermediate representation enables depth estimation with different camera settings at training and test times. This camera-setting invariance can enhance the applicability of learning-based DFF methods. The experimental results also indicate that our method is robust against a synthetic-to-real domain gap, and exhibits state-of-the-art performance.
Enhancing Passive Non-Line-of-Sight Imaging Using Polarization Cues
Nov 29, 2019This paper presents a method of passive non-line-of-sight (NLOS) imaging using polarization cues. A key observation is that the oblique light has a different polarimetric signal. It turns out this effect is due to the polarization axis rotation, a phenomena which can be used to better condition the light transport matrix for non-line-of-sight imaging. Our analysis and results show that the use of a polarizer in front of the camera is not only a separate technique, but it can be seen as an enhancement technique for more advanced forms of passive NLOS imaging. For example, this paper shows that polarization can enhance passive NLOS imaging both with and without occluders. In all tested cases, despite the light attenuation from polarization optics, recovery of the occluded images is improved.
Waterdrop Stereo
Apr 04, 2016
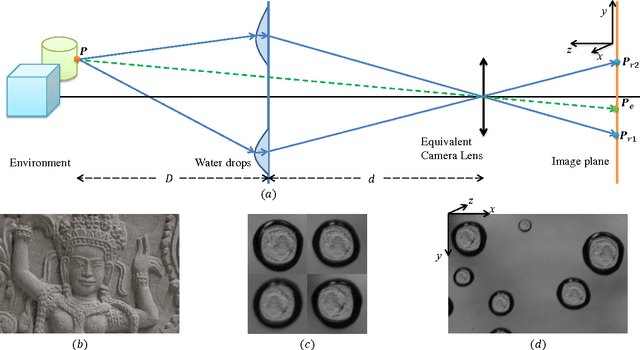

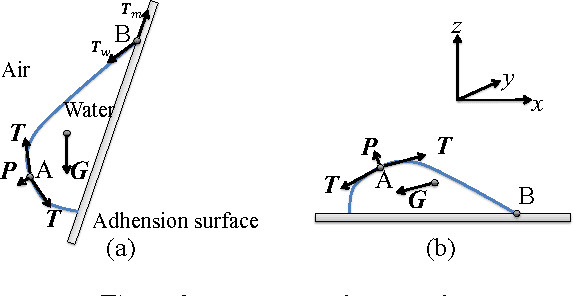
This paper introduces depth estimation from water drops. The key idea is that a single water drop adhered to window glass is totally transparent and convex, and thus optically acts like a fisheye lens. If we have more than one water drop in a single image, then through each of them we can see the environment with different view points, similar to stereo. To realize this idea, we need to rectify every water drop imagery to make radially distorted planar surfaces look flat. For this rectification, we consider two physical properties of water drops: (1) A static water drop has constant volume, and its geometric convex shape is determined by the balance between the tension force and gravity. This implies that the 3D geometric shape can be obtained by minimizing the overall potential energy, which is the sum of the tension energy and the gravitational potential energy. (2) The imagery inside a water-drop is determined by the water-drop 3D shape and total reflection at the boundary. This total reflection generates a dark band commonly observed in any adherent water drops. Hence, once the 3D shape of water drops are recovered, we can rectify the water drop images through backward raytracing. Subsequently, we can compute depth using stereo. In addition to depth estimation, we can also apply image refocusing. Experiments on real images and a quantitative evaluation show the effectiveness of our proposed method. To our best knowledge, never before have adherent water drops been used to estimate depth.