 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Apr 27, 2024Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
Inspire the Large Language Model by External Knowledge on BioMedical Named Entity Recognition
Sep 21, 2023



Large language models (LLMs) have demonstrated dominating performance in many NLP tasks, especially on generative tasks. However, they often fall short in some information extraction tasks, particularly those requiring domain-specific knowledge, such as Biomedical Named Entity Recognition (NER). In this paper, inspired by Chain-of-thought, we leverage the LLM to solve the Biomedical NER step-by-step: break down the NER task into entity span extraction and entity type determination. Additionally, for entity type determination, we inject entity knowledge to address the problem that LLM's lack of domain knowledge when predicting entity category. Experimental results show a significant improvement in our two-step BioNER approach compared to previous few-shot LLM baseline. Additionally, the incorporation of external knowledge significantly enhances entity category determination performance.
DMNER: Biomedical Entity Recognition by Detection and Matching
Jul 05, 2023



Biomedical named entity recognition (BNER) serves as the foundation for numerous biomedical text mining tasks. Unlike general NER, BNER require a comprehensive grasp of the domain, and incorporating external knowledge beyond training data poses a significant challenge. In this study, we propose a novel BNER framework called DMNER. By leveraging existing entity representation models SAPBERT, we tackle BNER as a two-step process: entity boundary detection and biomedical entity matching. DMNER exhibits applicability across multiple NER scenarios: 1) In supervised NER, we observe that DMNER effectively rectifies the output of baseline NER models, thereby further enhancing performance. 2) In distantly supervised NER, combining MRC and AutoNER as span boundary detectors enables DMNER to achieve satisfactory results. 3) For training NER by merging multiple datasets, we adopt a framework similar to DS-NER but additionally leverage ChatGPT to obtain high-quality phrases in the training. Through extensive experiments conducted on 10 benchmark datasets, we demonstrate the versatility and effectiveness of DMNER.
GoSum: Extractive Summarization of Long Documents by Reinforcement Learning and Graph Organized discourse state
Nov 18, 2022



Handling long texts with structural information and excluding redundancy between summary sentences are essential in extractive document summarization. In this work, we propose GoSum, a novel reinforcement-learning-based extractive model for long-paper summarization. GoSum encodes states by building a heterogeneous graph from different discourse levels for each input document. We evaluate the model on two datasets of scientific articles summarization: PubMed and arXiv where it outperforms all extractive summarization models and most of the strong abstractive baselines.
AttentionXML: Extreme Multi-Label Text Classification with Multi-Label Attention Based Recurrent Neural Networks
Nov 01, 2018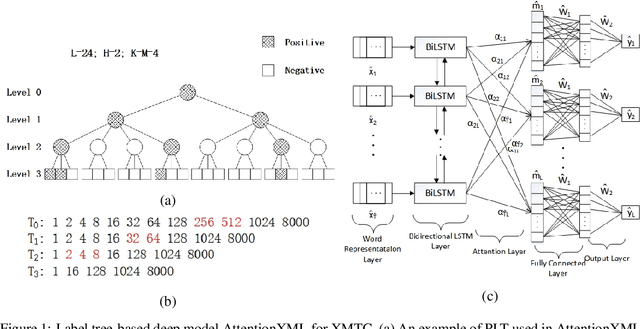
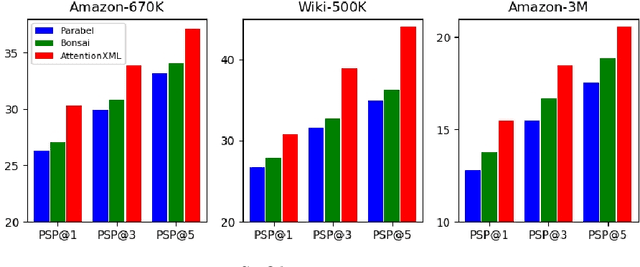
Extreme multi-label text classification (XMTC) is a task for tagging each given text with the most relevant multiple labels from an extremely large-scale label set. This task can be found in many applications, such as product categorization,web page tagging, news annotation and so on. Many methods have been proposed so far for solving XMTC, while most of the existing methods use traditional bag-of-words (BOW) representation, ignoring word context as well as deep semantic information. XML-CNN, a state-of-the-art deep learning-based method, uses convolutional neural network (CNN) with dynamic pooling to process the text, going beyond the BOW-based appraoches but failing to capture 1) the long-distance dependency among words and 2) different levels of importance of a word for each label. We propose a new deep learning-based method, AttentionXML, which uses bidirectional long short-term memory (LSTM) and a multi-label attention mechanism for solving the above 1st and 2nd problems, respectively. We empirically compared AttentionXML with other six state-of-the-art methods over five benchmark datasets. AttentionXML outperformed all competing methods under all experimental settings except only a couple of cases. In addition, a consensus ensemble of AttentionXML with the second best method, Parabel, could further improve the performance over all five benchmark datasets.