 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Why did the Model Fail?": Attributing Model Performance Changes to Distribution Shifts
Oct 19, 2022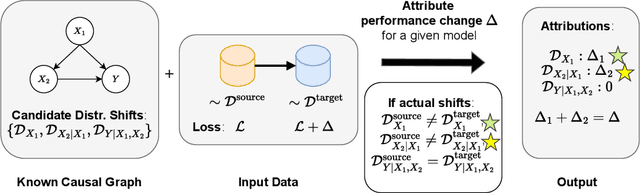

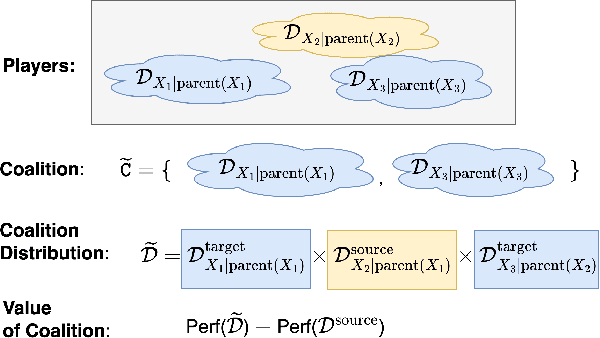
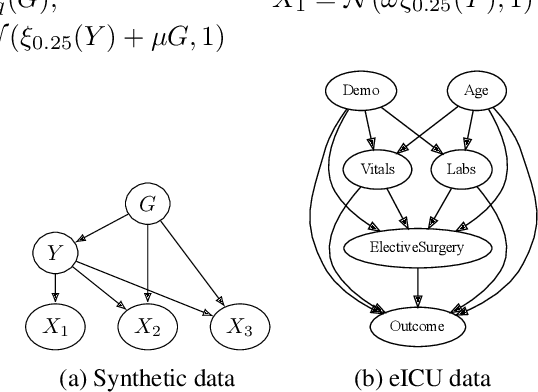
Performance of machine learning models may differ between training and deployment for many reasons. For instance, model performance can change between environments due to changes in data quality, observing a different population than the one in training, or changes in the relationship between labels and features. These manifest as changes to the underlying data generating mechanisms, and thereby result in distribution shifts across environments. Attributing performance changes to specific shifts, such as covariate or concept shifts, is critical for identifying sources of model failures, and for taking mitigating actions that ensure robust models. In this work, we introduce the problem of attributing performance differences between environments to shifts in the underlying data generating mechanisms. We formulate the problem as a cooperative game and derive an importance weighting method for computing the value of a coalition (or a set) of distributions. The contribution of each distribution to the total performance change is then quantified as its Shapley value. We demonstrate the correctness and utility of our method on two synthetic datasets and two real-world case studies, showing its effectiveness in attributing performance changes to a wide range of distribution shifts.
Towards Robust Off-Policy Evaluation via Human Inputs
Sep 18, 2022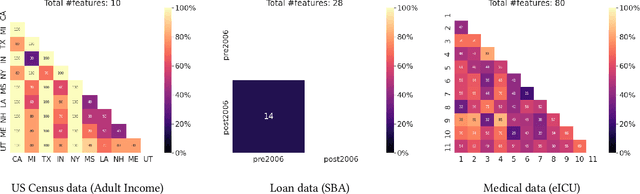

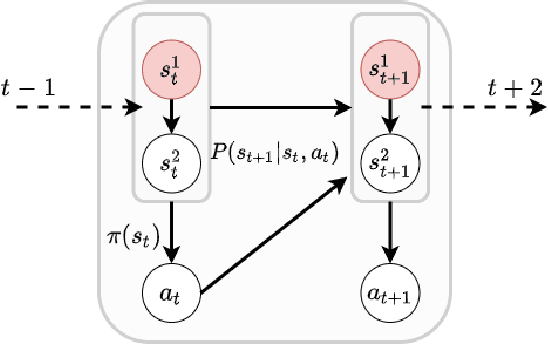
Off-policy Evaluation (OPE) methods are crucial tools for evaluating policies in high-stakes domains such as healthcare, where direct deployment is often infeasible, unethical, or expensive. When deployment environments are expected to undergo changes (that is, dataset shifts), it is important for OPE methods to perform robust evaluation of the policies amidst such changes. Existing approaches consider robustness against a large class of shifts that can arbitrarily change any observable property of the environment. This often results in highly pessimistic estimates of the utilities, thereby invalidating policies that might have been useful in deployment. In this work, we address the aforementioned problem by investigating how domain knowledge can help provide more realistic estimates of the utilities of policies. We leverage human inputs on which aspects of the environments may plausibly change, and adapt the OPE methods to only consider shifts on these aspects. Specifically, we propose a novel framework, Robust OPE (ROPE), which considers shifts on a subset of covariates in the data based on user inputs, and estimates worst-case utility under these shifts. We then develop computationally efficient algorithms for OPE that are robust to the aforementioned shifts for contextual bandits and Markov decision processes. We also theoretically analyze the sample complexity of these algorithms. Extensive experimentation with synthetic and real world datasets from the healthcare domain demonstrates that our approach not only captures realistic dataset shifts accurately, but also results in less pessimistic policy evaluations.
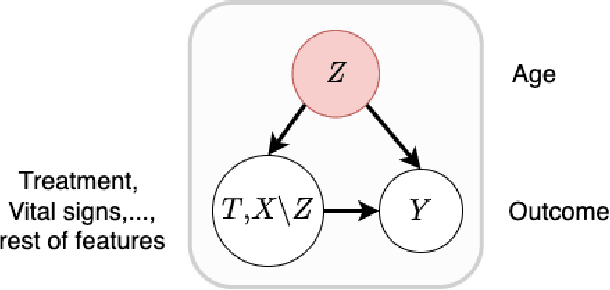
Generalizing Off-Policy Evaluation From a Causal Perspective For Sequential Decision-Making
Jan 20, 2022Assessing the effects of a policy based on observational data from a different policy is a common problem across several high-stake decision-making domains, and several off-policy evaluation (OPE) techniques have been proposed. However, these methods largely formulate OPE as a problem disassociated from the process used to generate the data (i.e. structural assumptions in the form of a causal graph). We argue that explicitly highlighting this association has important implications on our understanding of the fundamental limits of OPE. First, this implies that current formulation of OPE corresponds to a narrow set of tasks, i.e. a specific causal estimand which is focused on prospective evaluation of policies over populations or sub-populations. Second, we demonstrate how this association motivates natural desiderata to consider a general set of causal estimands, particularly extending the role of OPE for counterfactual off-policy evaluation at the level of individuals of the population. A precise description of the causal estimand highlights which OPE estimands are identifiable from observational data under the stated generative assumptions. For those OPE estimands that are not identifiable, the causal perspective further highlights where more experimental data is necessary, and highlights situations where human expertise can aid identification and estimation. Furthermore, many formalisms of OPE overlook the role of uncertainty entirely in the estimation process.We demonstrate how specifically characterising the causal estimand highlights the different sources of uncertainty and when human expertise can naturally manage this uncertainty. We discuss each of these aspects as actionable desiderata for future OPE research at scale and in-line with practical utility.
Pre-emptive learning-to-defer for sequential medical decision-making under uncertainty
Sep 13, 2021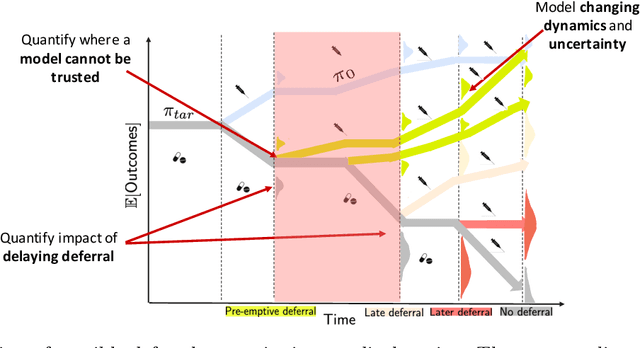
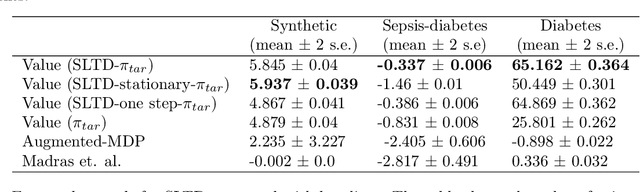
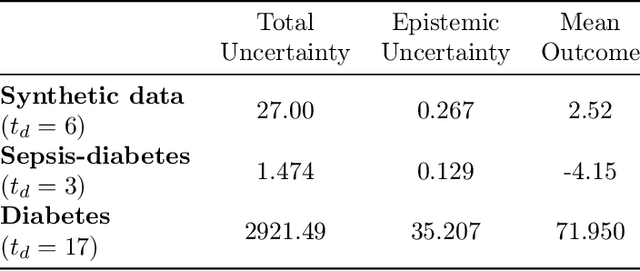
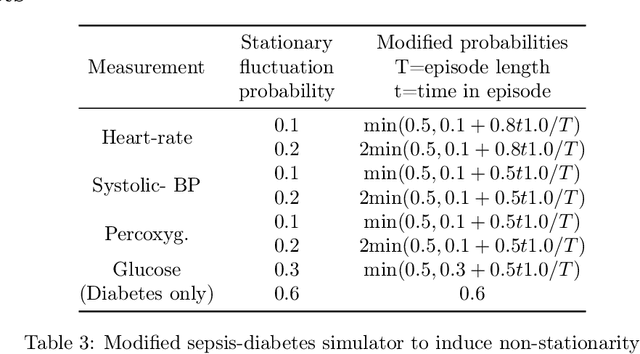
We propose SLTD (`Sequential Learning-to-Defer') a framework for learning-to-defer pre-emptively to an expert in sequential decision-making settings. SLTD measures the likelihood of improving value of deferring now versus later based on the underlying uncertainty in dynamics. In particular, we focus on the non-stationarity in the dynamics to accurately learn the deferral policy. We demonstrate our pre-emptive deferral can identify regions where the current policy has a low probability of improving outcomes. SLTD outperforms existing non-sequential learning-to-defer baselines, whilst reducing overall uncertainty on multiple synthetic and real-world simulators with non-stationary dynamics. We further derive and decompose the propagated (long-term) uncertainty for interpretation by the domain expert to provide an indication of when the model's performance is reliable.
Pulling Up by the Causal Bootstraps: Causal Data Augmentation for Pre-training Debiasing
Aug 27, 2021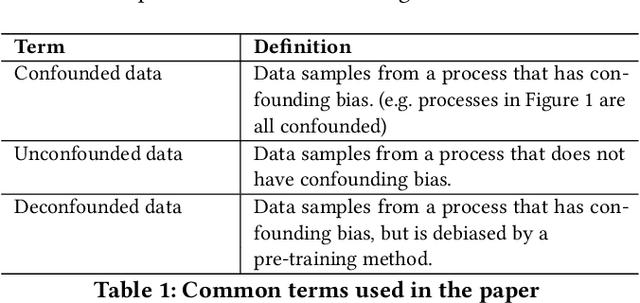


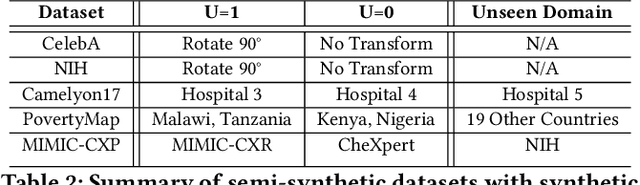
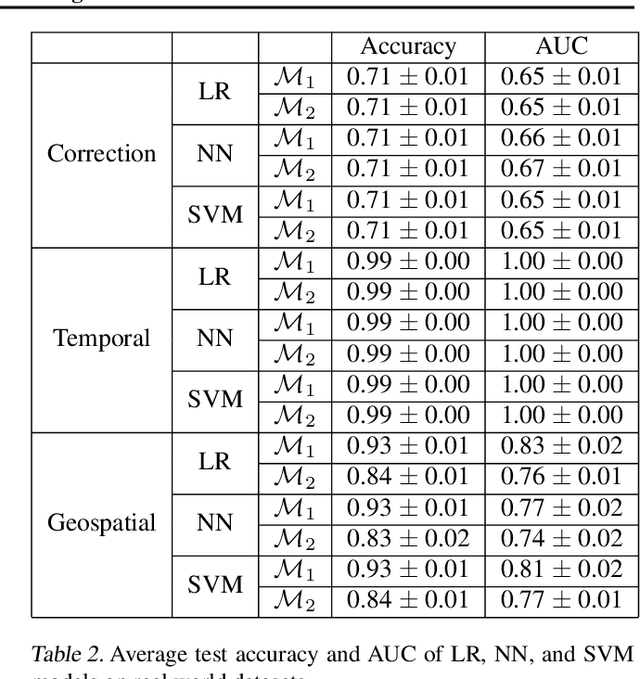
Machine learning models achieve state-of-the-art performance on many supervised learning tasks. However, prior evidence suggests that these models may learn to rely on shortcut biases or spurious correlations (intuitively, correlations that do not hold in the test as they hold in train) for good predictive performance. Such models cannot be trusted in deployment environments to provide accurate predictions. While viewing the problem from a causal lens is known to be useful, the seamless integration of causation techniques into machine learning pipelines remains cumbersome and expensive. In this work, we study and extend a causal pre-training debiasing technique called causal bootstrapping (CB) under five practical confounded-data generation-acquisition scenarios (with known and unknown confounding). Under these settings, we systematically investigate the effect of confounding bias on deep learning model performance, demonstrating their propensity to rely on shortcut biases when these biases are not properly accounted for. We demonstrate that such a causal pre-training technique can significantly outperform existing base practices to mitigate confounding bias on real-world domain generalization benchmarking tasks. This systematic investigation underlines the importance of accounting for the underlying data-generating mechanisms and fortifying data-preprocessing pipelines with a causal framework to develop methods robust to confounding biases.
On the Connections between Counterfactual Explanations and Adversarial Examples
Jun 18, 2021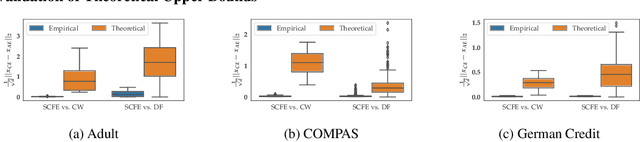
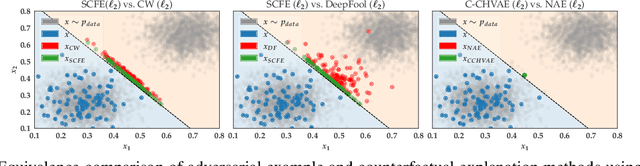

Counterfactual explanations and adversarial examples have emerged as critical research areas for addressing the explainability and robustness goals of machine learning (ML). While counterfactual explanations were developed with the goal of providing recourse to individuals adversely impacted by algorithmic decisions, adversarial examples were designed to expose the vulnerabilities of ML models. While prior research has hinted at the commonalities between these frameworks, there has been little to no work on systematically exploring the connections between the literature on counterfactual explanations and adversarial examples. In this work, we make one of the first attempts at formalizing the connections between counterfactual explanations and adversarial examples. More specifically, we theoretically analyze salient counterfactual explanation and adversarial example generation methods, and highlight the conditions under which they behave similarly. Our analysis demonstrates that several popular counterfactual explanation and adversarial example generation methods such as the ones proposed by Wachter et. al. and Carlini and Wagner (with mean squared error loss), and C-CHVAE and natural adversarial examples by Zhao et. al. are equivalent. We also bound the distance between counterfactual explanations and adversarial examples generated by Wachter et. al. and DeepFool methods for linear models. Finally, we empirically validate our theoretical findings using extensive experimentation with synthetic and real world datasets.
An Empirical Framework for Domain Generalization in Clinical Settings
Apr 15, 2021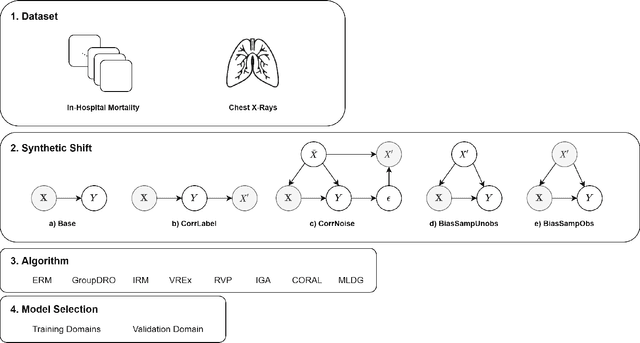

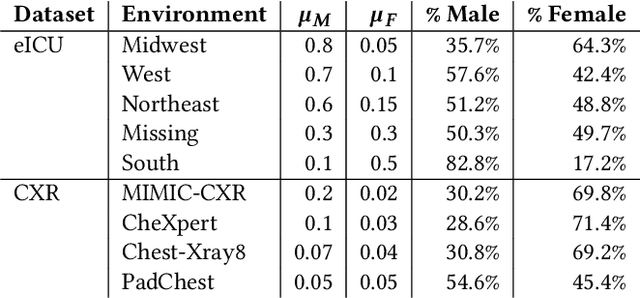
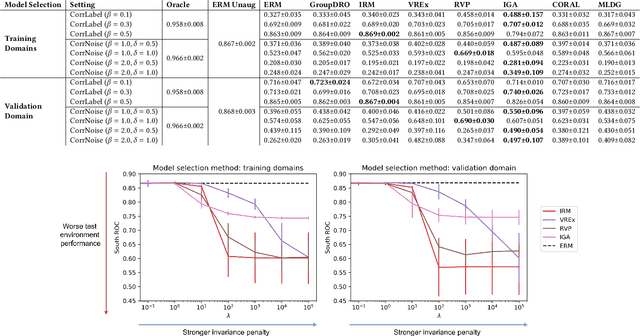
Clinical machine learning models experience significantly degraded performance in datasets not seen during training, e.g., new hospitals or populations. Recent developments in domain generalization offer a promising solution to this problem by creating models that learn invariances across environments. In this work, we benchmark the performance of eight domain generalization methods on multi-site clinical time series and medical imaging data. We introduce a framework to induce synthetic but realistic domain shifts and sampling bias to stress-test these methods over existing non-healthcare benchmarks. We find that current domain generalization methods do not consistently achieve significant gains in out-of-distribution performance over empirical risk minimization on real-world medical imaging data, in line with prior work on general imaging datasets. However, a subset of realistic induced-shift scenarios in clinical time series data do exhibit limited performance gains. We characterize these scenarios in detail, and recommend best practices for domain generalization in the clinical setting.
Learning Under Adversarial and Interventional Shifts
Mar 29, 2021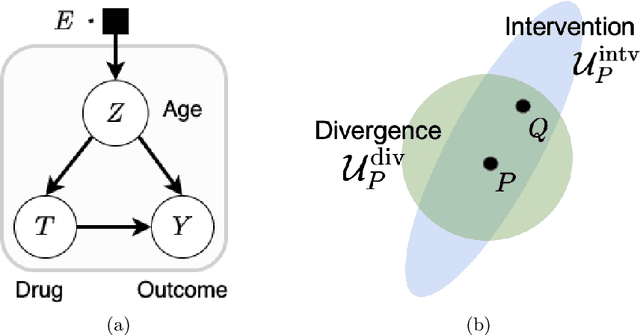
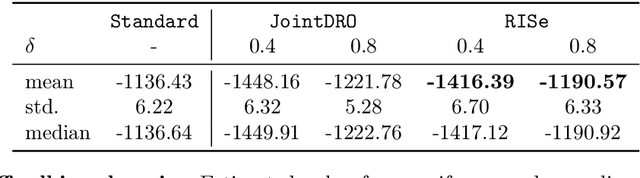
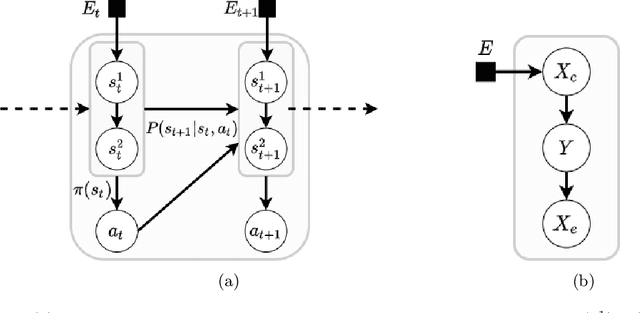
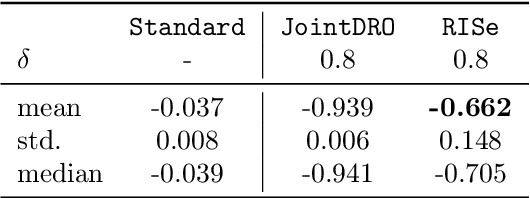
Machine learning models are often trained on data from one distribution and deployed on others. So it becomes important to design models that are robust to distribution shifts. Most of the existing work focuses on optimizing for either adversarial shifts or interventional shifts. Adversarial methods lack expressivity in representing plausible shifts as they consider shifts to joint distributions in the data. Interventional methods allow more expressivity but provide robustness to unbounded shifts, resulting in overly conservative models. In this work, we combine the complementary strengths of the two approaches and propose a new formulation, RISe, for designing robust models against a set of distribution shifts that are at the intersection of adversarial and interventional shifts. We employ the distributionally robust optimization framework to optimize the resulting objective in both supervised and reinforcement learning settings. Extensive experimentation with synthetic and real world datasets from healthcare demonstrate the efficacy of the proposed approach.
Towards Robust and Reliable Algorithmic Recourse
Feb 26, 2021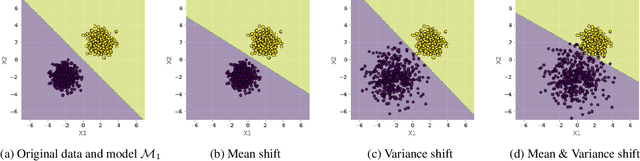
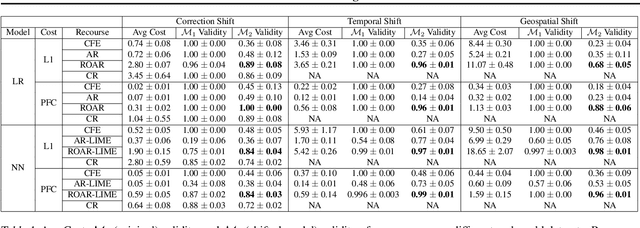
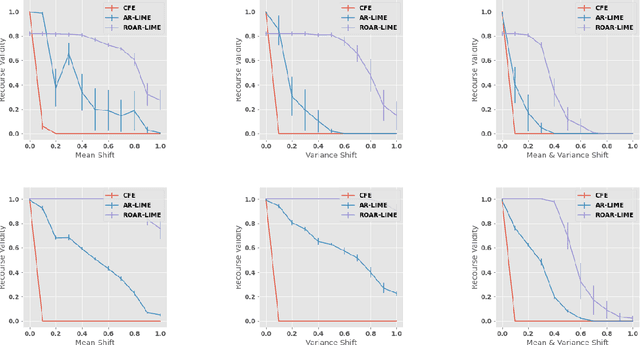
As predictive models are increasingly being deployed in high-stakes decision making (e.g., loan approvals), there has been growing interest in post hoc techniques which provide recourse to affected individuals. These techniques generate recourses under the assumption that the underlying predictive model does not change. However, in practice, models are often regularly updated for a variety of reasons (e.g., dataset shifts), thereby rendering previously prescribed recourses ineffective. To address this problem, we propose a novel framework, RObust Algorithmic Recourse (ROAR), that leverages adversarial training for finding recourses that are robust to model shifts. To the best of our knowledge, this work proposes the first solution to this critical problem. We also carry out detailed theoretical analysis which underscores the importance of constructing recourses that are robust to model shifts: 1) we derive a lower bound on the probability of invalidation of recourses generated by existing approaches which are not robust to model shifts. 2) we prove that the additional cost incurred due to the robust recourses output by our framework is bounded. Experimental evaluation on multiple synthetic and real-world datasets demonstrates the efficacy of the proposed framework and supports our theoretical findings.
Confounding Feature Acquisition for Causal Effect Estimation
Nov 17, 2020
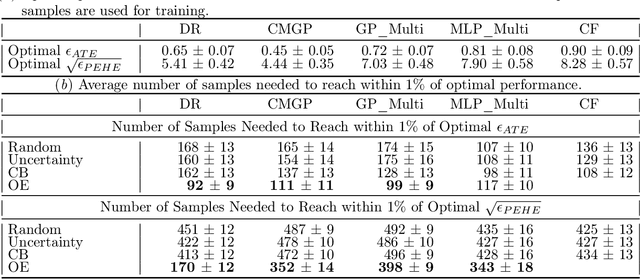
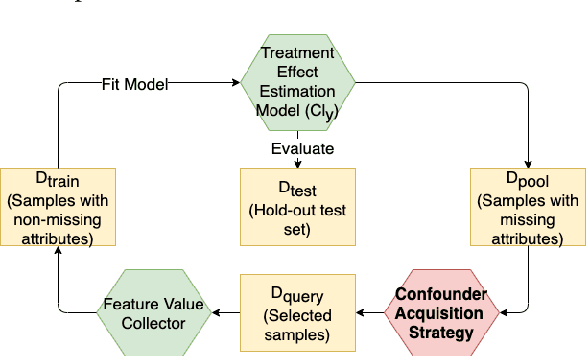

Reliable treatment effect estimation from observational data depends on the availability of all confounding information. While much work has targeted treatment effect estimation from observational data, there is relatively little work in the setting of confounding variable missingness, where collecting more information on confounders is often costly or time-consuming. In this work, we frame this challenge as a problem of feature acquisition of confounding features for causal inference. Our goal is to prioritize acquiring values for a fixed and known subset of missing confounders in samples that lead to efficient average treatment effect estimation. We propose two acquisition strategies based on i) covariate balancing (CB), and ii) reducing statistical estimation error on observed factual outcome error (OE). We compare CB and OE on five common causal effect estimation methods, and demonstrate improved sample efficiency of OE over baseline methods under various settings. We also provide visualizations for further analysis on the difference between our proposed methods.