 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows on Riemannian Manifolds
Nov 09, 2016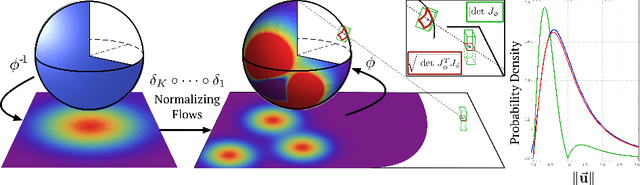
We consider the problem of density estimation on Riemannian manifolds. Density estimation on manifolds has many applications in fluid-mechanics, optics and plasma physics and it appears often when dealing with angular variables (such as used in protein folding, robot limbs, gene-expression) and in general directional statistics. In spite of the multitude of algorithms available for density estimation in the Euclidean spaces $\mathbf{R}^n$ that scale to large n (e.g. normalizing flows, kernel methods and variational approximations), most of these methods are not immediately suitable for density estimation in more general Riemannian manifolds. We revisit techniques related to homeomorphisms from differential geometry for projecting densities to sub-manifolds and use it to generalize the idea of normalizing flows to more general Riemannian manifolds. The resulting algorithm is scalable, simple to implement and suitable for use with automatic differentiation. We demonstrate concrete examples of this method on the n-sphere $\mathbf{S}^n$.
Early Visual Concept Learning with Unsupervised Deep Learning
Sep 20, 2016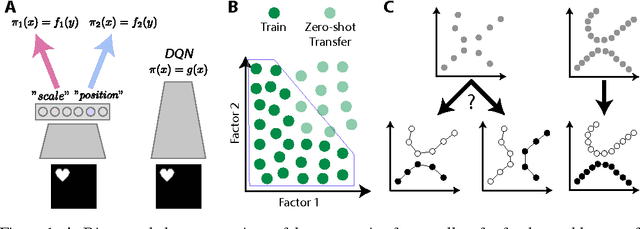
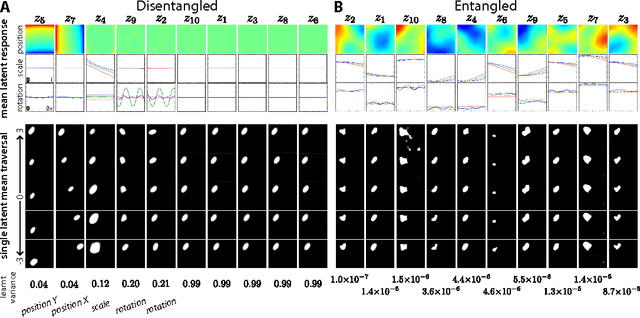

Automated discovery of early visual concepts from raw image data is a major open challenge in AI research. Addressing this problem, we propose an unsupervised approach for learning disentangled representations of the underlying factors of variation. We draw inspiration from neuroscience, and show how this can be achieved in an unsupervised generative model by applying the same learning pressures as have been suggested to act in the ventral visual stream in the brain. By enforcing redundancy reduction, encouraging statistical independence, and exposure to data with transform continuities analogous to those to which human infants are exposed, we obtain a variational autoencoder (VAE) framework capable of learning disentangled factors. Our approach makes few assumptions and works well across a wide variety of datasets. Furthermore, our solution has useful emergent properties, such as zero-shot inference and an intuitive understanding of "objectness".
Expectation Propagation in Gaussian Process Dynamical Systems: Extended Version
Aug 17, 2016
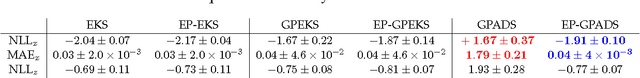

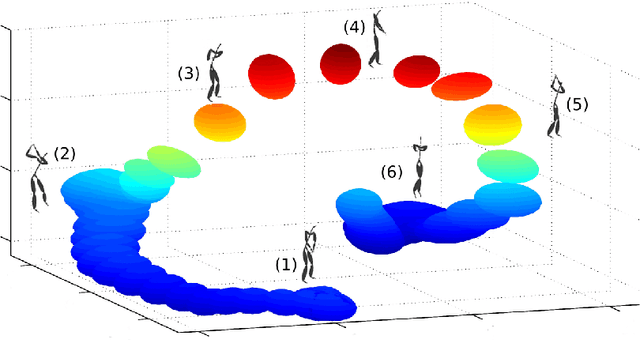
Rich and complex time-series data, such as those generated from engineering systems, financial markets, videos or neural recordings, are now a common feature of modern data analysis. Explaining the phenomena underlying these diverse data sets requires flexible and accurate models. In this paper, we promote Gaussian process dynamical systems (GPDS) as a rich model class that is appropriate for such analysis. In particular, we present a message passing algorithm for approximate inference in GPDSs based on expectation propagation. By posing inference as a general message passing problem, we iterate forward-backward smoothing. Thus, we obtain more accurate posterior distributions over latent structures, resulting in improved predictive performance compared to state-of-the-art GPDS smoothers, which are special cases of our general message passing algorithm. Hence, we provide a unifying approach within which to contextualize message passing in GPDSs.
Variational Inference with Normalizing Flows
Jun 14, 2016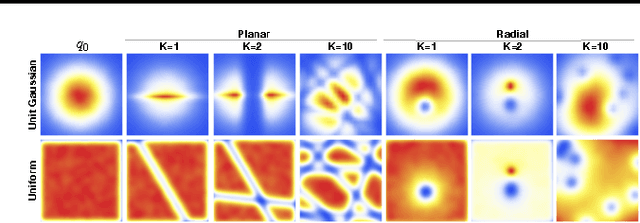
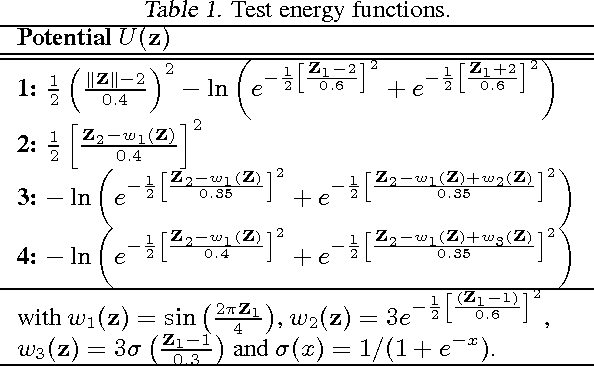
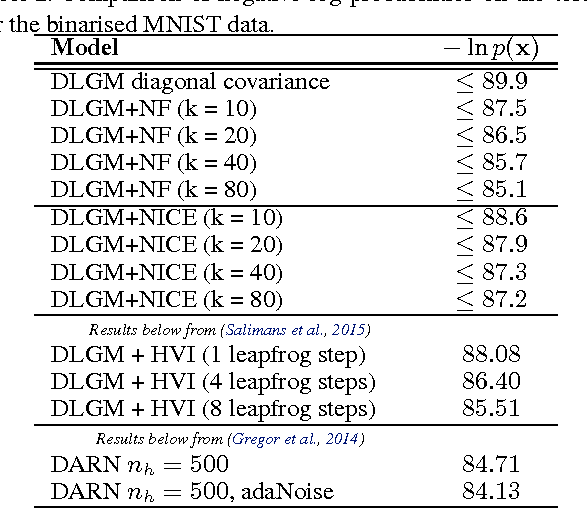
The choice of approximate posterior distribution is one of the core problems in variational inference. Most applications of variational inference employ simple families of posterior approximations in order to allow for efficient inference, focusing on mean-field or other simple structured approximations. This restriction has a significant impact on the quality of inferences made using variational methods. We introduce a new approach for specifying flexible, arbitrarily complex and scalable approximate posterior distributions. Our approximations are distributions constructed through a normalizing flow, whereby a simple initial density is transformed into a more complex one by applying a sequence of invertible transformations until a desired level of complexity is attained. We use this view of normalizing flows to develop categories of finite and infinitesimal flows and provide a unified view of approaches for constructing rich posterior approximations. We demonstrate that the theoretical advantages of having posteriors that better match the true posterior, combined with the scalability of amortized variational approaches, provides a clear improvement in performance and applicability of variational inference.
One-Shot Generalization in Deep Generative Models
May 25, 2016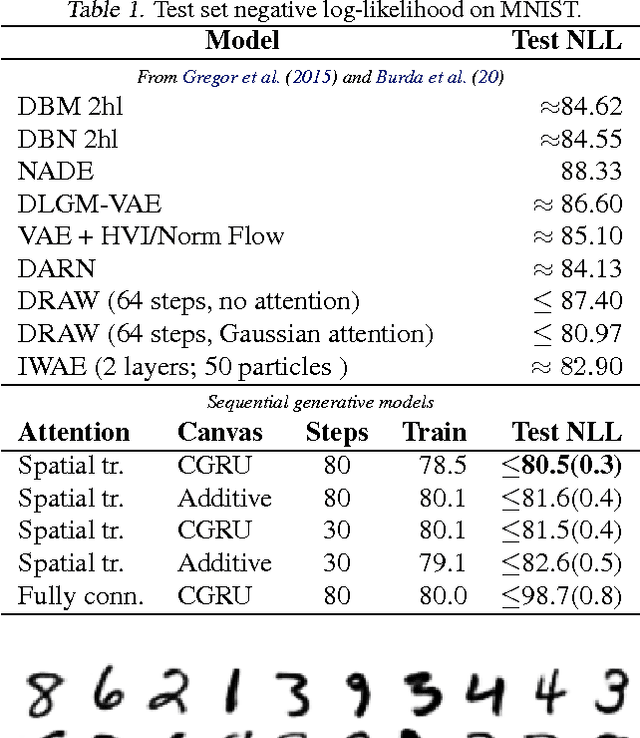
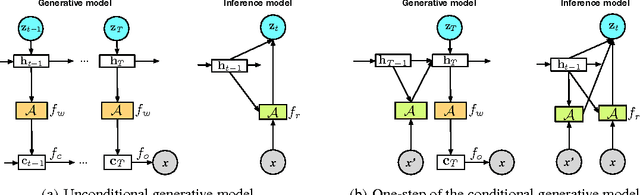
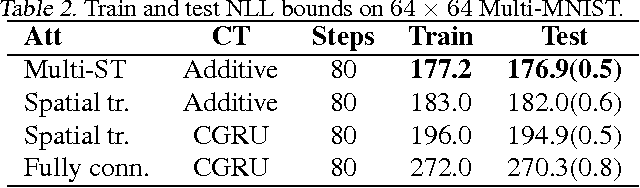
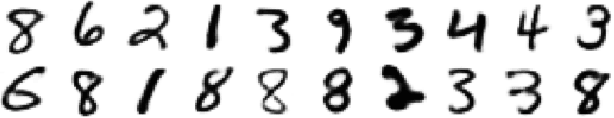
Humans have an impressive ability to reason about new concepts and experiences from just a single example. In particular, humans have an ability for one-shot generalization: an ability to encounter a new concept, understand its structure, and then be able to generate compelling alternative variations of the concept. We develop machine learning systems with this important capacity by developing new deep generative models, models that combine the representational power of deep learning with the inferential power of Bayesian reasoning. We develop a class of sequential generative models that are built on the principles of feedback and attention. These two characteristics lead to generative models that are among the state-of-the art in density estimation and image generation. We demonstrate the one-shot generalization ability of our models using three tasks: unconditional sampling, generating new exemplars of a given concept, and generating new exemplars of a family of concepts. In all cases our models are able to generate compelling and diverse samples---having seen new examples just once---providing an important class of general-purpose models for one-shot machine learning.
Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning
Sep 29, 2015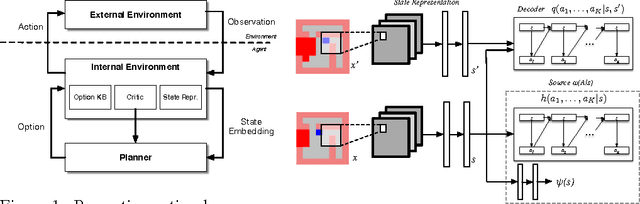


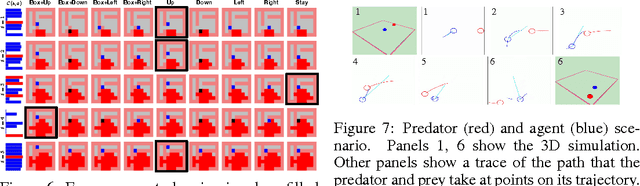
The mutual information is a core statistical quantity that has applications in all areas of machine learning, whether this is in training of density models over multiple data modalities, in maximising the efficiency of noisy transmission channels, or when learning behaviour policies for exploration by artificial agents. Most learning algorithms that involve optimisation of the mutual information rely on the Blahut-Arimoto algorithm --- an enumerative algorithm with exponential complexity that is not suitable for modern machine learning applications. This paper provides a new approach for scalable optimisation of the mutual information by merging techniques from variational inference and deep learning. We develop our approach by focusing on the problem of intrinsically-motivated learning, where the mutual information forms the definition of a well-known internal drive known as empowerment. Using a variational lower bound on the mutual information, combined with convolutional networks for handling visual input streams, we develop a stochastic optimisation algorithm that allows for scalable information maximisation and empowerment-based reasoning directly from pixels to actions.
Semi-Supervised Learning with Deep Generative Models
Oct 31, 2014


The ever-increasing size of modern data sets combined with the difficulty of obtaining label information has made semi-supervised learning one of the problems of significant practical importance in modern data analysis. We revisit the approach to semi-supervised learning with generative models and develop new models that allow for effective generalisation from small labelled data sets to large unlabelled ones. Generative approaches have thus far been either inflexible, inefficient or non-scalable. We show that deep generative models and approximate Bayesian inference exploiting recent advances in variational methods can be used to provide significant improvements, making generative approaches highly competitive for semi-supervised learning.
Stochastic Backpropagation and Approximate Inference in Deep Generative Models
May 30, 2014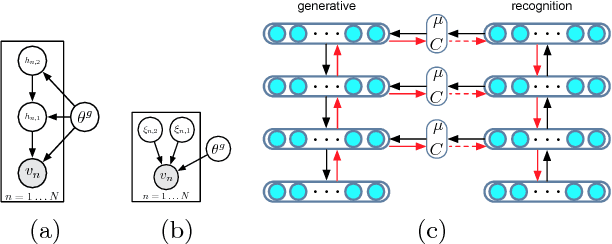



We marry ideas from deep neural networks and approximate Bayesian inference to derive a generalised class of deep, directed generative models, endowed with a new algorithm for scalable inference and learning. Our algorithm introduces a recognition model to represent approximate posterior distributions, and that acts as a stochastic encoder of the data. We develop stochastic back-propagation -- rules for back-propagation through stochastic variables -- and use this to develop an algorithm that allows for joint optimisation of the parameters of both the generative and recognition model. We demonstrate on several real-world data sets that the model generates realistic samples, provides accurate imputations of missing data and is a useful tool for high-dimensional data visualisation.
Bayesian and L1 Approaches to Sparse Unsupervised Learning
Aug 17, 2012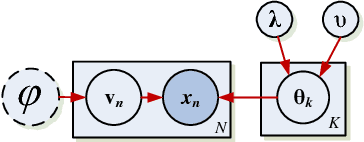
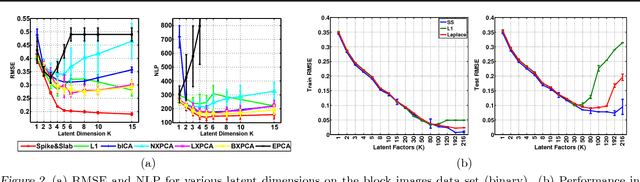
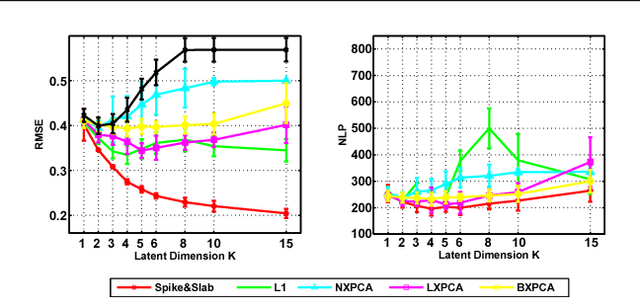
The use of L1 regularisation for sparse learning has generated immense research interest, with successful application in such diverse areas as signal acquisition, image coding, genomics and collaborative filtering. While existing work highlights the many advantages of L1 methods, in this paper we find that L1 regularisation often dramatically underperforms in terms of predictive performance when compared with other methods for inferring sparsity. We focus on unsupervised latent variable models, and develop L1 minimising factor models, Bayesian variants of "L1", and Bayesian models with a stronger L0-like sparsity induced through spike-and-slab distributions. These spike-and-slab Bayesian factor models encourage sparsity while accounting for uncertainty in a principled manner and avoiding unnecessary shrinkage of non-zero values. We demonstrate on a number of data sets that in practice spike-and-slab Bayesian methods outperform L1 minimisation, even on a computational budget. We thus highlight the need to re-assess the wide use of L1 methods in sparsity-reliant applications, particularly when we care about generalising to previously unseen data, and provide an alternative that, over many varying conditions, provides improved generalisation performance.