 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRISP: Curriculum based Sequential Neural Decoders for Polar Code Family
Oct 01, 2022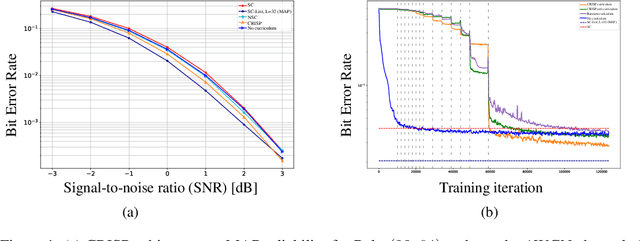
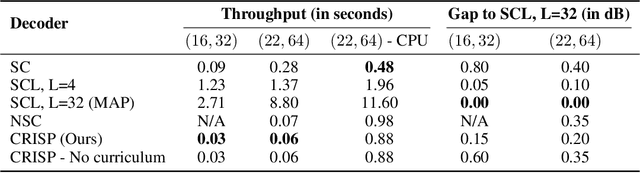
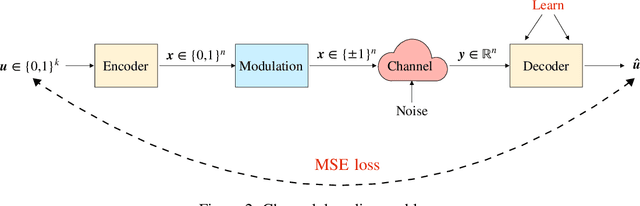
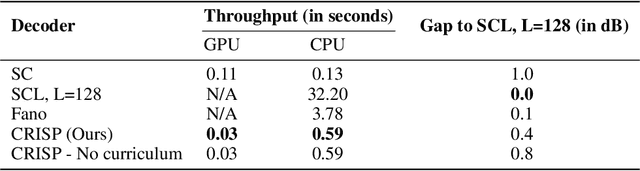
Polar codes are widely used state-of-the-art codes for reliable communication that have recently been included in the 5th generation wireless standards (5G). However, there remains room for the design of polar decoders that are both efficient and reliable in the short blocklength regime. Motivated by recent successes of data-driven channel decoders, we introduce a novel $\textbf{C}$ur$\textbf{RI}$culum based $\textbf{S}$equential neural decoder for $\textbf{P}$olar codes (CRISP). We design a principled curriculum, guided by information-theoretic insights, to train CRISP and show that it outperforms the successive-cancellation (SC) decoder and attains near-optimal reliability performance on the Polar(16,32) and Polar(22, 64) codes. The choice of the proposed curriculum is critical in achieving the accuracy gains of CRISP, as we show by comparing against other curricula. More notably, CRISP can be readily extended to Polarization-Adjusted-Convolutional (PAC) codes, where existing SC decoders are significantly less reliable. To the best of our knowledge, CRISP constructs the first data-driven decoder for PAC codes and attains near-optimal performance on the PAC(16, 32) code.
Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
Aug 10, 2022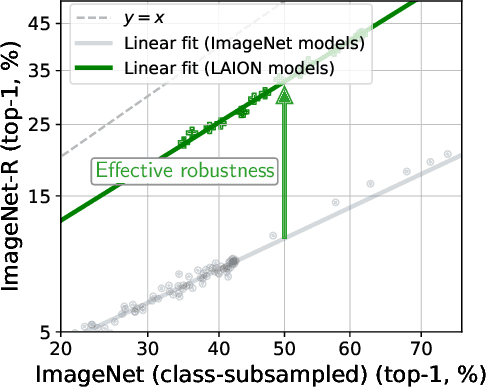

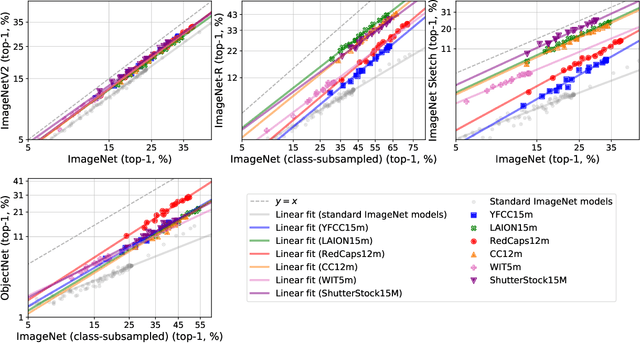
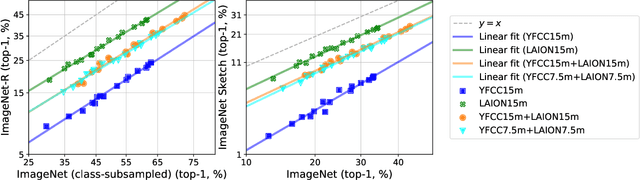
Web-crawled datasets have enabled remarkable generalization capabilities in recent image-text models such as CLIP (Contrastive Language-Image pre-training) or Flamingo, but little is known about the dataset creation processes. In this work, we introduce a testbed of six publicly available data sources - YFCC, LAION, Conceptual Captions, WIT, RedCaps, Shutterstock - to investigate how pre-training distributions induce robustness in CLIP. We find that the performance of the pre-training data varies substantially across distribution shifts, with no single data source dominating. Moreover, we systematically study the interactions between these data sources and find that combining multiple sources does not necessarily yield better models, but rather dilutes the robustness of the best individual data source. We complement our empirical findings with theoretical insights from a simple setting, where combining the training data also results in diluted robustness. In addition, our theoretical model provides a candidate explanation for the success of the CLIP-based data filtering technique recently employed in the LAION dataset. Overall our results demonstrate that simply gathering a large amount of data from the web is not the most effective way to build a pre-training dataset for robust generalization, necessitating further study into dataset design.
Bring Your Own Algorithm for Optimal Differentially Private Stochastic Minimax Optimization
Jun 01, 2022

We study differentially private (DP) algorithms for smooth stochastic minimax optimization, with stochastic minimization as a byproduct. The holy grail of these settings is to guarantee the optimal trade-off between the privacy and the excess population loss, using an algorithm with a linear time-complexity in the number of training samples. We provide a general framework for solving differentially private stochastic minimax optimization (DP-SMO) problems, which enables the practitioners to bring their own base optimization algorithm and use it as a black-box to obtain the near-optimal privacy-loss trade-off. Our framework is inspired from the recently proposed Phased-ERM method [20] for nonsmooth differentially private stochastic convex optimization (DP-SCO), which exploits the stability of the empirical risk minimization (ERM) for the privacy guarantee. The flexibility of our approach enables us to sidestep the requirement that the base algorithm needs to have bounded sensitivity, and allows the use of sophisticated variance-reduced accelerated methods to achieve near-linear time-complexity. To the best of our knowledge, these are the first linear-time optimal algorithms, up to logarithmic factors, for smooth DP-SMO when the objective is (strongly-)convex-(strongly-)concave. Additionally, based on our flexible framework, we derive a new family of near-linear time algorithms for smooth DP-SCO with optimal privacy-loss trade-offs for a wider range of smoothness parameters compared to previous algorithms.
Towards a Defense against Backdoor Attacks in Continual Federated Learning
May 28, 2022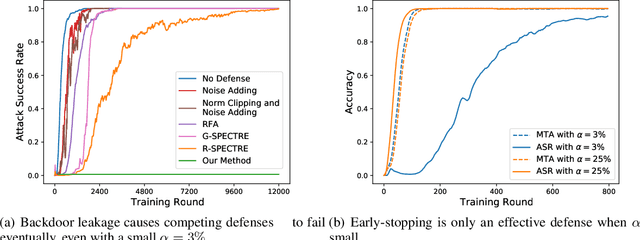

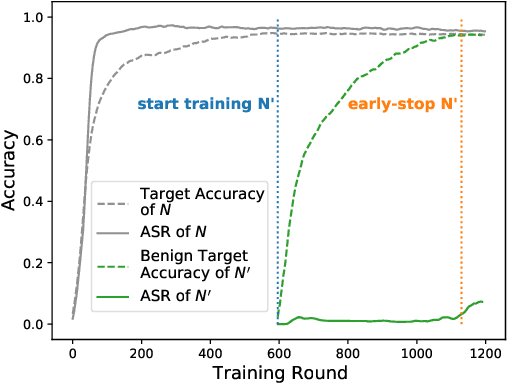

Backdoor attacks are a major concern in federated learning (FL) pipelines where training data is sourced from untrusted clients over long periods of time (i.e., continual learning). Preventing such attacks is difficult because defenders in FL do not have access to raw training data. Moreover, in a phenomenon we call backdoor leakage, models trained continuously eventually suffer from backdoors due to cumulative errors in backdoor defense mechanisms. We propose a novel framework for defending against backdoor attacks in the federated continual learning setting. Our framework trains two models in parallel: a backbone model and a shadow model. The backbone is trained without any defense mechanism to obtain good performance on the main task. The shadow model combines recent ideas from robust covariance estimation-based filters with early-stopping to control the attack success rate even as the data distribution changes. We provide theoretical motivation for this design and show experimentally that our framework significantly improves upon existing defenses against backdoor attacks.
DP-PCA: Statistically Optimal and Differentially Private PCA
May 27, 2022
We study the canonical statistical task of computing the principal component from $n$ i.i.d.~data in $d$ dimensions under $(\varepsilon,\delta)$-differential privacy. Although extensively studied in literature, existing solutions fall short on two key aspects: ($i$) even for Gaussian data, existing private algorithms require the number of samples $n$ to scale super-linearly with $d$, i.e., $n=\Omega(d^{3/2})$, to obtain non-trivial results while non-private PCA requires only $n=O(d)$, and ($ii$) existing techniques suffer from a non-vanishing error even when the randomness in each data point is arbitrarily small. We propose DP-PCA, which is a single-pass algorithm that overcomes both limitations. It is based on a private minibatch gradient ascent method that relies on {\em private mean estimation}, which adds minimal noise required to ensure privacy by adapting to the variance of a given minibatch of gradients. For sub-Gaussian data, we provide nearly optimal statistical error rates even for $n=\tilde O(d)$. Furthermore, we provide a lower bound showing that sub-Gaussian style assumption is necessary in obtaining the optimal error rate.
MAML and ANIL Provably Learn Representations
Feb 07, 2022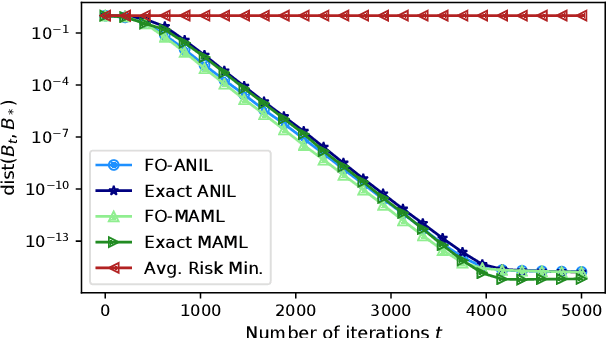
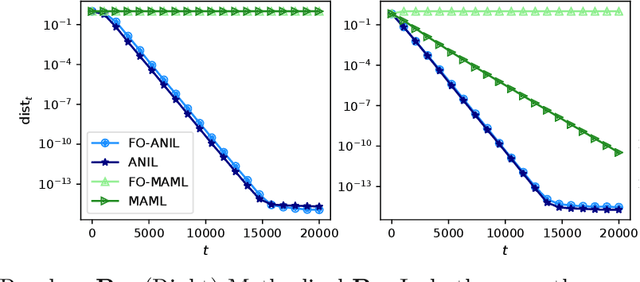
Recent empirical evidence has driven conventional wisdom to believe that gradient-based meta-learning (GBML) methods perform well at few-shot learning because they learn an expressive data representation that is shared across tasks. However, the mechanics of GBML have remained largely mysterious from a theoretical perspective. In this paper, we prove that two well-known GBML methods, MAML and ANIL, as well as their first-order approximations, are capable of learning common representation among a set of given tasks. Specifically, in the well-known multi-task linear representation learning setting, they are able to recover the ground-truth representation at an exponentially fast rate. Moreover, our analysis illuminates that the driving force causing MAML and ANIL to recover the underlying representation is that they adapt the final layer of their model, which harnesses the underlying task diversity to improve the representation in all directions of interest. To the best of our knowledge, these are the first results to show that MAML and/or ANIL learn expressive representations and to rigorously explain why they do so.
Lifted Primal-Dual Method for Bilinearly Coupled Smooth Minimax Optimization
Jan 19, 2022
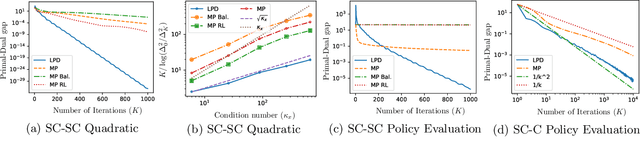
We study the bilinearly coupled minimax problem: $\min_{x} \max_{y} f(x) + y^\top A x - h(y)$, where $f$ and $h$ are both strongly convex smooth functions and admit first-order gradient oracles. Surprisingly, no known first-order algorithms have hitherto achieved the lower complexity bound of $\Omega((\sqrt{\frac{L_x}{\mu_x}} + \frac{\|A\|}{\sqrt{\mu_x \mu_y}} + \sqrt{\frac{L_y}{\mu_y}}) \log(\frac1{\varepsilon}))$ for solving this problem up to an $\varepsilon$ primal-dual gap in the general parameter regime, where $L_x, L_y,\mu_x,\mu_y$ are the corresponding smoothness and strongly convexity constants. We close this gap by devising the first optimal algorithm, the Lifted Primal-Dual (LPD) method. Our method lifts the objective into an extended form that allows both the smooth terms and the bilinear term to be handled optimally and seamlessly with the same primal-dual framework. Besides optimality, our method yields a desirably simple single-loop algorithm that uses only one gradient oracle call per iteration. Moreover, when $f$ is just convex, the same algorithm applied to a smoothed objective achieves the nearly optimal iteration complexity. We also provide a direct single-loop algorithm, using the LPD method, that achieves the iteration complexity of $O(\sqrt{\frac{L_x}{\varepsilon}} + \frac{\|A\|}{\sqrt{\mu_y \varepsilon}} + \sqrt{\frac{L_y}{\varepsilon}})$. Numerical experiments on quadratic minimax problems and policy evaluation problems further demonstrate the fast convergence of our algorithm in practice.
Gradient flows on graphons: existence, convergence, continuity equations
Nov 18, 2021
Wasserstein gradient flows on probability measures have found a host of applications in various optimization problems. They typically arise as the continuum limit of exchangeable particle systems evolving by some mean-field interaction involving a gradient-type potential. However, in many problems, such as in multi-layer neural networks, the so-called particles are edge weights on large graphs whose nodes are exchangeable. Such large graphs are known to converge to continuum limits called graphons as their size grow to infinity. We show that the Euclidean gradient flow of a suitable function of the edge-weights converges to a novel continuum limit given by a curve on the space of graphons that can be appropriately described as a gradient flow or, more technically, a curve of maximal slope. Several natural functions on graphons, such as homomorphism functions and the scalar entropy, are covered by our set-up, and the examples have been worked out in detail.
Differential privacy and robust statistics in high dimensions
Nov 12, 2021We introduce a universal framework for characterizing the statistical efficiency of a statistical estimation problem with differential privacy guarantees. Our framework, which we call High-dimensional Propose-Test-Release (HPTR), builds upon three crucial components: the exponential mechanism, robust statistics, and the Propose-Test-Release mechanism. Gluing all these together is the concept of resilience, which is central to robust statistical estimation. Resilience guides the design of the algorithm, the sensitivity analysis, and the success probability analysis of the test step in Propose-Test-Release. The key insight is that if we design an exponential mechanism that accesses the data only via one-dimensional robust statistics, then the resulting local sensitivity can be dramatically reduced. Using resilience, we can provide tight local sensitivity bounds. These tight bounds readily translate into near-optimal utility guarantees in several cases. We give a general recipe for applying HPTR to a given instance of a statistical estimation problem and demonstrate it on canonical problems of mean estimation, linear regression, covariance estimation, and principal component analysis. We introduce a general utility analysis technique that proves that HPTR nearly achieves the optimal sample complexity under several scenarios studied in the literature.
Gradient Inversion with Generative Image Prior
Oct 28, 2021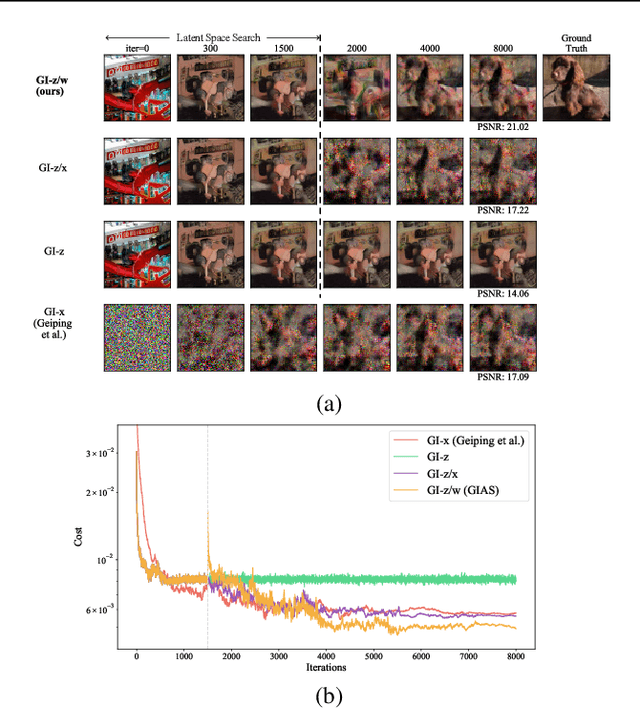

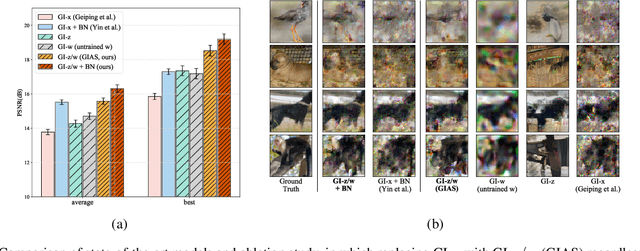
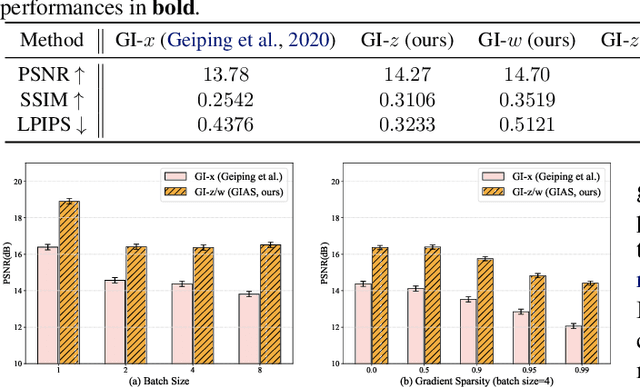
Federated Learning (FL) is a distributed learning framework, in which the local data never leaves clients devices to preserve privacy, and the server trains models on the data via accessing only the gradients of those local data. Without further privacy mechanisms such as differential privacy, this leaves the system vulnerable against an attacker who inverts those gradients to reveal clients sensitive data. However, a gradient is often insufficient to reconstruct the user data without any prior knowledge. By exploiting a generative model pretrained on the data distribution, we demonstrate that data privacy can be easily breached. Further, when such prior knowledge is unavailable, we investigate the possibility of learning the prior from a sequence of gradients seen in the process of FL training. We experimentally show that the prior in a form of generative model is learnable from iterative interactions in FL. Our findings strongly suggest that additional mechanisms are necessary to prevent privacy leakage in FL.