 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Machine Learning
May 10, 2018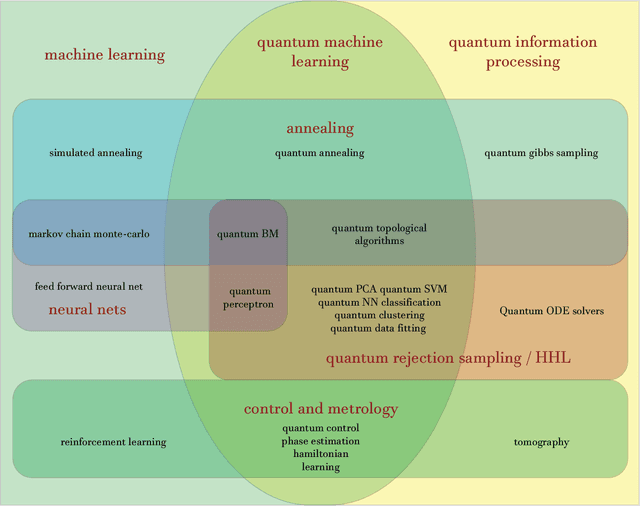
Fuelled by increasing computer power and algorithmic advances, machine learning techniques have become powerful tools for finding patterns in data. Since quantum systems produce counter-intuitive patterns believed not to be efficiently produced by classical systems, it is reasonable to postulate that quantum computers may outperform classical computers on machine learning tasks. The field of quantum machine learning explores how to devise and implement concrete quantum software that offers such advantages. Recent work has made clear that the hardware and software challenges are still considerable but has also opened paths towards solutions.
* 24 pages, 2 figures
Quantum support vector machine for big data classification
Jul 10, 2014Supervised machine learning is the classification of new data based on already classified training examples. In this work, we show that the support vector machine, an optimized binary classifier, can be implemented on a quantum computer, with complexity logarithmic in the size of the vectors and the number of training examples. In cases when classical sampling algorithms require polynomial time, an exponential speed-up is obtained. At the core of this quantum big data algorithm is a non-sparse matrix exponentiation technique for efficiently performing a matrix inversion of the training data inner-product (kernel) matrix.
* 5 pages
A Turing test for free will
Oct 11, 2013Before Alan Turing made his crucial contributions to the theory of computation, he studied the question of whether quantum mechanics could throw light on the nature of free will. This article investigates the roles of quantum mechanics and computation in free will. Although quantum mechanics implies that events are intrinsically unpredictable, the `pure stochasticity' of quantum mechanics adds only randomness to decision making processes, not freedom. By contrast, the theory of computation implies that even when our decisions arise from a completely deterministic decision-making process, the outcomes of that process can be intrinsically unpredictable, even to -- especially to -- ourselves. I argue that this intrinsic computational unpredictability of the decision making process is what give rise to our impression that we possess free will. Finally, I propose a `Turing test' for free will: a decision maker who passes this test will tend to believe that he, she, or it possesses free will, whether the world is deterministic or not.
* 20 pages, plain TeX