 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Illumination Decomposition Model for Multi-Illuminant White Balancing
Feb 28, 2024



White balance (WB) algorithms in many commercial cameras assume single and uniform illumination, leading to undesirable results when multiple lighting sources with different chromaticities exist in the scene. Prior research on multi-illuminant WB typically predicts illumination at the pixel level without fully grasping the scene's actual lighting conditions, including the number and color of light sources. This often results in unnatural outcomes lacking in overall consistency. To handle this problem, we present a deep white balancing model that leverages the slot attention, where each slot is in charge of representing individual illuminants. This design enables the model to generate chromaticities and weight maps for individual illuminants, which are then fused to compose the final illumination map. Furthermore, we propose the centroid-matching loss, which regulates the activation of each slot based on the color range, thereby enhancing the model to separate illumination more effectively. Our method achieves the state-of-the-art performance on both single- and multi-illuminant WB benchmarks, and also offers additional information such as the number of illuminants in the scene and their chromaticity. This capability allows for illumination editing, an application not feasible with prior methods.
VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement
Dec 08, 2023In recent years, online Video Instance Segmentation (VIS) methods have shown remarkable advancement with their powerful query-based detectors. Utilizing the output queries of the detector at the frame level, these methods achieve high accuracy on challenging benchmarks. However, we observe the heavy reliance of these methods on the location information that leads to incorrect matching when positional cues are insufficient for resolving ambiguities. Addressing this issue, we present VISAGE that enhances instance association by explicitly leveraging appearance information. Our method involves a generation of queries that embed appearances from backbone feature maps, which in turn get used in our suggested simple tracker for robust associations. Finally, enabling accurate matching in complex scenarios by resolving the issue of over-reliance on location information, we achieve competitive performance on multiple VIS benchmarks. For instance, on YTVIS19 and YTVIS21, our method achieves 54.5 AP and 50.8 AP. Furthermore, to highlight appearance-awareness not fully addressed by existing benchmarks, we generate a synthetic dataset where our method outperforms others significantly by leveraging the appearance cue. Code will be made available at https://github.com/KimHanjung/VISAGE.
Towards Interpretable Controllability in Object-Centric Learning
Oct 16, 2023The binding problem in artificial neural networks is actively explored with the goal of achieving human-level recognition skills through the comprehension of the world in terms of symbol-like entities. Especially in the field of computer vision, object-centric learning (OCL) is extensively researched to better understand complex scenes by acquiring object representations or slots. While recent studies in OCL have made strides with complex images or videos, the interpretability and interactivity over object representation remain largely uncharted, still holding promise in the field of OCL. In this paper, we introduce a novel method, Slot Attention with Image Augmentation (SlotAug), to explore the possibility of learning interpretable controllability over slots in a self-supervised manner by utilizing an image augmentation strategy. We also devise the concept of sustainability in controllable slots by introducing iterative and reversible controls over slots with two proposed submethods: Auxiliary Identity Manipulation and Slot Consistency Loss. Extensive empirical studies and theoretical validation confirm the effectiveness of our approach, offering a novel capability for interpretable and sustainable control of object representations. Code will be available soon.
Domain Reduction Strategy for Non Line of Sight Imaging
Aug 20, 2023



This paper presents a novel optimization-based method for non-line-of-sight (NLOS) imaging that aims to reconstruct hidden scenes under various setups. Our method is built upon the observation that photons returning from each point in hidden volumes can be independently computed if the interactions between hidden surfaces are trivially ignored. We model the generalized light propagation function to accurately represent the transients as a linear combination of these functions. Moreover, our proposed method includes a domain reduction procedure to exclude empty areas of the hidden volumes from the set of propagation functions, thereby improving computational efficiency of the optimization. We demonstrate the effectiveness of the method in various NLOS scenarios, including non-planar relay wall, sparse scanning patterns, confocal and non-confocal, and surface geometry reconstruction. Experiments conducted on both synthetic and real-world data clearly support the superiority and the efficiency of the proposed method in general NLOS scenarios.
Shepherding Slots to Objects: Towards Stable and Robust Object-Centric Learning
Mar 31, 2023



Object-centric learning (OCL) aspires general and compositional understanding of scenes by representing a scene as a collection of object-centric representations. OCL has also been extended to multi-view image and video datasets to apply various data-driven inductive biases by utilizing geometric or temporal information in the multi-image data. Single-view images carry less information about how to disentangle a given scene than videos or multi-view images do. Hence, owing to the difficulty of applying inductive biases, OCL for single-view images remains challenging, resulting in inconsistent learning of object-centric representation. To this end, we introduce a novel OCL framework for single-view images, SLot Attention via SHepherding (SLASH), which consists of two simple-yet-effective modules on top of Slot Attention. The new modules, Attention Refining Kernel (ARK) and Intermediate Point Predictor and Encoder (IPPE), respectively, prevent slots from being distracted by the background noise and indicate locations for slots to focus on to facilitate learning of object-centric representation. We also propose a weak semi-supervision approach for OCL, whilst our proposed framework can be used without any assistant annotation during the inference. Experiments show that our proposed method enables consistent learning of object-centric representation and achieves strong performance across four datasets. Code is available at \url{https://github.com/object-understanding/SLASH}.
ComMU: Dataset for Combinatorial Music Generation
Nov 17, 2022



Commercial adoption of automatic music composition requires the capability of generating diverse and high-quality music suitable for the desired context (e.g., music for romantic movies, action games, restaurants, etc.). In this paper, we introduce combinatorial music generation, a new task to create varying background music based on given conditions. Combinatorial music generation creates short samples of music with rich musical metadata, and combines them to produce a complete music. In addition, we introduce ComMU, the first symbolic music dataset consisting of short music samples and their corresponding 12 musical metadata for combinatorial music generation. Notable properties of ComMU are that (1) dataset is manually constructed by professional composers with an objective guideline that induces regularity, and (2) it has 12 musical metadata that embraces composers' intentions. Our results show that we can generate diverse high-quality music only with metadata, and that our unique metadata such as track-role and extended chord quality improves the capacity of the automatic composition. We highly recommend watching our video before reading the paper (https://pozalabs.github.io/ComMU).
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022



Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
Soft-Landing Strategy for Alleviating the Task Discrepancy Problem in Temporal Action Localization Tasks
Nov 11, 2022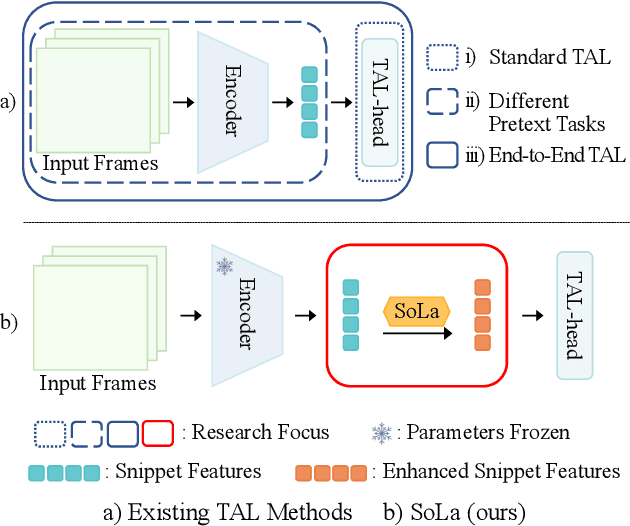
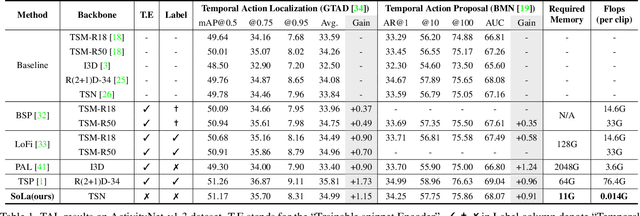
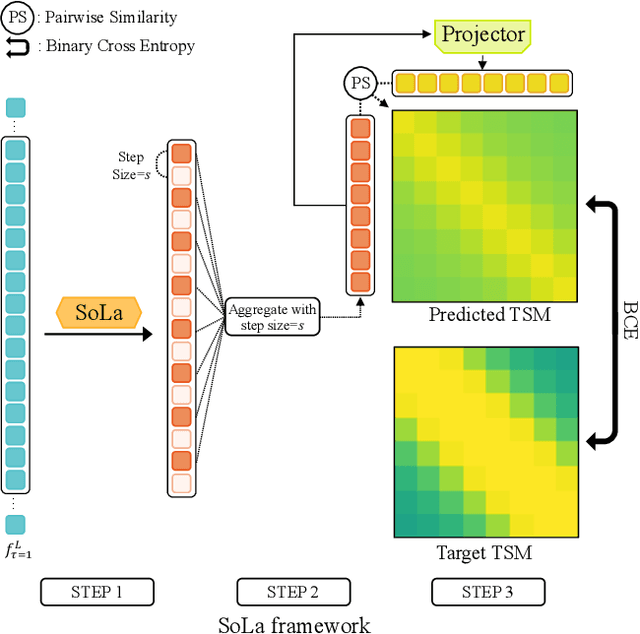
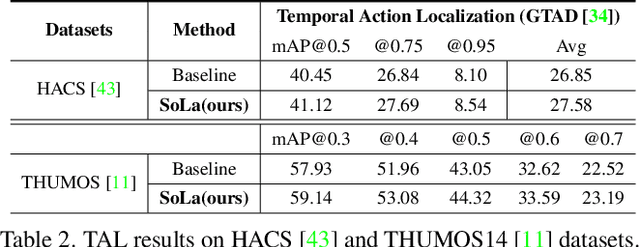
Temporal Action Localization (TAL) methods typically operate on top of feature sequences from a frozen snippet encoder that is pretrained with the Trimmed Action Classification (TAC) tasks, resulting in a task discrepancy problem. While existing TAL methods mitigate this issue either by retraining the encoder with a pretext task or by end-to-end fine-tuning, they commonly require an overload of high memory and computation. In this work, we introduce Soft-Landing (SoLa) strategy, an efficient yet effective framework to bridge the transferability gap between the pretrained encoder and the downstream tasks by incorporating a light-weight neural network, i.e., a SoLa module, on top of the frozen encoder. We also propose an unsupervised training scheme for the SoLa module; it learns with inter-frame Similarity Matching that uses the frame interval as its supervisory signal, eliminating the need for temporal annotations. Experimental evaluation on various benchmarks for downstream TAL tasks shows that our method effectively alleviates the task discrepancy problem with remarkable computational efficiency.
Error Compensation Framework for Flow-Guided Video Inpainting
Jul 21, 2022
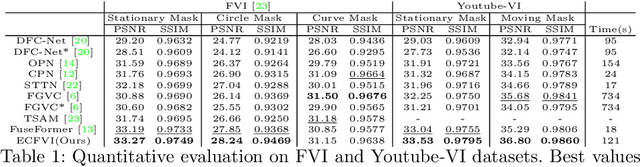


The key to video inpainting is to use correlation information from as many reference frames as possible. Existing flow-based propagation methods split the video synthesis process into multiple steps: flow completion -> pixel propagation -> synthesis. However, there is a significant drawback that the errors in each step continue to accumulate and amplify in the next step. To this end, we propose an Error Compensation Framework for Flow-guided Video Inpainting (ECFVI), which takes advantage of the flow-based method and offsets its weaknesses. We address the weakness with the newly designed flow completion module and the error compensation network that exploits the error guidance map. Our approach greatly improves the temporal consistency and the visual quality of the completed videos. Experimental results show the superior performance of our proposed method with the speed up of x6, compared to the state-of-the-art methods. In addition, we present a new benchmark dataset for evaluation by supplementing the weaknesses of existing test datasets.
VITA: Video Instance Segmentation via Object Token Association
Jun 09, 2022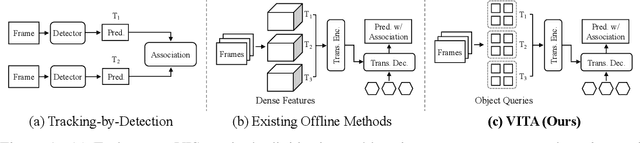
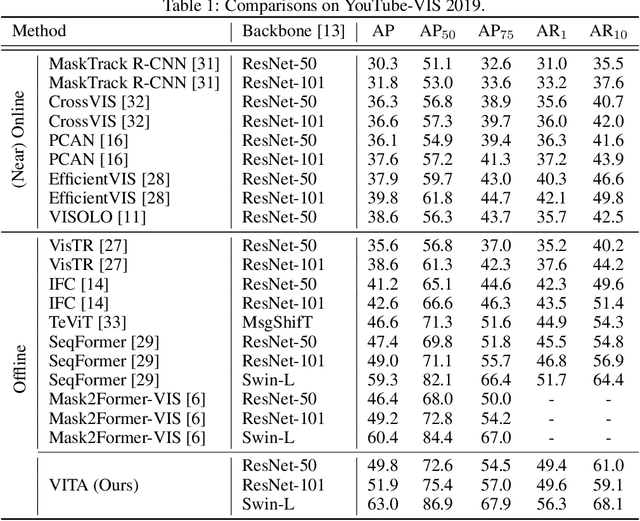
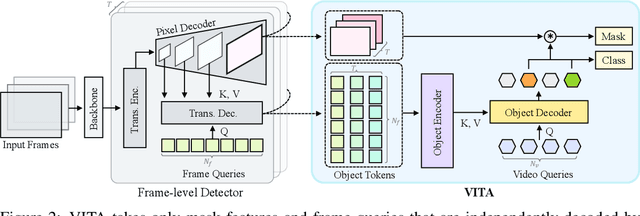
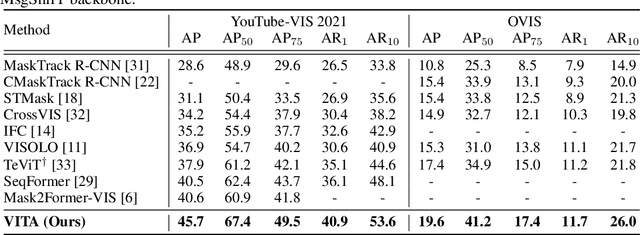
We introduce a novel paradigm for offline Video Instance Segmentation (VIS), based on the hypothesis that explicit object-oriented information can be a strong clue for understanding the context of the entire sequence. To this end, we propose VITA, a simple structure built on top of an off-the-shelf Transformer-based image instance segmentation model. Specifically, we use an image object detector as a means of distilling object-specific contexts into object tokens. VITA accomplishes video-level understanding by associating frame-level object tokens without using spatio-temporal backbone features. By effectively building relationships between objects using the condensed information, VITA achieves the state-of-the-art on VIS benchmarks with a ResNet-50 backbone: 49.8 AP, 45.7 AP on YouTube-VIS 2019 & 2021 and 19.6 AP on OVIS. Moreover, thanks to its object token-based structure that is disjoint from the backbone features, VITA shows several practical advantages that previous offline VIS methods have not explored - handling long and high-resolution videos with a common GPU and freezing a frame-level detector trained on image domain. Code will be made available at https://github.com/sukjunhwang/VITA.