 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular 3D Keypoint Discovery from Multi-View Diffusion Priors
Jul 16, 2025This paper introduces KeyDiff3D, a framework for unsupervised monocular 3D keypoints estimation that accurately predicts 3D keypoints from a single image. While previous methods rely on manual annotations or calibrated multi-view images, both of which are expensive to collect, our method enables monocular 3D keypoints estimation using only a collection of single-view images. To achieve this, we leverage powerful geometric priors embedded in a pretrained multi-view diffusion model. In our framework, this model generates multi-view images from a single image, serving as a supervision signal to provide 3D geometric cues to our model. We also use the diffusion model as a powerful 2D multi-view feature extractor and construct 3D feature volumes from its intermediate representations. This transforms implicit 3D priors learned by the diffusion model into explicit 3D features. Beyond accurate keypoints estimation, we further introduce a pipeline that enables manipulation of 3D objects generated by the diffusion model. Experimental results on diverse aspects and datasets, including Human3.6M, Stanford Dogs, and several in-the-wild and out-of-domain datasets, highlight the effectiveness of our method in terms of accuracy, generalization, and its ability to enable manipulation of 3D objects generated by the diffusion model from a single image.
Representing 3D Shapes With 64 Latent Vectors for 3D Diffusion Models
Mar 11, 2025Constructing a compressed latent space through a variational autoencoder (VAE) is the key for efficient 3D diffusion models. This paper introduces COD-VAE, a VAE that encodes 3D shapes into a COmpact set of 1D latent vectors without sacrificing quality. COD-VAE introduces a two-stage autoencoder scheme to improve compression and decoding efficiency. First, our encoder block progressively compresses point clouds into compact latent vectors via intermediate point patches. Second, our triplane-based decoder reconstructs dense triplanes from latent vectors instead of directly decoding neural fields, significantly reducing computational overhead of neural fields decoding. Finally, we propose uncertainty-guided token pruning, which allocates resources adaptively by skipping computations in simpler regions and improves the decoder efficiency. Experimental results demonstrate that COD-VAE achieves 16x compression compared to the baseline while maintaining quality. This enables 20.8x speedup in generation, highlighting that a large number of latent vectors is not a prerequisite for high-quality reconstruction and generation.
4D Scaffold Gaussian Splatting for Memory Efficient Dynamic Scene Reconstruction
Nov 26, 2024



Existing 4D Gaussian methods for dynamic scene reconstruction offer high visual fidelity and fast rendering. However, these methods suffer from excessive memory and storage demands, which limits their practical deployment. This paper proposes a 4D anchor-based framework that retains visual quality and rendering speed of 4D Gaussians while significantly reducing storage costs. Our method extends 3D scaffolding to 4D space, and leverages sparse 4D grid-aligned anchors with compressed feature vectors. Each anchor models a set of neural 4D Gaussians, each of which represent a local spatiotemporal region. In addition, we introduce a temporal coverage-aware anchor growing strategy to effectively assign additional anchors to under-reconstructed dynamic regions. Our method adjusts the accumulated gradients based on Gaussians' temporal coverage, improving reconstruction quality in dynamic regions. To reduce the number of anchors, we further present enhanced formulations of neural 4D Gaussians. These include the neural velocity, and the temporal opacity derived from a generalized Gaussian distribution. Experimental results demonstrate that our method achieves state-of-the-art visual quality and 97.8% storage reduction over 4DGS.
Hierarchically Structured Neural Bones for Reconstructing Animatable Objects from Casual Videos
Aug 01, 2024



We propose a new framework for creating and easily manipulating 3D models of arbitrary objects using casually captured videos. Our core ingredient is a novel hierarchy deformation model, which captures motions of objects with a tree-structured bones. Our hierarchy system decomposes motions based on the granularity and reveals the correlations between parts without exploiting any prior structural knowledge. We further propose to regularize the bones to be positioned at the basis of motions, centers of parts, sufficiently covering related surfaces of the part. This is achieved by our bone occupancy function, which identifies whether a given 3D point is placed within the bone. Coupling the proposed components, our framework offers several clear advantages: (1) users can obtain animatable 3D models of the arbitrary objects in improved quality from their casual videos, (2) users can manipulate 3D models in an intuitive manner with minimal costs, and (3) users can interactively add or delete control points as necessary. The experimental results demonstrate the efficacy of our framework on diverse instances, in reconstruction quality, interpretability and easier manipulation. Our code is available at https://github.com/subin6/HSNB.
Learning to Enhance Aperture Phasor Field for Non-Line-of-Sight Imaging
Jul 29, 2024



This paper aims to facilitate more practical NLOS imaging by reducing the number of samplings and scan areas. To this end, we introduce a phasor-based enhancement network that is capable of predicting clean and full measurements from noisy partial observations. We leverage a denoising autoencoder scheme to acquire rich and noise-robust representations in the measurement space. Through this pipeline, our enhancement network is trained to accurately reconstruct complete measurements from their corrupted and partial counterparts. However, we observe that the \naive application of denoising often yields degraded and over-smoothed results, caused by unnecessary and spurious frequency signals present in measurements. To address this issue, we introduce a phasor-based pipeline designed to limit the spectrum of our network to the frequency range of interests, where the majority of informative signals are detected. The phasor wavefronts at the aperture, which are band-limited signals, are employed as inputs and outputs of the network, guiding our network to learn from the frequency range of interests and discard unnecessary information. The experimental results in more practical acquisition scenarios demonstrate that we can look around the corners with $16\times$ or $64\times$ fewer samplings and $4\times$ smaller apertures. Our code is available at https://github.com/join16/LEAP.
Domain Reduction Strategy for Non Line of Sight Imaging
Aug 20, 2023



This paper presents a novel optimization-based method for non-line-of-sight (NLOS) imaging that aims to reconstruct hidden scenes under various setups. Our method is built upon the observation that photons returning from each point in hidden volumes can be independently computed if the interactions between hidden surfaces are trivially ignored. We model the generalized light propagation function to accurately represent the transients as a linear combination of these functions. Moreover, our proposed method includes a domain reduction procedure to exclude empty areas of the hidden volumes from the set of propagation functions, thereby improving computational efficiency of the optimization. We demonstrate the effectiveness of the method in various NLOS scenarios, including non-planar relay wall, sparse scanning patterns, confocal and non-confocal, and surface geometry reconstruction. Experiments conducted on both synthetic and real-world data clearly support the superiority and the efficiency of the proposed method in general NLOS scenarios.
Unsupervised Keypoint Learning for Guiding Class-Conditional Video Prediction
Oct 04, 2019

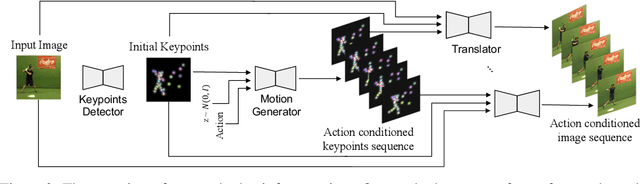
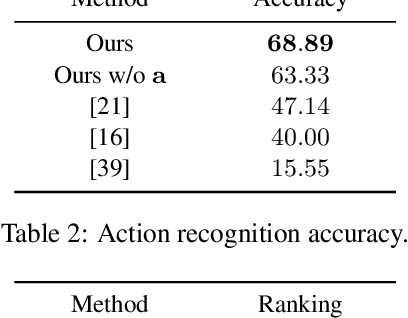
We propose a deep video prediction model conditioned on a single image and an action class. To generate future frames, we first detect keypoints of a moving object and predict future motion as a sequence of keypoints. The input image is then translated following the predicted keypoints sequence to compose future frames. Detecting the keypoints is central to our algorithm, and our method is trained to detect the keypoints of arbitrary objects in an unsupervised manner. Moreover, the detected keypoints of the original videos are used as pseudo-labels to learn the motion of objects. Experimental results show that our method is successfully applied to various datasets without the cost of labeling keypoints in videos. The detected keypoints are similar to human-annotated labels, and prediction results are more realistic compared to the previous methods.