 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Dec 07, 2023



In this study, we explore Transformer-based diffusion models for image and video generation. Despite the dominance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particularly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text conditioning, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, underscoring its strengths in compositional generation. We believe this work will provide meaningful insights and serve as a valuable reference for future research.
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing
Oct 09, 2023



Text-to-video editing aims to edit the visual appearance of a source video conditional on textual prompts. A major challenge in this task is to ensure that all frames in the edited video are visually consistent. Most recent works apply advanced text-to-image diffusion models to this task by inflating 2D spatial attention in the U-Net into spatio-temporal attention. Although temporal context can be added through spatio-temporal attention, it may introduce some irrelevant information for each patch and therefore cause inconsistency in the edited video. In this paper, for the first time, we introduce optical flow into the attention module in the diffusion model's U-Net to address the inconsistency issue for text-to-video editing. Our method, FLATTEN, enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency in the edited videos. Additionally, our method is training-free and can be seamlessly integrated into any diffusion-based text-to-video editing methods and improve their visual consistency. Experiment results on existing text-to-video editing benchmarks show that our proposed method achieves the new state-of-the-art performance. In particular, our method excels in maintaining the visual consistency in the edited videos.
Learning Garment DensePose for Robust Warping in Virtual Try-On
Mar 30, 2023


Virtual try-on, i.e making people virtually try new garments, is an active research area in computer vision with great commercial applications. Current virtual try-on methods usually work in a two-stage pipeline. First, the garment image is warped on the person's pose using a flow estimation network. Then in the second stage, the warped garment is fused with the person image to render a new try-on image. Unfortunately, such methods are heavily dependent on the quality of the garment warping which often fails when dealing with hard poses (e.g., a person lifting or crossing arms). In this work, we propose a robust warping method for virtual try-on based on a learned garment DensePose which has a direct correspondence with the person's DensePose. Due to the lack of annotated data, we show how to leverage an off-the-shelf person DensePose model and a pretrained flow model to learn the garment DensePose in a weakly supervised manner. The garment DensePose allows a robust warping to any person's pose without any additional computation. Our method achieves the state-of-the-art equivalent on virtual try-on benchmarks and shows warping robustness on in-the-wild person images with hard poses, making it more suited for real-world virtual try-on applications.
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Jan 06, 2023



Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
Single Stage Multi-Pose Virtual Try-On
Nov 19, 2022Multi-pose virtual try-on (MPVTON) aims to fit a target garment onto a person at a target pose. Compared to traditional virtual try-on (VTON) that fits the garment but keeps the pose unchanged, MPVTON provides a better try-on experience, but is also more challenging due to the dual garment and pose editing objectives. Existing MPVTON methods adopt a pipeline comprising three disjoint modules including a target semantic layout prediction module, a coarse try-on image generator and a refinement try-on image generator. These models are trained separately, leading to sub-optimal model training and unsatisfactory results. In this paper, we propose a novel single stage model for MPVTON. Key to our model is a parallel flow estimation module that predicts the flow fields for both person and garment images conditioned on the target pose. The predicted flows are subsequently used to warp the appearance feature maps of the person and the garment images to construct a style map. The map is then used to modulate the target pose's feature map for target try-on image generation. With the parallel flow estimation design, our model can be trained end-to-end in a single stage and is more computationally efficient, resulting in new SOTA performance on existing MPVTON benchmarks. We further introduce multi-task training and demonstrate that our model can also be applied for traditional VTON and pose transfer tasks and achieve comparable performance to SOTA specialized models on both tasks.
Prediction Calibration for Generalized Few-shot Semantic Segmentation
Oct 15, 2022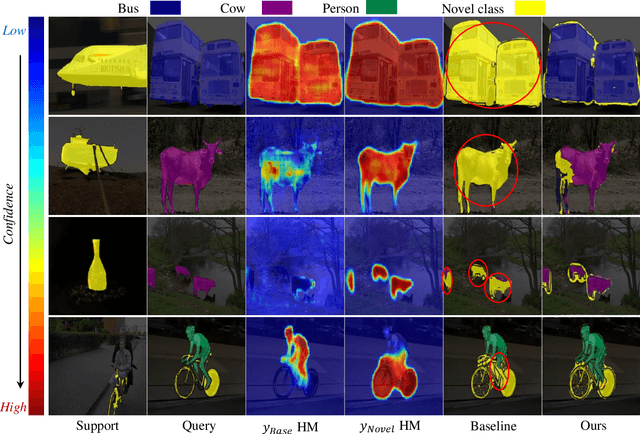
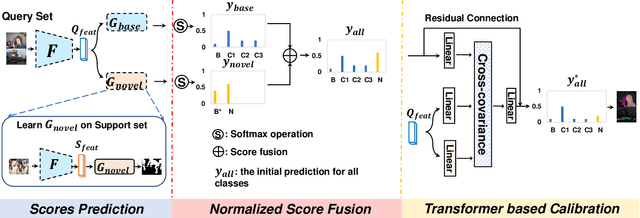

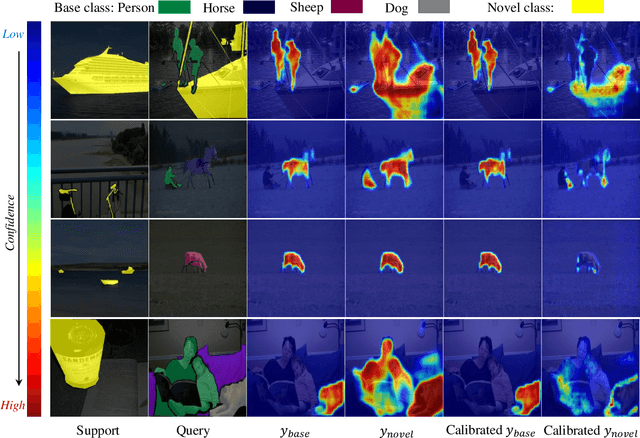
Generalized Few-shot Semantic Segmentation (GFSS) aims to segment each image pixel into either base classes with abundant training examples or novel classes with only a handful of (e.g., 1-5) training images per class. Compared to the widely studied Few-shot Semantic Segmentation FSS, which is limited to segmenting novel classes only, GFSS is much under-studied despite being more practical. Existing approach to GFSS is based on classifier parameter fusion whereby a newly trained novel class classifier and a pre-trained base class classifier are combined to form a new classifier. As the training data is dominated by base classes, this approach is inevitably biased towards the base classes. In this work, we propose a novel Prediction Calibration Network PCN to address this problem. Instead of fusing the classifier parameters, we fuse the scores produced separately by the base and novel classifiers. To ensure that the fused scores are not biased to either the base or novel classes, a new Transformer-based calibration module is introduced. It is known that the lower-level features are useful of detecting edge information in an input image than higher-level features. Thus, we build a cross-attention module that guides the classifier's final prediction using the fused multi-level features. However, transformers are computationally demanding. Crucially, to make the proposed cross-attention module training tractable at the pixel level, this module is designed based on feature-score cross-covariance and episodically trained to be generalizable at inference time. Extensive experiments on PASCAL-$5^{i}$ and COCO-$20^{i}$ show that our PCN outperforms the state-the-the-art alternatives by large margins.
UIGR: Unified Interactive Garment Retrieval
Apr 06, 2022
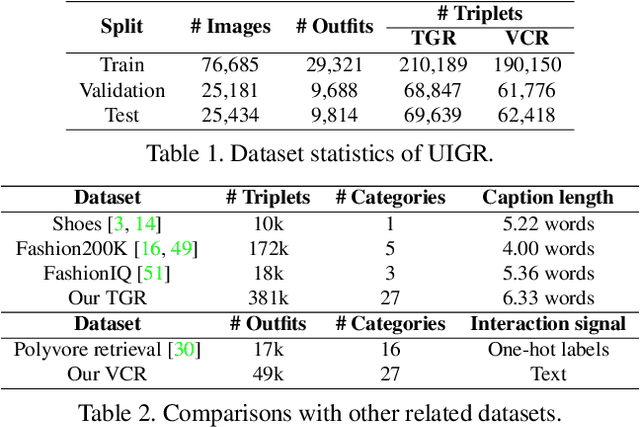
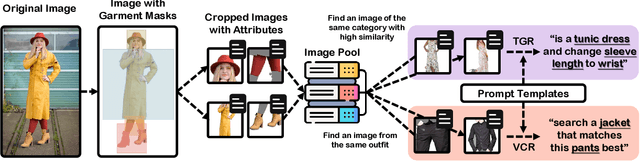
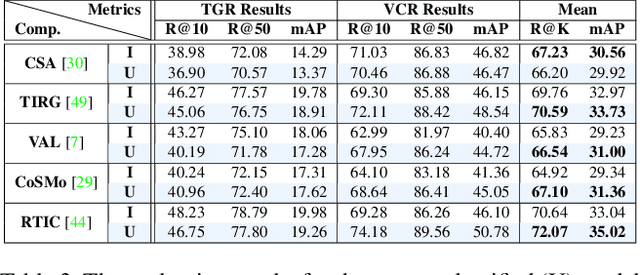
Interactive garment retrieval (IGR) aims to retrieve a target garment image based on a reference garment image along with user feedback on what to change on the reference garment. Two IGR tasks have been studied extensively: text-guided garment retrieval (TGR) and visually compatible garment retrieval (VCR). The user feedback for the former indicates what semantic attributes to change with the garment category preserved, while the category is the only thing to be changed explicitly for the latter, with an implicit requirement on style preservation. Despite the similarity between these two tasks and the practical need for an efficient system tackling both, they have never been unified and modeled jointly. In this paper, we propose a Unified Interactive Garment Retrieval (UIGR) framework to unify TGR and VCR. To this end, we first contribute a large-scale benchmark suited for both problems. We further propose a strong baseline architecture to integrate TGR and VCR in one model. Extensive experiments suggest that unifying two tasks in one framework is not only more efficient by requiring a single model only, it also leads to better performance. Code and datasets are available at https://github.com/BrandonHanx/CompFashion.
Style-Based Global Appearance Flow for Virtual Try-On
Apr 03, 2022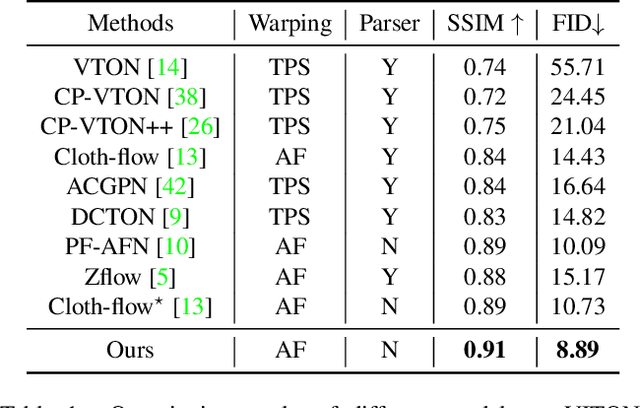
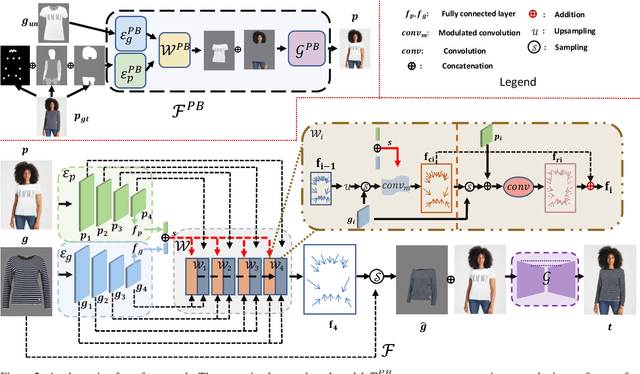

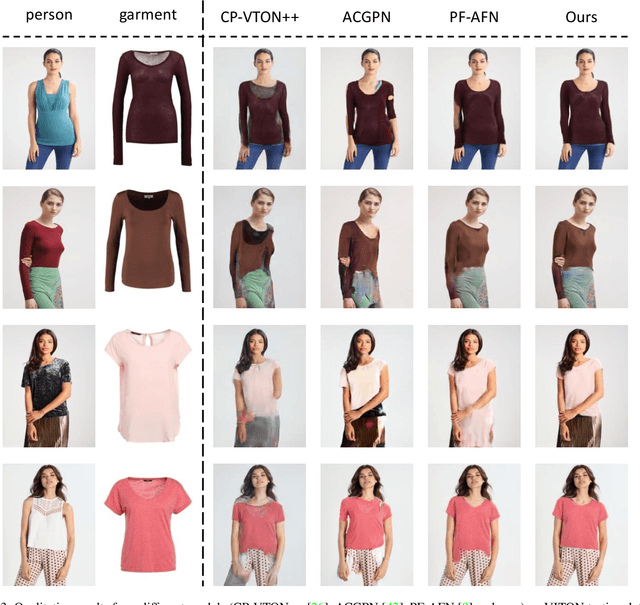
Image-based virtual try-on aims to fit an in-shop garment into a clothed person image. To achieve this, a key step is garment warping which spatially aligns the target garment with the corresponding body parts in the person image. Prior methods typically adopt a local appearance flow estimation model. They are thus intrinsically susceptible to difficult body poses/occlusions and large mis-alignments between person and garment images (see Fig.~\ref{fig:fig1}). To overcome this limitation, a novel global appearance flow estimation model is proposed in this work. For the first time, a StyleGAN based architecture is adopted for appearance flow estimation. This enables us to take advantage of a global style vector to encode a whole-image context to cope with the aforementioned challenges. To guide the StyleGAN flow generator to pay more attention to local garment deformation, a flow refinement module is introduced to add local context. Experiment results on a popular virtual try-on benchmark show that our method achieves new state-of-the-art performance. It is particularly effective in a `in-the-wild' application scenario where the reference image is full-body resulting in a large mis-alignment with the garment image (Fig.~\ref{fig:fig1} Top). Code is available at: \url{https://github.com/SenHe/Flow-Style-VTON}.
Hybrid Graph Neural Networks for Few-Shot Learning
Dec 13, 2021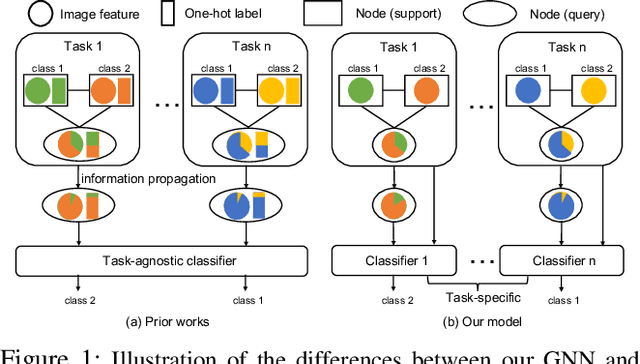
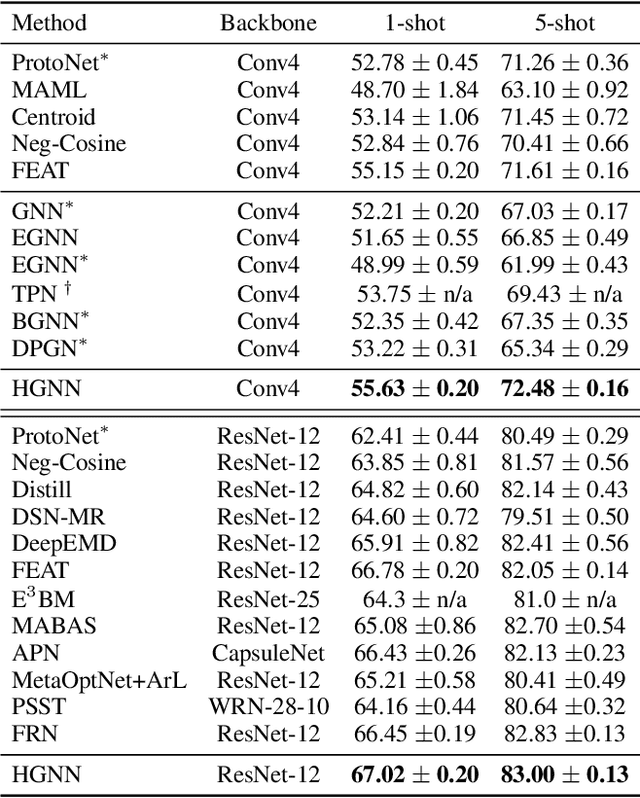
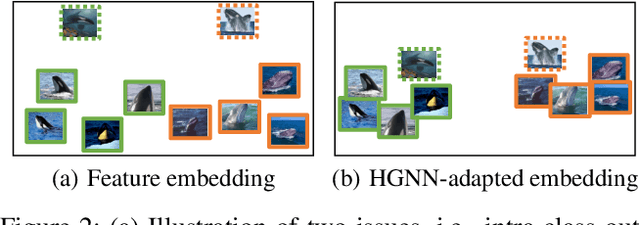
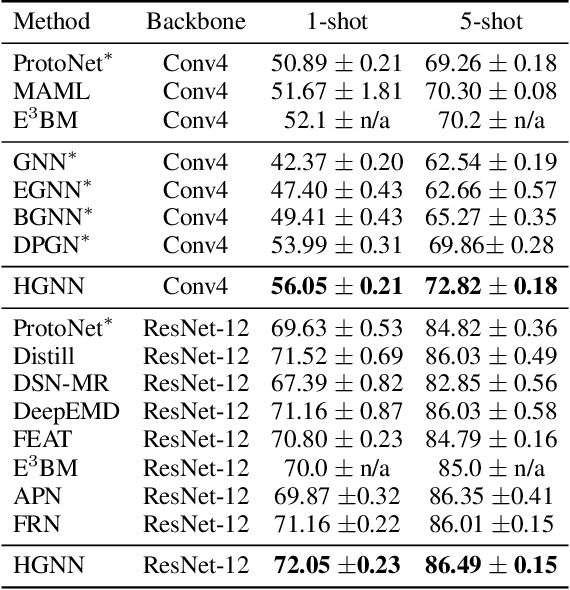
Graph neural networks (GNNs) have been used to tackle the few-shot learning (FSL) problem and shown great potentials under the transductive setting. However under the inductive setting, existing GNN based methods are less competitive. This is because they use an instance GNN as a label propagation/classification module, which is jointly meta-learned with a feature embedding network. This design is problematic because the classifier needs to adapt quickly to new tasks while the embedding does not. To overcome this problem, in this paper we propose a novel hybrid GNN (HGNN) model consisting of two GNNs, an instance GNN and a prototype GNN. Instead of label propagation, they act as feature embedding adaptation modules for quick adaptation of the meta-learned feature embedding to new tasks. Importantly they are designed to deal with a fundamental yet often neglected challenge in FSL, that is, with only a handful of shots per class, any few-shot classifier would be sensitive to badly sampled shots which are either outliers or can cause inter-class distribution overlapping. %Our two GNNs are designed to address these two types of poorly sampled few-shots respectively and their complementarity is exploited in the hybrid GNN model. Extensive experiments show that our HGNN obtains new state-of-the-art on three FSL benchmarks.
Text-Based Person Search with Limited Data
Oct 20, 2021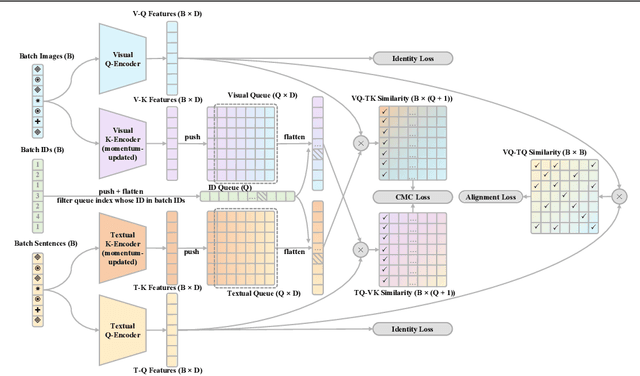
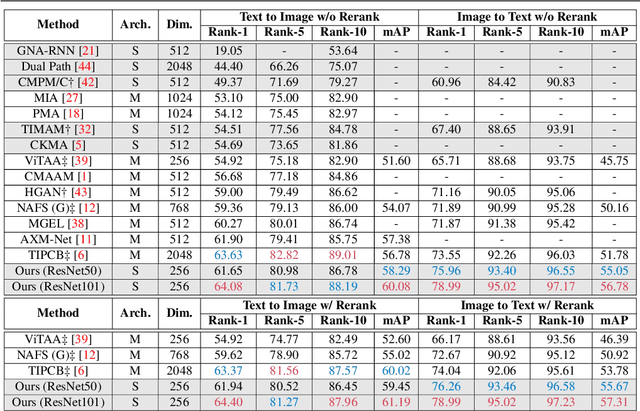
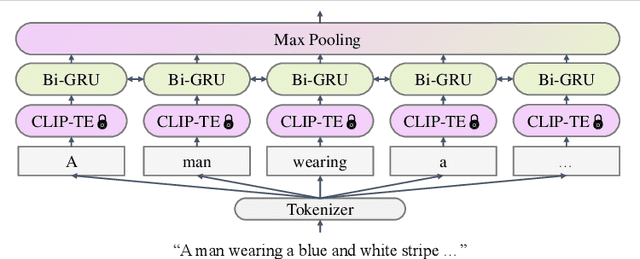
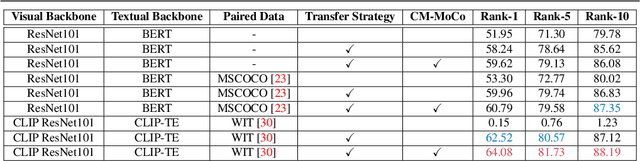
Text-based person search (TBPS) aims at retrieving a target person from an image gallery with a descriptive text query. Solving such a fine-grained cross-modal retrieval task is challenging, which is further hampered by the lack of large-scale datasets. In this paper, we present a framework with two novel components to handle the problems brought by limited data. Firstly, to fully utilize the existing small-scale benchmarking datasets for more discriminative feature learning, we introduce a cross-modal momentum contrastive learning framework to enrich the training data for a given mini-batch. Secondly, we propose to transfer knowledge learned from existing coarse-grained large-scale datasets containing image-text pairs from drastically different problem domains to compensate for the lack of TBPS training data. A transfer learning method is designed so that useful information can be transferred despite the large domain gap. Armed with these components, our method achieves new state of the art on the CUHK-PEDES dataset with significant improvements over the prior art in terms of Rank-1 and mAP. Our code is available at https://github.com/BrandonHanx/TextReID.