 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming from One-Shot Observation
Oct 15, 2023Student modeling is central to many educational technologies as it enables the prediction of future learning outcomes and targeted instructional strategies. However, open-ended learning environments pose challenges for accurately modeling students due to the diverse behaviors exhibited by students and the absence of a well-defined set of learning skills. To approach these challenges, we explore the application of Large Language Models (LLMs) for in-context student modeling in open-ended learning environments. We introduce a novel framework, LLM-SS, that leverages LLMs for synthesizing student's behavior. More concretely, given a particular student's solving attempt on a reference task as observation, the goal is to synthesize the student's attempt on a target task. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs using domain-specific expertise to boost their understanding of domain background and student behaviors. We evaluate several concrete methods based on LLM-SS using the StudentSyn benchmark, an existing student's attempt synthesis benchmark in visual programming. Experimental results show a significant improvement compared to baseline methods included in the StudentSyn benchmark. Furthermore, our method using the fine-tuned Llama2-70B model improves noticeably compared to using the base model and becomes on par with using the state-of-the-art GPT-4 model.
Applying Interdisciplinary Frameworks to Understand Algorithmic Decision-Making
May 26, 2023We argue that explanations for "algorithmic decision-making" (ADM) systems can profit by adopting practices that are already used in the learning sciences. We shortly introduce the importance of explaining ADM systems, give a brief overview of approaches drawing from other disciplines to improve explanations, and present the results of our qualitative task-based study incorporating the "six facets of understanding" framework. We close with questions guiding the discussion of how future studies can leverage an interdisciplinary approach.
Learning Safety Constraints from Demonstrations with Unknown Rewards
May 25, 2023We propose Convex Constraint Learning for Reinforcement Learning (CoCoRL), a novel approach for inferring shared constraints in a Constrained Markov Decision Process (CMDP) from a set of safe demonstrations with possibly different reward functions. While previous work is limited to demonstrations with known rewards or fully known environment dynamics, CoCoRL can learn constraints from demonstrations with different unknown rewards without knowledge of the environment dynamics. CoCoRL constructs a convex safe set based on demonstrations, which provably guarantees safety even for potentially sub-optimal (but safe) demonstrations. For near-optimal demonstrations, CoCoRL converges to the true safe set with no policy regret. We evaluate CoCoRL in tabular environments and a continuous driving simulation with multiple constraints. CoCoRL learns constraints that lead to safe driving behavior and that can be transferred to different tasks and environments. In contrast, alternative methods based on Inverse Reinforcement Learning (IRL) often exhibit poor performance and learn unsafe policies.
Adaptive Scaffolding in Block-Based Programming via Synthesizing New Tasks as Pop Quizzes
Mar 28, 2023Block-based programming environments are increasingly used to introduce computing concepts to beginners. However, novice students often struggle in these environments, given the conceptual and open-ended nature of programming tasks. To effectively support a student struggling to solve a given task, it is important to provide adaptive scaffolding that guides the student towards a solution. We introduce a scaffolding framework based on pop quizzes presented as multi-choice programming tasks. To automatically generate these pop quizzes, we propose a novel algorithm, PQuizSyn. More formally, given a reference task with a solution code and the student's current attempt, PQuizSyn synthesizes new tasks for pop quizzes with the following features: (a) Adaptive (i.e., individualized to the student's current attempt), (b) Comprehensible (i.e., easy to comprehend and solve), and (c) Concealing (i.e., do not reveal the solution code). Our algorithm synthesizes these tasks using techniques based on symbolic reasoning and graph-based code representations. We show that our algorithm can generate hundreds of pop quizzes for different student attempts on reference tasks from Hour of Code: Maze Challenge and Karel. We assess the quality of these pop quizzes through expert ratings using an evaluation rubric. Further, we have built an online platform for practicing block-based programming tasks empowered via pop quiz based feedback, and report results from an initial user study.
Interactively Learning Preference Constraints in Linear Bandits
Jun 10, 2022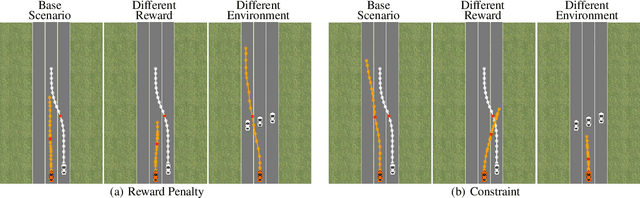
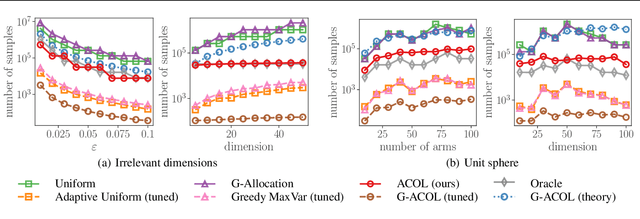

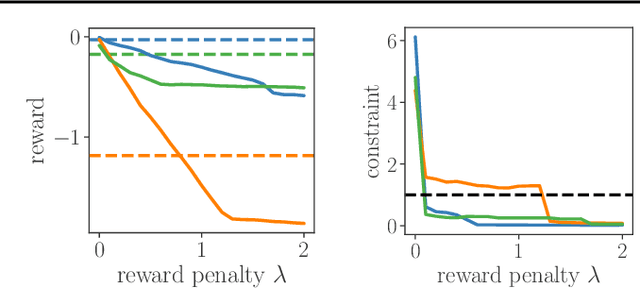
We study sequential decision-making with known rewards and unknown constraints, motivated by situations where the constraints represent expensive-to-evaluate human preferences, such as safe and comfortable driving behavior. We formalize the challenge of interactively learning about these constraints as a novel linear bandit problem which we call constrained linear best-arm identification. To solve this problem, we propose the Adaptive Constraint Learning (ACOL) algorithm. We provide an instance-dependent lower bound for constrained linear best-arm identification and show that ACOL's sample complexity matches the lower bound in the worst-case. In the average case, ACOL's sample complexity bound is still significantly tighter than bounds of simpler approaches. In synthetic experiments, ACOL performs on par with an oracle solution and outperforms a range of baselines. As an application, we consider learning constraints to represent human preferences in a driving simulation. ACOL is significantly more sample efficient than alternatives for this application. Further, we find that learning preferences as constraints is more robust to changes in the driving scenario than encoding the preferences directly in the reward function.
Equity and Fairness of Bayesian Knowledge Tracing
May 04, 2022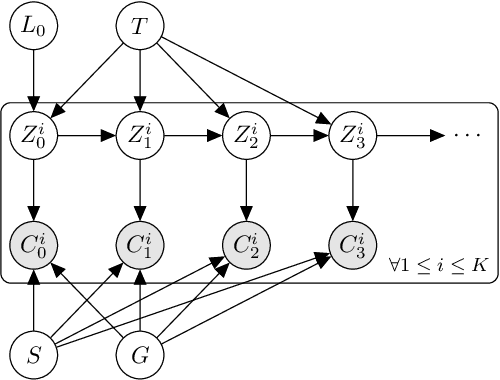
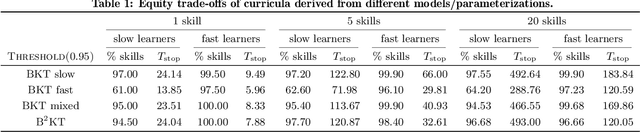
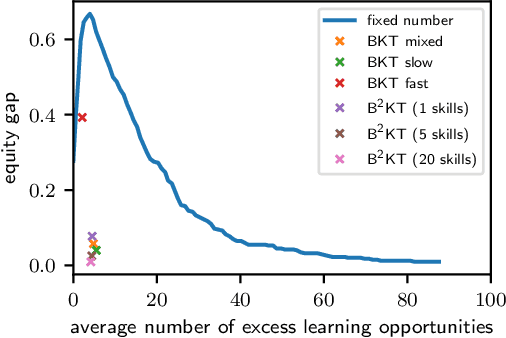

We consider the equity and fairness of curricula derived from Knowledge Tracing models. We begin by defining a unifying notion of an equitable tutoring system as a system that achieves maximum possible knowledge in minimal time for each student interacting with it. Realizing perfect equity requires tutoring systems that can provide individualized curricula per student. In particular, we investigate the design of equitable tutoring systems that derive their curricula from Knowledge Tracing models. We first show that many existing models, including classical Bayesian Knowledge Tracing (BKT) and Deep Knowledge Tracing (DKT), and their derived curricula can fall short of achieving equitable tutoring. To overcome this issue, we then propose a novel model, Bayesian-Bayesian Knowledge Tracing (BBKT), that naturally enables online individualization and, thereby, more equitable tutoring. We demonstrate that curricula derived from our model are more effective and equitable than those derived from classical BKT models. Furthermore, we highlight that improving models with a focus on the fairness of next-step predictions might be insufficient to develop equitable tutoring systems.
MDP Abstraction with Successor Features
Oct 18, 2021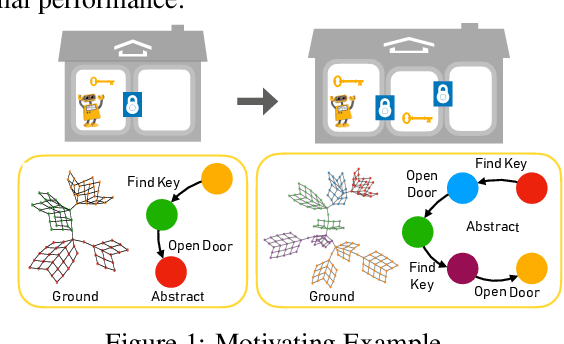
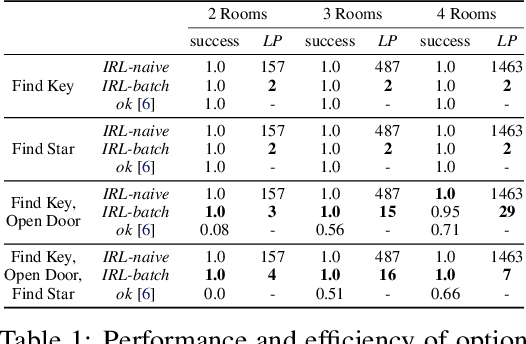
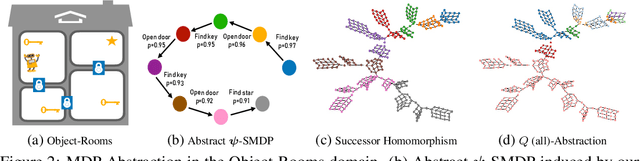
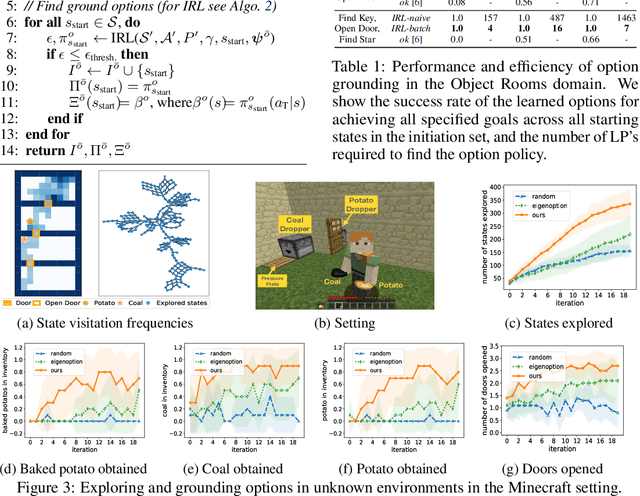
Abstraction plays an important role for generalisation of knowledge and skills, and is key to sample efficient learning and planning. For many complex problems an abstract plan can be formed first, which is then instantiated by filling in the necessary low-level details. Often, such abstract plans generalize well to related new problems. We study abstraction in the context of reinforcement learning, in which agents may perform state or temporal abstractions. Temporal abstractions aka options represent temporally-extended actions in the form of option policies. However, typically acquired option policies cannot be directly transferred to new environments due to changes in the state space or transition dynamics. Furthermore, many existing state abstraction schemes ignore the correlation between state and temporal abstraction. In this work, we propose successor abstraction, a novel abstraction scheme building on successor features. This includes an algorithm for encoding and instantiation of abstract options across different environments, and a state abstraction mechanism based on the abstract options. Our successor abstraction allows us to learn abstract environment models with semantics that are transferable across different environments through encoding and instantiation of abstract options. Empirically, we achieve better transfer and improved performance on a set of benchmark tasks as compared to relevant state of the art baselines.
Contextual HyperNetworks for Novel Feature Adaptation
Apr 12, 2021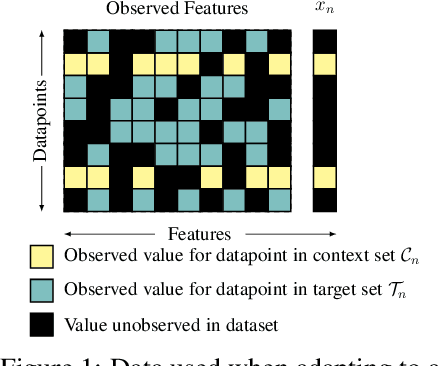
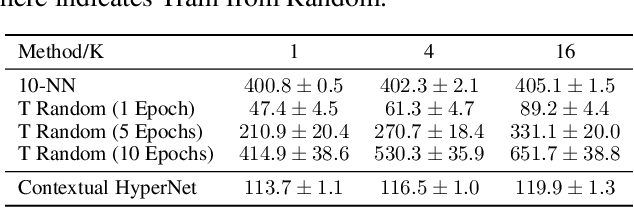
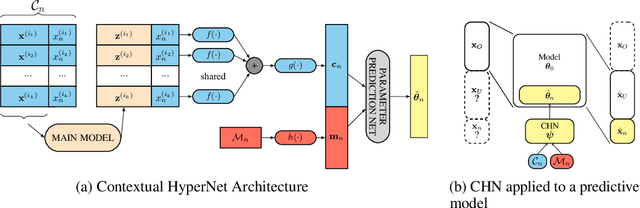
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.
Information Directed Reward Learning for Reinforcement Learning
Feb 24, 2021

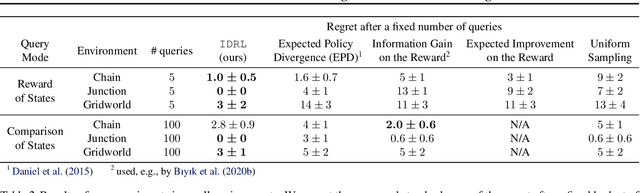
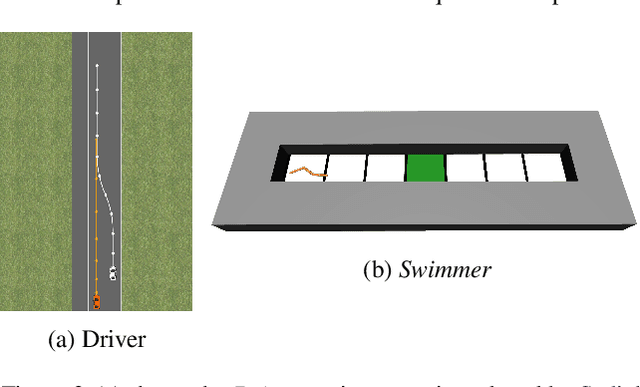
For many reinforcement learning (RL) applications, specifying a reward is difficult. In this paper, we consider an RL setting where the agent can obtain information about the reward only by querying an expert that can, for example, evaluate individual states or provide binary preferences over trajectories. From such expensive feedback, we aim to learn a model of the reward function that allows standard RL algorithms to achieve high expected return with as few expert queries as possible. For this purpose, we propose Information Directed Reward Learning (IDRL), which uses a Bayesian model of the reward function and selects queries that maximize the information gain about the difference in return between potentially optimal policies. In contrast to prior active reward learning methods designed for specific types of queries, IDRL naturally accommodates different query types. Moreover, by shifting the focus from reducing the reward approximation error to improving the policy induced by the reward model, it achieves similar or better performance with significantly fewer queries. We support our findings with extensive evaluations in multiple environments and with different types of queries.
Reinforcement Learning with Efficient Active Feature Acquisition
Nov 02, 2020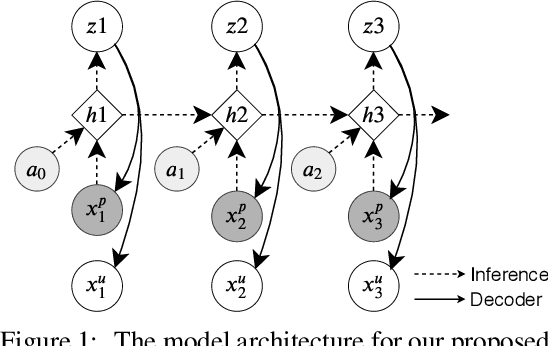
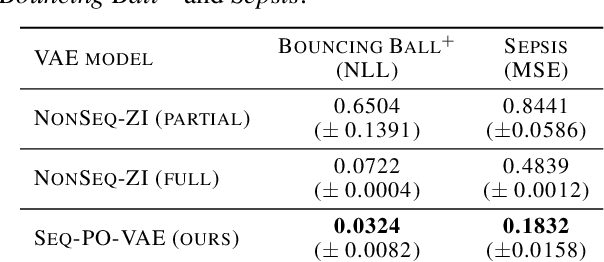
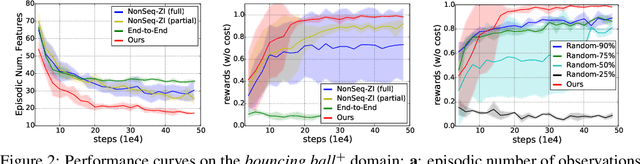

Solving real-life sequential decision making problems under partial observability involves an exploration-exploitation problem. To be successful, an agent needs to efficiently gather valuable information about the state of the world for making rewarding decisions. However, in real-life, acquiring valuable information is often highly costly, e.g., in the medical domain, information acquisition might correspond to performing a medical test on a patient. This poses a significant challenge for the agent to perform optimally for the task while reducing the cost for information acquisition. In this paper, we propose a model-based reinforcement learning framework that learns an active feature acquisition policy to solve the exploration-exploitation problem during its execution. Key to the success is a novel sequential variational auto-encoder that learns high-quality representations from partially observed states, which are then used by the policy to maximize the task reward in a cost efficient manner. We demonstrate the efficacy of our proposed framework in a control domain as well as using a medical simulator. In both tasks, our proposed method outperforms conventional baselines and results in policies with greater cost efficiency.