 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reasoning Strategies in End-to-End Differentiable Proving
Jul 14, 2020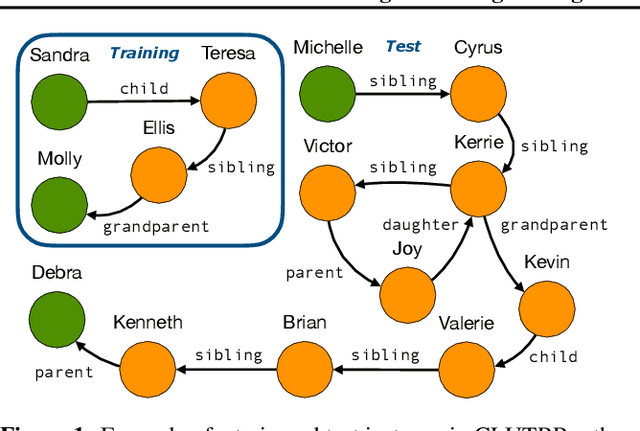
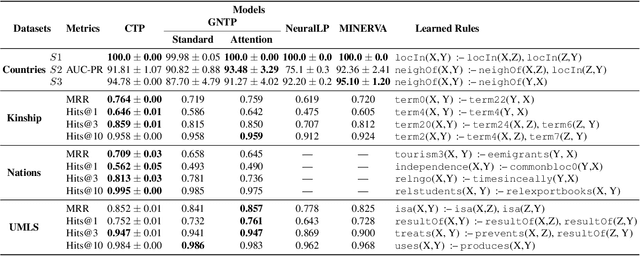

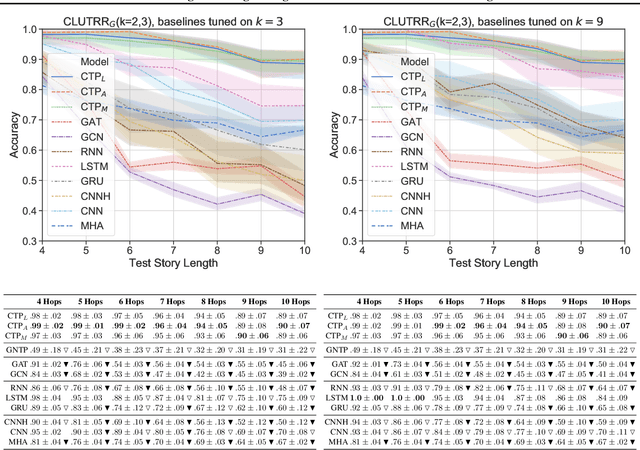
Attempts to render deep learning models interpretable, data-efficient, and robust have seen some success through hybridisation with rule-based systems, for example, in Neural Theorem Provers (NTPs). These neuro-symbolic models can induce interpretable rules and learn representations from data via back-propagation, while providing logical explanations for their predictions. However, they are restricted by their computational complexity, as they need to consider all possible proof paths for explaining a goal, thus rendering them unfit for large-scale applications. We present Conditional Theorem Provers (CTPs), an extension to NTPs that learns an optimal rule selection strategy via gradient-based optimisation. We show that CTPs are scalable and yield state-of-the-art results on the CLUTRR dataset, which tests systematic generalisation of neural models by learning to reason over smaller graphs and evaluating on larger ones. Finally, CTPs show better link prediction results on standard benchmarks in comparison with other neural-symbolic models, while being explainable. All source code and datasets are available online, at https://github.com/uclnlp/ctp.
Concept Matching for Low-Resource Classification
Jun 01, 2020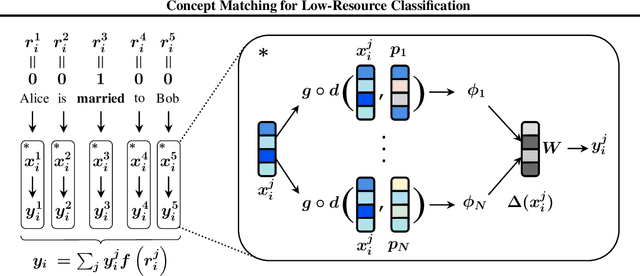


We propose a model to tackle classification tasks in the presence of very little training data. To this aim, we approximate the notion of exact match with a theoretically sound mechanism that computes a probability of matching in the input space. Importantly, the model learns to focus on elements of the input that are relevant for the task at hand; by leveraging highlighted portions of the training data, an error boosting technique guides the learning process. In practice, it increases the error associated with relevant parts of the input by a given factor. Remarkable results on text classification tasks confirm the benefits of the proposed approach in both balanced and unbalanced cases, thus being of practical use when labeling new examples is expensive. In addition, by inspecting its weights, it is often possible to gather insights on what the model has learned.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
May 22, 2020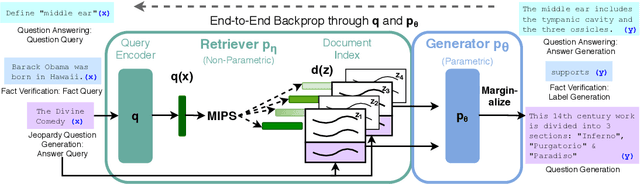
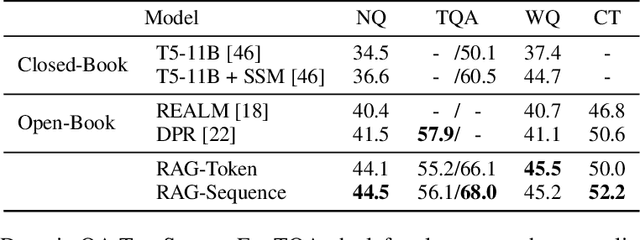
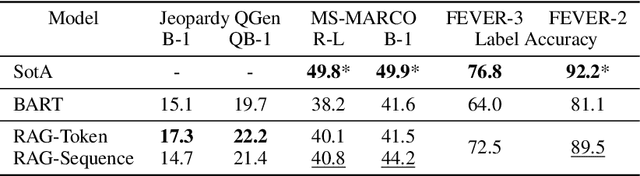

Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. Pre-trained models with a differentiable access mechanism to explicit non-parametric memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) -- models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
May 17, 2020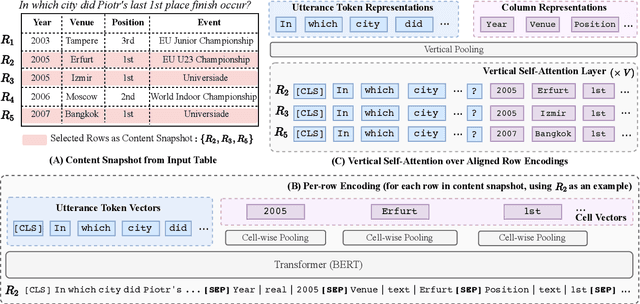
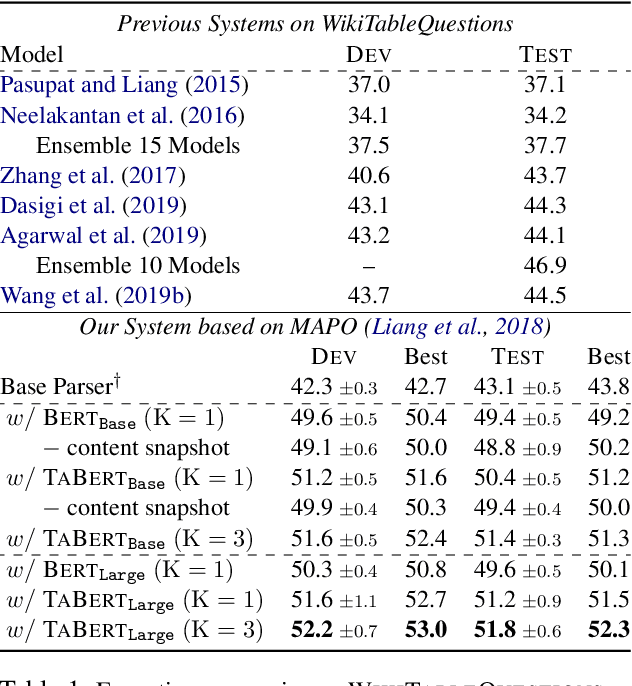
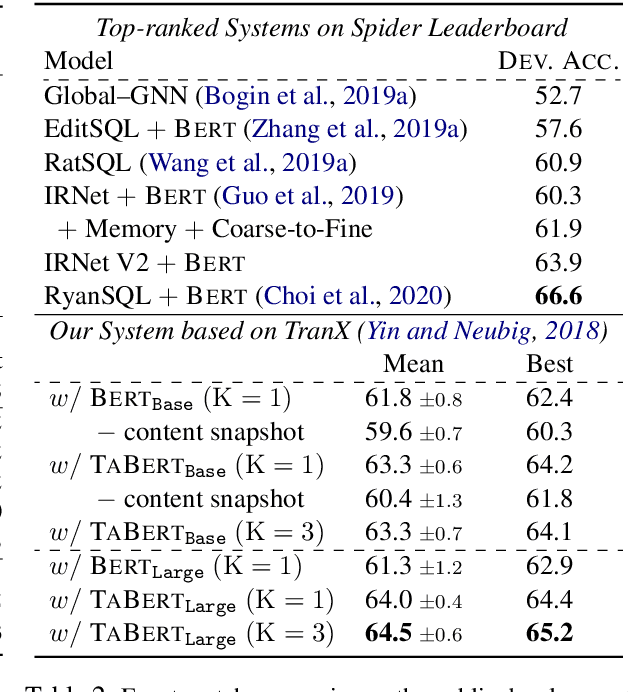
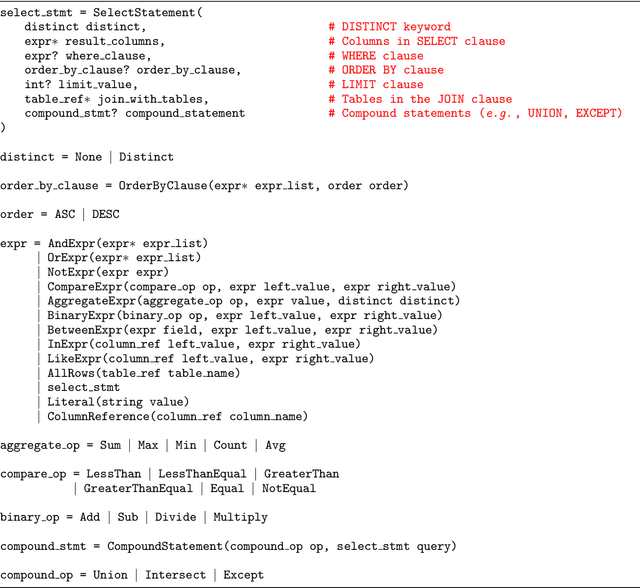
Recent years have witnessed the burgeoning of pretrained language models (LMs) for text-based natural language (NL) understanding tasks. Such models are typically trained on free-form NL text, hence may not be suitable for tasks like semantic parsing over structured data, which require reasoning over both free-form NL questions and structured tabular data (e.g., database tables). In this paper we present TaBERT, a pretrained LM that jointly learns representations for NL sentences and (semi-)structured tables. TaBERT is trained on a large corpus of 26 million tables and their English contexts. In experiments, neural semantic parsers using TaBERT as feature representation layers achieve new best results on the challenging weakly-supervised semantic parsing benchmark WikiTableQuestions, while performing competitively on the text-to-SQL dataset Spider. Implementation of the model will be available at http://fburl.com/TaBERT .
How Context Affects Language Models' Factual Predictions
May 10, 2020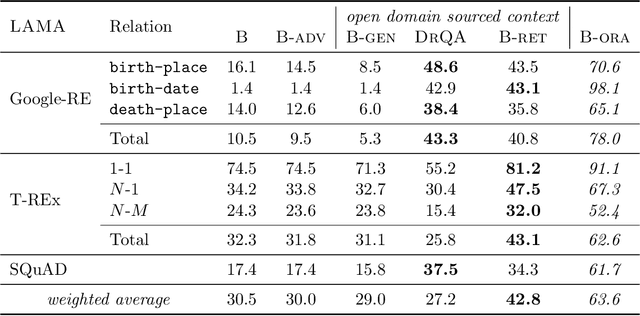
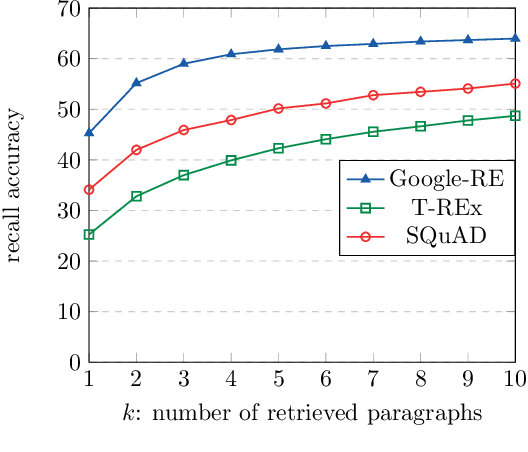
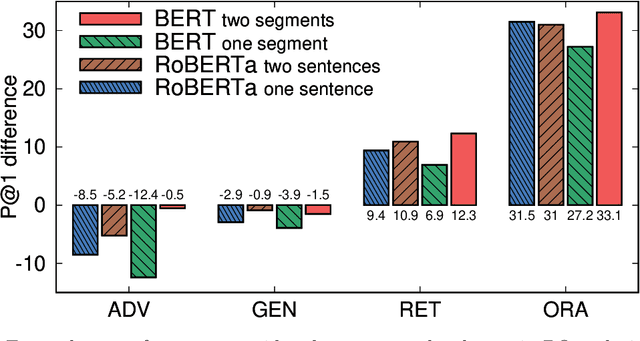
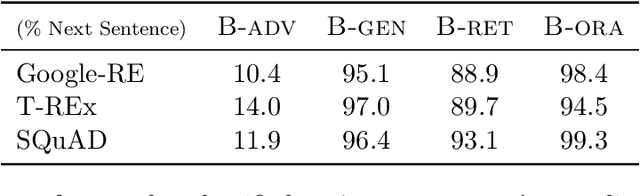
When pre-trained on large unsupervised textual corpora, language models are able to store and retrieve factual knowledge to some extent, making it possible to use them directly for zero-shot cloze-style question answering. However, storing factual knowledge in a fixed number of weights of a language model clearly has limitations. Previous approaches have successfully provided access to information outside the model weights using supervised architectures that combine an information retrieval system with a machine reading component. In this paper, we go a step further and integrate information from a retrieval system with a pre-trained language model in a purely unsupervised way. We report that augmenting pre-trained language models in this way dramatically improves performance and that the resulting system, despite being unsupervised, is competitive with a supervised machine reading baseline. Furthermore, processing query and context with different segment tokens allows BERT to utilize its Next Sentence Prediction pre-trained classifier to determine whether the context is relevant or not, substantially improving BERT's zero-shot cloze-style question-answering performance and making its predictions robust to noisy contexts.
AxCell: Automatic Extraction of Results from Machine Learning Papers
Apr 29, 2020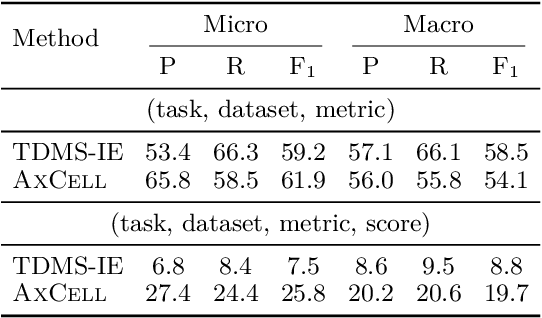
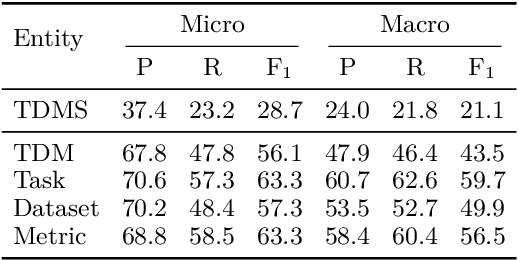
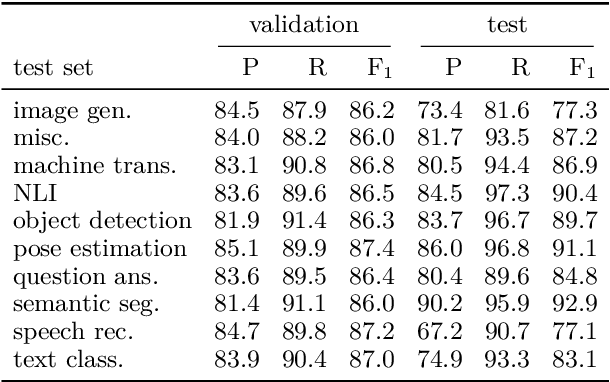
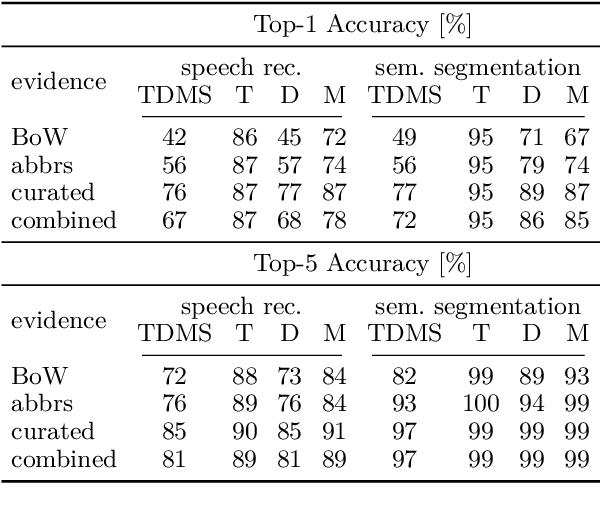
Tracking progress in machine learning has become increasingly difficult with the recent explosion in the number of papers. In this paper, we present AxCell, an automatic machine learning pipeline for extracting results from papers. AxCell uses several novel components, including a table segmentation subtask, to learn relevant structural knowledge that aids extraction. When compared with existing methods, our approach significantly improves the state of the art for results extraction. We also release a structured, annotated dataset for training models for results extraction, and a dataset for evaluating the performance of models on this task. Lastly, we show the viability of our approach enables it to be used for semi-automated results extraction in production, suggesting our improvements make this task practically viable for the first time. Code is available on GitHub.
There is Strength in Numbers: Avoiding the Hypothesis-Only Bias in Natural Language Inference via Ensemble Adversarial Training
Apr 27, 2020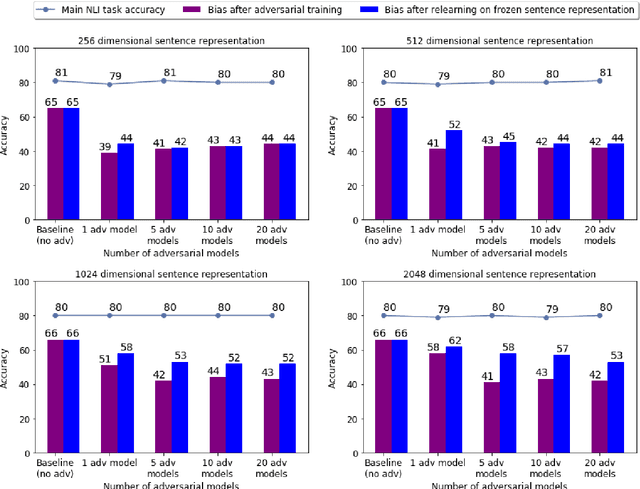
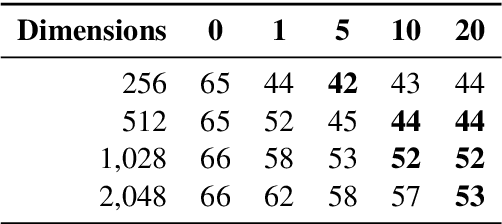
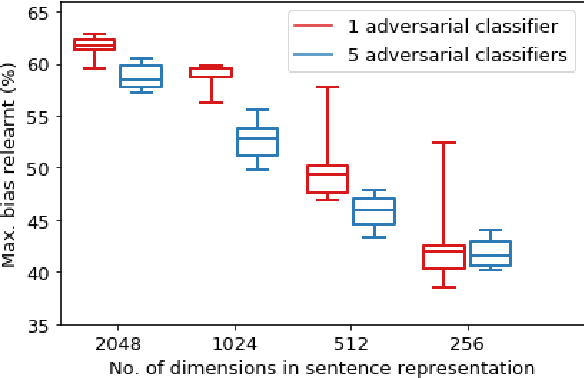

Natural Language Inference (NLI) datasets contain annotation artefacts resulting in spurious correlations between the natural language utterances and their respective entailment classes. These artefacts are exploited by neural networks even when only considering the hypothesis and ignoring the premise, leading to unwanted biases. Previous work proposed tackling this problem via adversarial training, but this leads to learned sentence representations that still suffer from the same biases. As a solution, we propose using an ensemble of adversaries during the training, encouraging the model to jointly decrease the accuracy of these different adversaries while fitting the data. We show that using an ensemble of adversaries can prevent the bias from being relearned after the model training is completed, further improving how well the model generalises to different NLI datasets. In particular, these models outperformed previous approaches when tested on 12 different NLI datasets not used in the model training. Finally, the optimal number of adversarial classifiers depends on the dimensionality of the sentence representations, with larger dimensional representations benefiting when trained with a greater number of adversaries.
Undersensitivity in Neural Reading Comprehension
Feb 15, 2020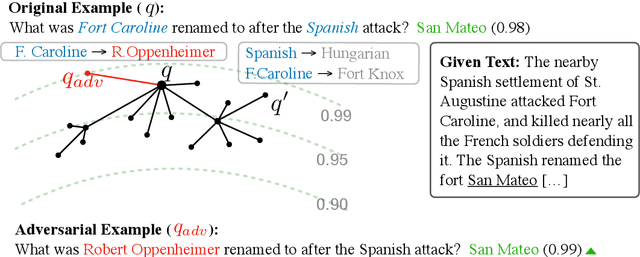
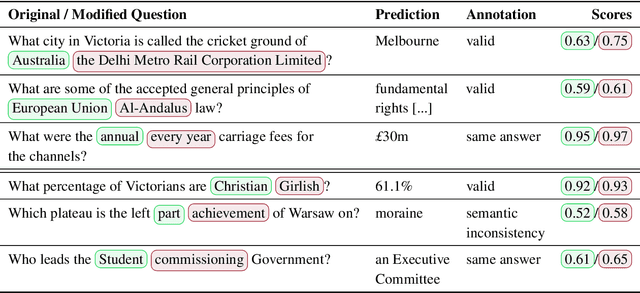
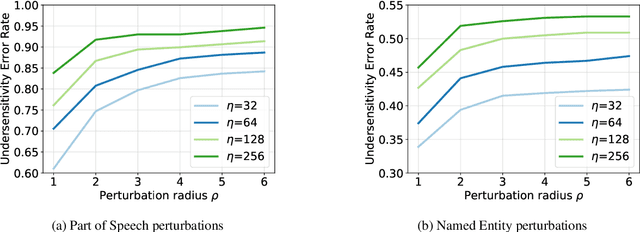
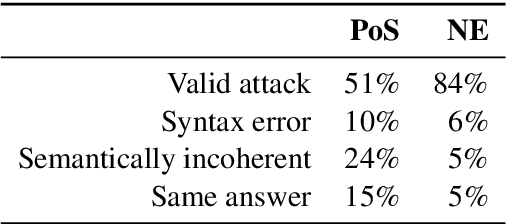
Current reading comprehension models generalise well to in-distribution test sets, yet perform poorly on adversarially selected inputs. Most prior work on adversarial inputs studies oversensitivity: semantically invariant text perturbations that cause a model's prediction to change when it should not. In this work we focus on the complementary problem: excessive prediction undersensitivity, where input text is meaningfully changed but the model's prediction does not, even though it should. We formulate a noisy adversarial attack which searches among semantic variations of the question for which a model erroneously predicts the same answer, and with even higher probability. Despite comprising unanswerable questions, both SQuAD2.0 and NewsQA models are vulnerable to this attack. This indicates that although accurate, models tend to rely on spurious patterns and do not fully consider the information specified in a question. We experiment with data augmentation and adversarial training as defences, and find that both substantially decrease vulnerability to attacks on held out data, as well as held out attack spaces. Addressing undersensitivity also improves results on AddSent and AddOneSent, and models furthermore generalise better when facing train/evaluation distribution mismatch: they are less prone to overly rely on predictive cues present only in the training set, and outperform a conventional model by as much as 10.9% F1.
Beat the AI: Investigating Adversarial Human Annotations for Reading Comprehension
Feb 02, 2020
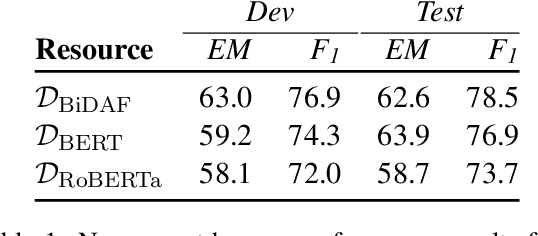
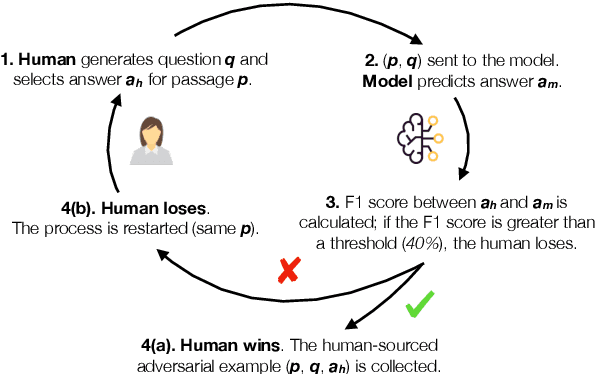
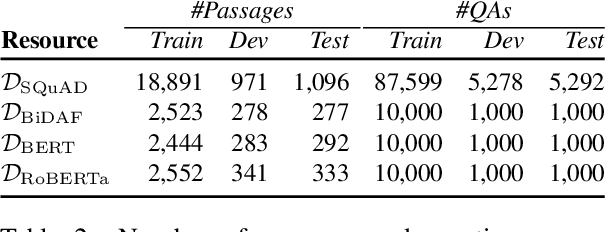
Innovations in annotation methodology have been a propellant for Reading Comprehension (RC) datasets and models. One recent trend to challenge current RC models is to involve a model in the annotation process: humans create questions adversarially, such that the model fails to answer them correctly. In this work we investigate this annotation approach and apply it in three different settings, collecting a total of 36,000 samples with progressively stronger models in the annotation loop. This allows us to explore questions such as the reproducibility of the adversarial effect, transfer from data collected with varying model-in-the-loop strengths, and generalisation to data collected without a model. We find that training on adversarially collected samples leads to strong generalisation to non-adversarially collected datasets, yet with progressive deterioration as the model-in-the-loop strength increases. Furthermore we find that stronger models can still learn from datasets collected with substantially weaker models in the loop: When trained on data collected with a BiDAF model in the loop, RoBERTa achieves 36.0F1 on questions that it cannot answer when trained on SQuAD - only marginally lower than when trained on data collected using RoBERTa itself.
Differentiable Reasoning on Large Knowledge Bases and Natural Language
Dec 17, 2019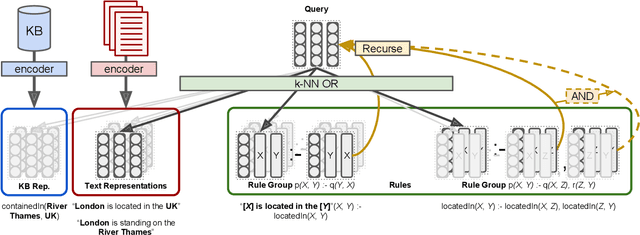
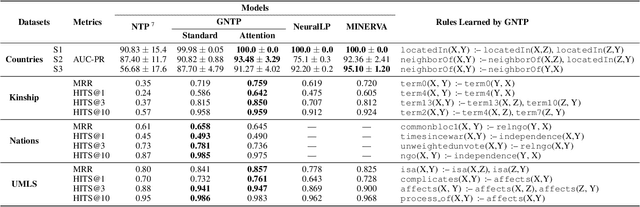
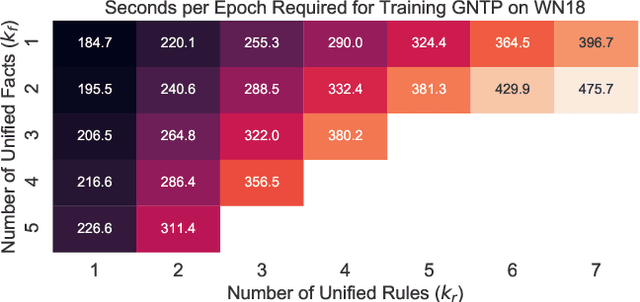
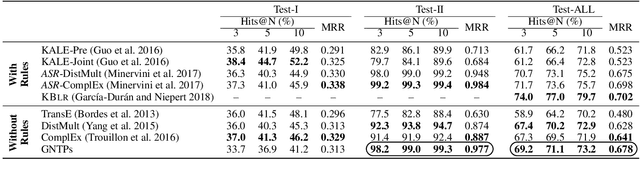
Reasoning with knowledge expressed in natural language and Knowledge Bases (KBs) is a major challenge for Artificial Intelligence, with applications in machine reading, dialogue, and question answering. General neural architectures that jointly learn representations and transformations of text are very data-inefficient, and it is hard to analyse their reasoning process. These issues are addressed by end-to-end differentiable reasoning systems such as Neural Theorem Provers (NTPs), although they can only be used with small-scale symbolic KBs. In this paper we first propose Greedy NTPs (GNTPs), an extension to NTPs addressing their complexity and scalability limitations, thus making them applicable to real-world datasets. This result is achieved by dynamically constructing the computation graph of NTPs and including only the most promising proof paths during inference, thus obtaining orders of magnitude more efficient models. Then, we propose a novel approach for jointly reasoning over KBs and textual mentions, by embedding logic facts and natural language sentences in a shared embedding space. We show that GNTPs perform on par with NTPs at a fraction of their cost while achieving competitive link prediction results on large datasets, providing explanations for predictions, and inducing interpretable models. Source code, datasets, and supplementary material are available online at https://github.com/uclnlp/gntp.