 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does the Answer Come From? Benchmarking View-Level Visual Evidence Identification in Multi-View MLLMs for Autonomous Driving
Jun 08, 2026Multimodal large language models (MLLMs) achieve strong results on visual reasoning benchmarks, but answer accuracy alone does not indicate whether a model relied on the correct visual evidence. This gap is particularly important in multi-view driving scenes used for autonomous driving, where a model can produce a plausible answer while grounding it in the wrong camera view. We introduce a multi-view visual question answering benchmark for evaluating evidence-source identification: given six synchronized NuScenes views and a question, the model must identify the supporting camera view and answer the question. The benchmark contains 122 conflict-centric question-answer pairs from 73 scenes, spanning causality, counterfactual reasoning, and intent prediction. View labels are proposed by an automatic conflict-mining pipeline and manually verified by annotators. We evaluate three settings: camera-view selection, oracle QA given the golden view, and joint prediction in which the model selects a view and answers in one pass. Answers are evaluated in both multiple-choice and free-form formats, using exact match for structured predictions and an LLM judge for free-form responses. By explicitly separating visual-source identification from answer correctness, the benchmark exposes grounding failures that answer-only evaluation misses.
VISTAQA: Benchmarking Joint Visual Question Answering and Pixel-Level Evidence
May 20, 2026Establishing a clear link between model predictions and the visual evidence that supports them is critical for transparency and reliability in multimodal reasoning, yet current multimodal large language model (MLLM) evaluations do not explicitly enforce this alignment. Existing benchmarks assess either textual answer correctness or pixel-level localization in isolation, leaving the coupling of reasoning and grounding an open challenge. We introduce VISTAQA, a comprehensive benchmark for joint evaluation of free-form answer correctness and pixel-level evidence grounding in visual question answering. VISTAQA comprises 1,157 expert-curated samples spanning six task types and six visual domains, ranging from direct perception to compositional and relational reasoning. VISTAQA requires models to not only answer correctly, but to also provide precise segmentation masks that support their answers. It also includes hallucination-aware examples where no valid visual evidence exists. To support this enhanced evaluation, we introduce GROVE, a unified evaluation metric that enforces joint correctness by combining textual accuracy and grounding quality via a per-sample geometric mean, ensuring neither dimension can compensate for deficiencies in the other. Comprehensive experiments across grounding-aware models and hybrid pipelines with general-purpose MLLMs reveal that even the strongest systems achieve limited performance under GROVE, highlighting a substantial gap between answer accuracy and visual evidence alignment.
HAWAII: Hierarchical Visual Knowledge Transfer for Efficient Vision-Language Models
Jun 23, 2025Improving the visual understanding ability of vision-language models (VLMs) is crucial for enhancing their performance across various tasks. While using multiple pretrained visual experts has shown great promise, it often incurs significant computational costs during training and inference. To address this challenge, we propose HAWAII, a novel framework that distills knowledge from multiple visual experts into a single vision encoder, enabling it to inherit the complementary strengths of several experts with minimal computational overhead. To mitigate conflicts among different teachers and switch between different teacher-specific knowledge, instead of using a fixed set of adapters for multiple teachers, we propose to use teacher-specific Low-Rank Adaptation (LoRA) adapters with a corresponding router. Each adapter is aligned with a specific teacher, avoiding noisy guidance during distillation. To enable efficient knowledge distillation, we propose fine-grained and coarse-grained distillation. At the fine-grained level, token importance scores are employed to emphasize the most informative tokens from each teacher adaptively. At the coarse-grained level, we summarize the knowledge from multiple teachers and transfer it to the student using a set of general-knowledge LoRA adapters with a router. Extensive experiments on various vision-language tasks demonstrate the superiority of HAWAII, compared to the popular open-source VLMs.
LEO-MINI: An Efficient Multimodal Large Language Model using Conditional Token Reduction and Mixture of Multi-Modal Experts
Apr 07, 2025



Redundancy of visual tokens in multi-modal large language models (MLLMs) significantly reduces their computational efficiency. Recent approaches, such as resamplers and summarizers, have sought to reduce the number of visual tokens, but at the cost of visual reasoning ability. To address this, we propose LEO-MINI, a novel MLLM that significantly reduces the number of visual tokens and simultaneously boosts visual reasoning capabilities. For efficiency, LEO-MINI incorporates CoTR, a novel token reduction module to consolidate a large number of visual tokens into a smaller set of tokens, using the similarity between visual tokens, text tokens, and a compact learnable query. For effectiveness, to scale up the model's ability with minimal computational overhead, LEO-MINI employs MMoE, a novel mixture of multi-modal experts module. MMOE employs a set of LoRA experts with a novel router to switch between them based on the input text and visual tokens instead of only using the input hidden state. MMoE also includes a general LoRA expert that is always activated to learn general knowledge for LLM reasoning. For extracting richer visual features, MMOE employs a set of vision experts trained on diverse domain-specific data. To demonstrate LEO-MINI's improved efficiency and performance, we evaluate it against existing efficient MLLMs on various benchmark vision-language tasks.
OV-SCAN: Semantically Consistent Alignment for Novel Object Discovery in Open-Vocabulary 3D Object Detection
Mar 09, 2025



Open-vocabulary 3D object detection for autonomous driving aims to detect novel objects beyond the predefined training label sets in point cloud scenes. Existing approaches achieve this by connecting traditional 3D object detectors with vision-language models (VLMs) to regress 3D bounding boxes for novel objects and perform open-vocabulary classification through cross-modal alignment between 3D and 2D features. However, achieving robust cross-modal alignment remains a challenge due to semantic inconsistencies when generating corresponding 3D and 2D feature pairs. To overcome this challenge, we present OV-SCAN, an Open-Vocabulary 3D framework that enforces Semantically Consistent Alignment for Novel object discovery. OV-SCAN employs two core strategies: discovering precise 3D annotations and filtering out low-quality or corrupted alignment pairs (arising from 3D annotation, occlusion-induced, or resolution-induced noise). Extensive experiments on the nuScenes dataset demonstrate that OV-SCAN achieves state-of-the-art performance.
LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
Jan 13, 2025



Enhanced visual understanding serves as a cornerstone for multimodal large language models (MLLMs). Recent hybrid MLLMs incorporate a mixture of vision experts to address the limitations of using a single vision encoder and excessively long visual tokens. Despite the progress of these MLLMs, a research gap remains in effectively integrating diverse vision encoders. This work explores fusion strategies of visual tokens for hybrid MLLMs, leading to the design of LEO, a novel MLLM with a dual-branch vision encoder framework that incorporates a post-adaptation fusion strategy and adaptive tiling: for each segmented tile of the input images, LEO sequentially interleaves the visual tokens from its two vision encoders. Extensive evaluation across 13 vision-language benchmarks reveals that LEO outperforms state-of-the-art open-source MLLMs and hybrid MLLMs on the majority of tasks. Furthermore, we show that LEO can be adapted to the specialized domain of autonomous driving without altering the model architecture or training recipe, achieving competitive performance compared to existing baselines. The code and model will be publicly available.
VADet: Multi-frame LiDAR 3D Object Detection using Variable Aggregation
Nov 20, 2024



Input aggregation is a simple technique used by state-of-the-art LiDAR 3D object detectors to improve detection. However, increasing aggregation is known to have diminishing returns and even performance degradation, due to objects responding differently to the number of aggregated frames. To address this limitation, we propose an efficient adaptive method, which we call Variable Aggregation Detection (VADet). Instead of aggregating the entire scene using a fixed number of frames, VADet performs aggregation per object, with the number of frames determined by an object's observed properties, such as speed and point density. VADet thus reduces the inherent trade-offs of fixed aggregation and is not architecture specific. To demonstrate its benefits, we apply VADet to three popular single-stage detectors and achieve state-of-the-art performance on the Waymo dataset.
SOAP: Cross-sensor Domain Adaptation for 3D Object Detection Using Stationary Object Aggregation Pseudo-labelling
Jan 08, 2024



We consider the problem of cross-sensor domain adaptation in the context of LiDAR-based 3D object detection and propose Stationary Object Aggregation Pseudo-labelling (SOAP) to generate high quality pseudo-labels for stationary objects. In contrast to the current state-of-the-art in-domain practice of aggregating just a few input scans, SOAP aggregates entire sequences of point clouds at the input level to reduce the sensor domain gap. Then, by means of what we call quasi-stationary training and spatial consistency post-processing, the SOAP model generates accurate pseudo-labels for stationary objects, closing a minimum of 30.3% domain gap compared to few-frame detectors. Our results also show that state-of-the-art domain adaptation approaches can achieve even greater performance in combination with SOAP, in both the unsupervised and semi-supervised settings.
A Hierarchical Pedestrian Behavior Model to Generate Realistic Human Behavior in Traffic Simulation
Jun 01, 2022

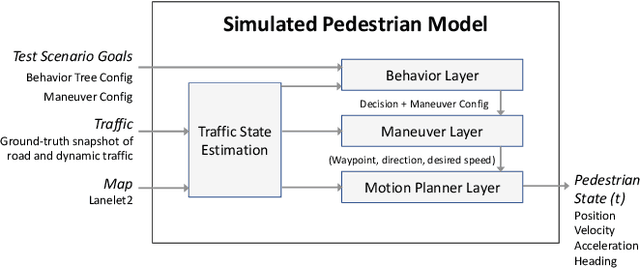
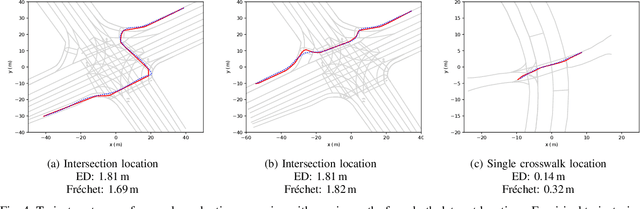
Modelling pedestrian behavior is crucial in the development and testing of autonomous vehicles. In this work, we present a hierarchical pedestrian behavior model that generates high-level decisions through the use of behavior trees, in order to produce maneuvers executed by a low-level motion planner using an adapted Social Force model. A full implementation of our work is integrated into GeoScenario Server, a scenario definition and execution engine, extending its vehicle simulation capabilities with pedestrian simulation. The extended environment allows simulating test scenarios involving both vehicles and pedestrians to assist in the scenario-based testing process of autonomous vehicles. The presented hierarchical model is evaluated on two real-world data sets collected at separate locations with different road structures. Our model is shown to replicate the real-world pedestrians' trajectories with a high degree of fidelity and a decision-making accuracy of 98% or better, given only high-level routing information for each pedestrian.
Recursive Constraints to Prevent Instability in Constrained Reinforcement Learning
Jan 20, 2022We consider the challenge of finding a deterministic policy for a Markov decision process that uniformly (in all states) maximizes one reward subject to a probabilistic constraint over a different reward. Existing solutions do not fully address our precise problem definition, which nevertheless arises naturally in the context of safety-critical robotic systems. This class of problem is known to be hard, but the combined requirements of determinism and uniform optimality can create learning instability. In this work, after describing and motivating our problem with a simple example, we present a suitable constrained reinforcement learning algorithm that prevents learning instability, using recursive constraints. Our proposed approach admits an approximative form that improves efficiency and is conservative w.r.t. the constraint.