 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealed Multi-Objective Utility Aggregation in Human Driving
Mar 13, 2023



A central design problem in game theoretic analysis is the estimation of the players' utilities. In many real-world interactive situations of human decision making, including human driving, the utilities are multi-objective in nature; therefore, estimating the parameters of aggregation, i.e., mapping of multi-objective utilities to a scalar value, becomes an essential part of game construction. However, estimating this parameter from observational data introduces several challenges due to a host of unobservable factors, including the underlying modality of aggregation and the possibly boundedly rational behaviour model that generated the observation. Based on the concept of rationalisability, we develop algorithms for estimating multi-objective aggregation parameters for two common aggregation methods, weighted and satisficing aggregation, and for both strategic and non-strategic reasoning models. Based on three different datasets, we provide insights into how human drivers aggregate the utilities of safety and progress, as well as the situational dependence of the aggregation process. Additionally, we show that irrespective of the specific solution concept used for solving the games, a data-driven estimation of utility aggregation significantly improves the predictive accuracy of behaviour models with respect to observed human behaviour.
A Hierarchical Pedestrian Behavior Model to Generate Realistic Human Behavior in Traffic Simulation
Jun 01, 2022

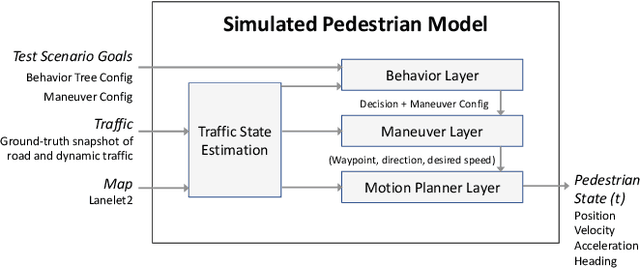
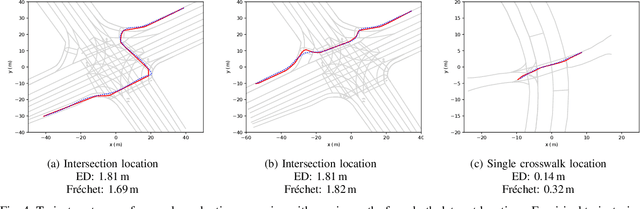
Modelling pedestrian behavior is crucial in the development and testing of autonomous vehicles. In this work, we present a hierarchical pedestrian behavior model that generates high-level decisions through the use of behavior trees, in order to produce maneuvers executed by a low-level motion planner using an adapted Social Force model. A full implementation of our work is integrated into GeoScenario Server, a scenario definition and execution engine, extending its vehicle simulation capabilities with pedestrian simulation. The extended environment allows simulating test scenarios involving both vehicles and pedestrians to assist in the scenario-based testing process of autonomous vehicles. The presented hierarchical model is evaluated on two real-world data sets collected at separate locations with different road structures. Our model is shown to replicate the real-world pedestrians' trajectories with a high degree of fidelity and a decision-making accuracy of 98% or better, given only high-level routing information for each pedestrian.
A taxonomy of strategic human interactions in traffic conflicts
Sep 29, 2021
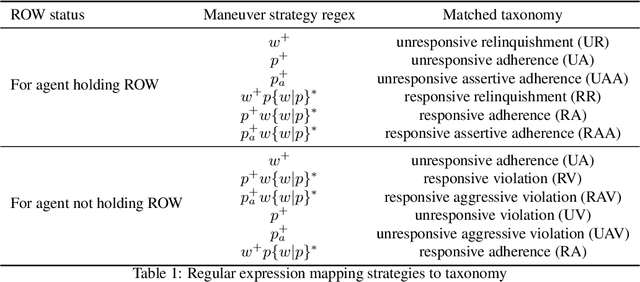
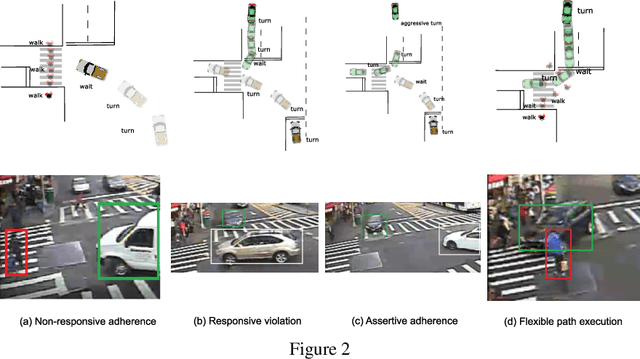
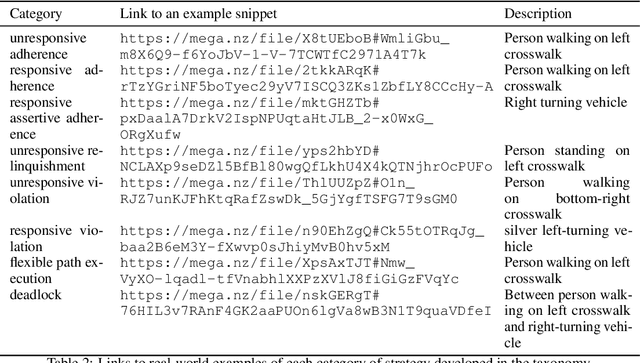
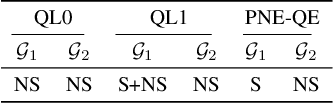
In order to enable autonomous vehicles (AV) to navigate busy traffic situations, in recent years there has been a focus on game-theoretic models for strategic behavior planning in AVs. However, a lack of common taxonomy impedes a broader understanding of the strategies the models generate as well as the development of safety specification to identity what strategies are safe for an AV to execute. Based on common patterns of interaction in traffic conflicts, we develop a taxonomy for strategic interactions along the dimensions of agents' initial response to right-of-way rules and subsequent response to other agents' behavior. Furthermore, we demonstrate a process of automatic mapping of strategies generated by a strategic planner to the categories in the taxonomy, and based on vehicle-vehicle and vehicle-pedestrian interaction simulation, we evaluate two popular solution concepts used in strategic planning in AVs, QLk and Subgame perfect $\epsilon$-Nash Equilibrium, with respect to those categories.
Generalized dynamic cognitive hierarchy models for strategic driving behavior
Sep 20, 2021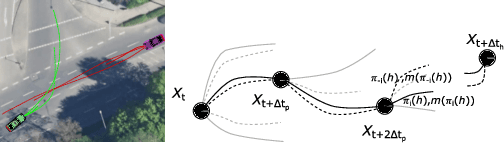
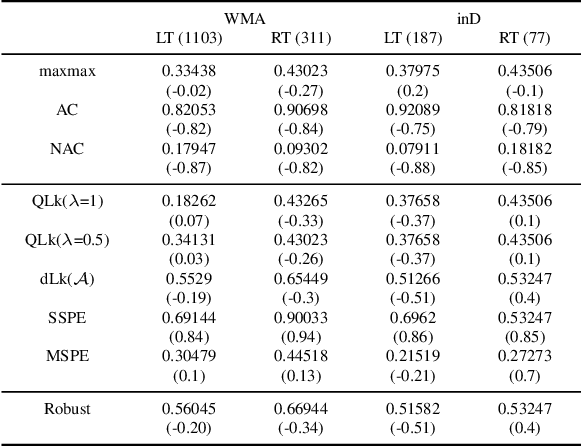
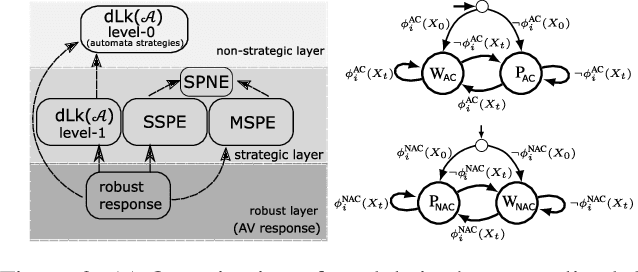
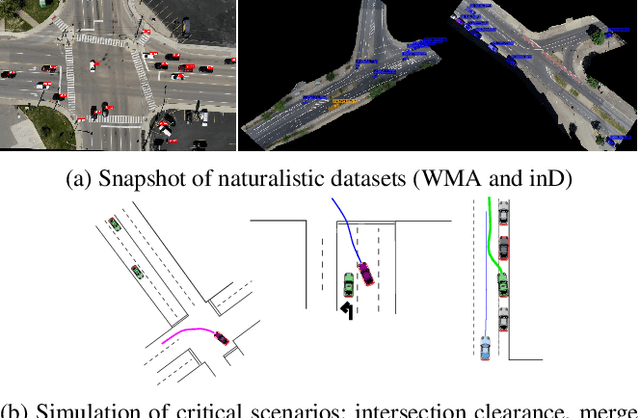
While there has been an increasing focus on the use of game theoretic models for autonomous driving, empirical evidence shows that there are still open questions around dealing with the challenges of common knowledge assumptions as well as modeling bounded rationality. To address some of these practical challenges, we develop a framework of generalized dynamic cognitive hierarchy for both modelling naturalistic human driving behavior as well as behavior planning for autonomous vehicles (AV). This framework is built upon a rich model of level-0 behavior through the use of automata strategies, an interpretable notion of bounded rationality through safety and maneuver satisficing, and a robust response for planning. Based on evaluation on two large naturalistic datasets as well as simulation of critical traffic scenarios, we show that i) automata strategies are well suited for level-0 behavior in a dynamic level-k framework, and ii) the proposed robust response to a heterogeneous population of strategic and non-strategic reasoners can be an effective approach for game theoretic planning in AV.
I Know You Can't See Me: Dynamic Occlusion-Aware Safety Validation of Strategic Planners for Autonomous Vehicles Using Hypergames
Sep 20, 2021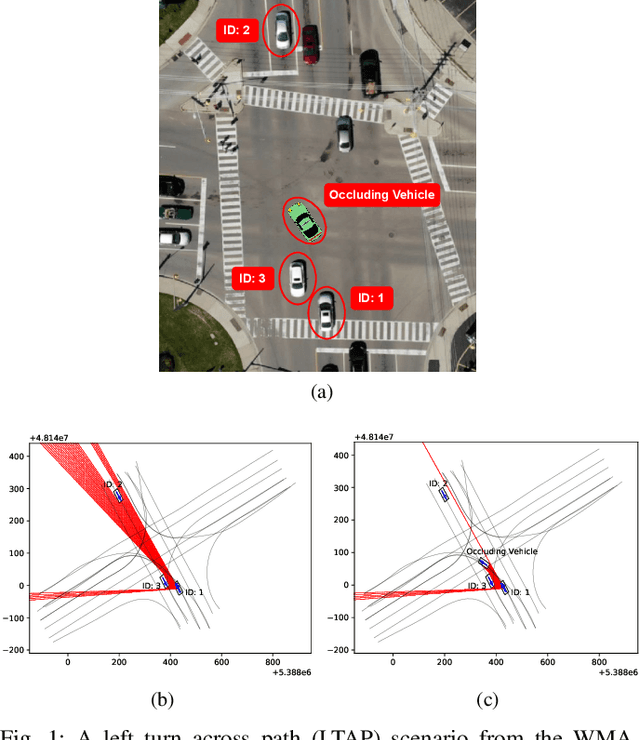
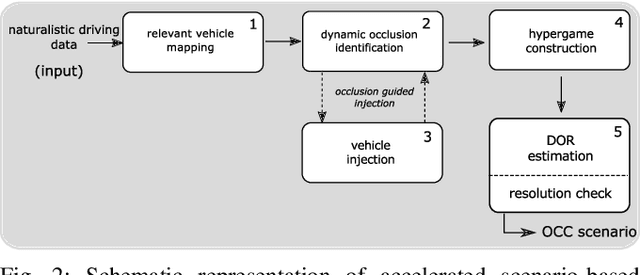
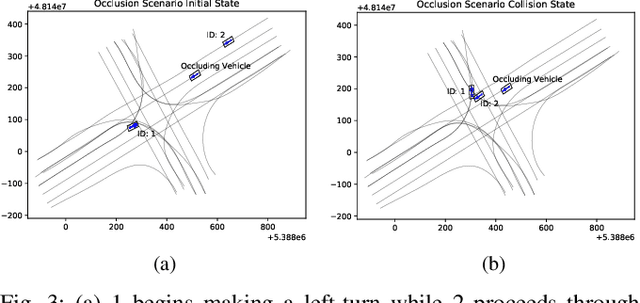
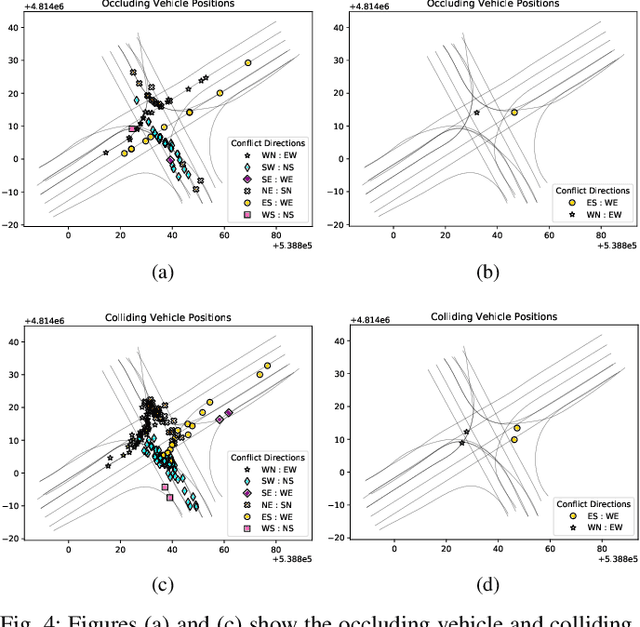
A particular challenge for both autonomous and human driving is dealing with risk associated with dynamic occlusion, i.e., occlusion caused by other vehicles in traffic. Based on the theory of hypergames, we develop a novel multi-agent dynamic occlusion risk (DOR) measure for assessing situational risk in dynamic occlusion scenarios. Furthermore, we present a white-box, scenario-based, accelerated safety validation framework for assessing safety of strategic planners in AV. Based on evaluation over a large naturalistic database, our proposed validation method achieves a 4000% speedup compared to direct validation on naturalistic data, a more diverse coverage, and ability to generalize beyond the dataset and generate commonly observed dynamic occlusion crashes in traffic in an automated manner.
Solution Concepts in Hierarchical Games with Applications to Autonomous Driving
Sep 21, 2020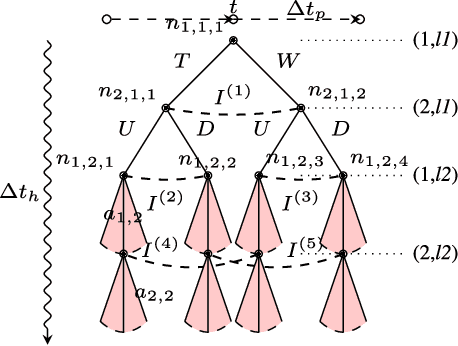
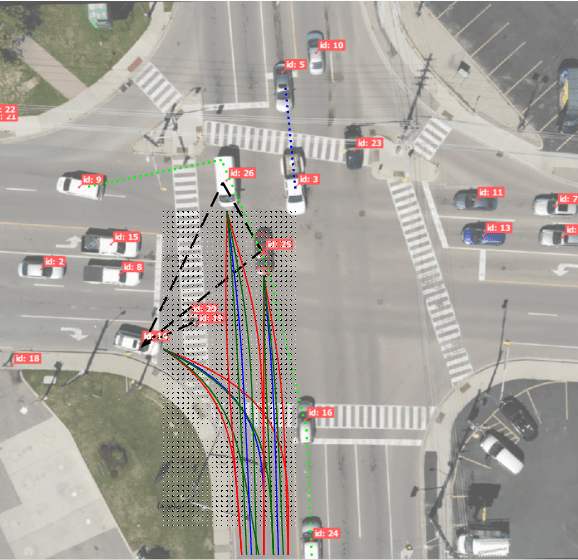
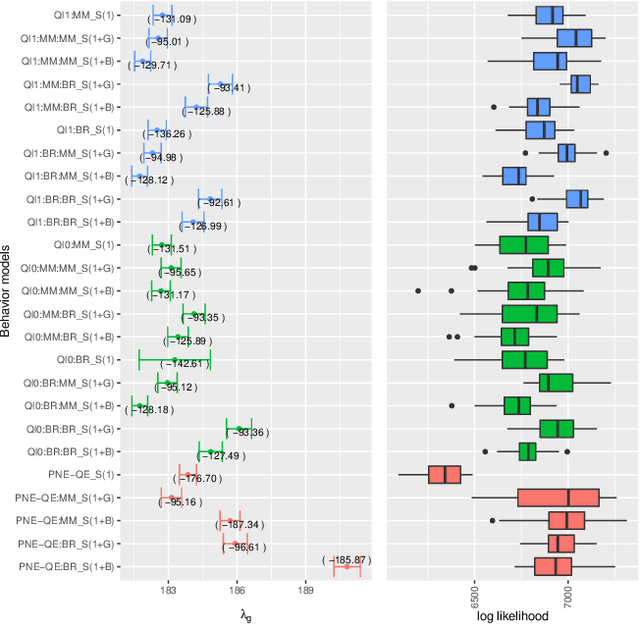
With autonomous vehicles (AV) set to integrate further into regular human traffic, there is an increasing consensus of treating AV motion planning as a multi-agent problem. However, the traditional game theoretic assumption of complete rationality is too strong for the purpose of human driving, and there is a need for understanding human driving as a bounded rational activity through a behavioral game theoretic lens. To that end, we adapt three metamodels of bounded rational behavior; two based on Quantal level-k and one based on Nash equilibrium with quantal errors. We formalize the different solution concepts that can be applied in the context of hierarchical games, a framework used in multi-agent motion planning, for the purpose of creating game theoretic models of driving behavior. Furthermore, based on a contributed dataset of human driving at a busy urban intersection with a total of ~4k agents and ~44k decision points, we evaluate the behavior models on the basis of model fit to naturalistic data, as well as their predictive capacity. Our results suggest that among the behavior models evaluated, modeling driving behavior as pure strategy NE with quantal errors at the level of maneuvers with bounds sampling of actions at the level of trajectories provides the best fit to naturalistic driving behavior.
Design Space of Behaviour Planning for Autonomous Driving
Aug 21, 2019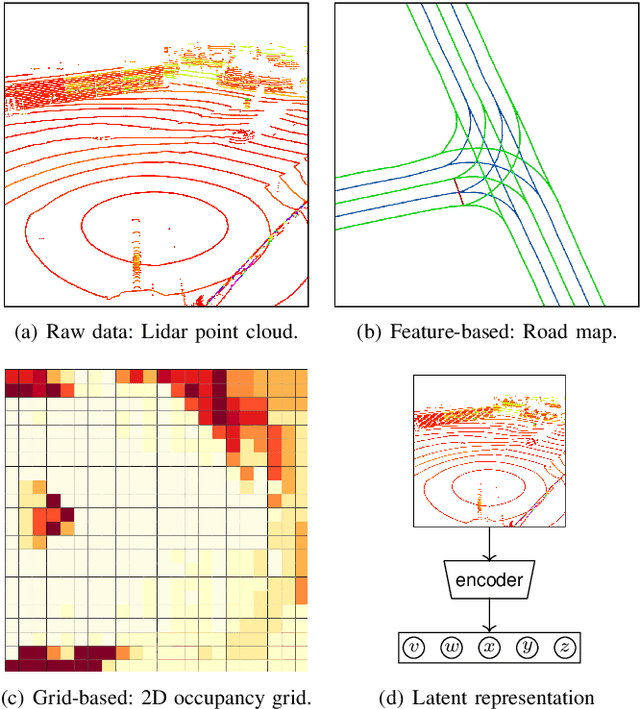
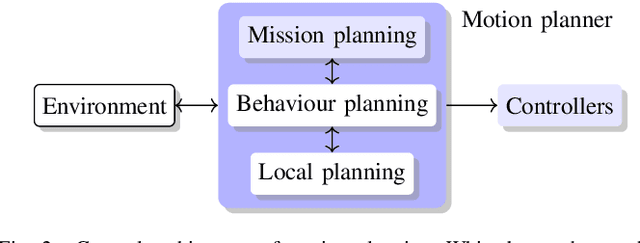
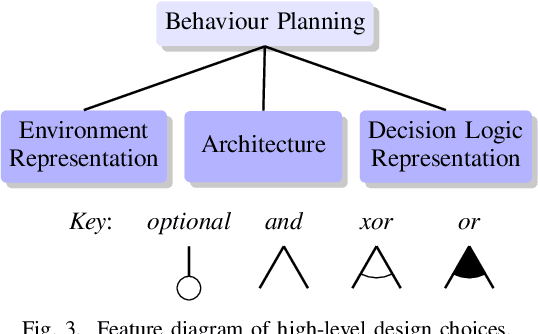
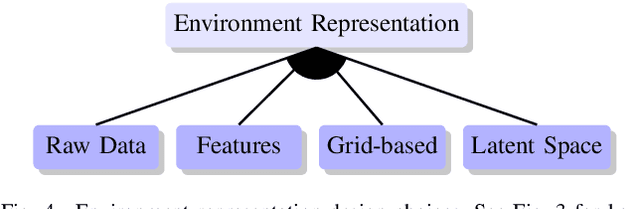
We explore the complex design space of behaviour planning for autonomous driving. Design choices that successfully address one aspect of behaviour planning can critically constrain others. To aid the design process, in this work we decompose the design space with respect to important choices arising from the current state of the art approaches, and describe the resulting trade-offs. In doing this, we also identify interesting directions of future work.
A behavior driven approach for sampling rare event situations for autonomous vehicles
Mar 04, 2019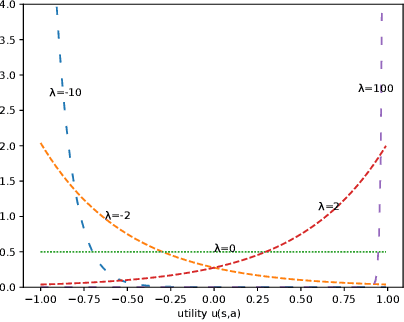
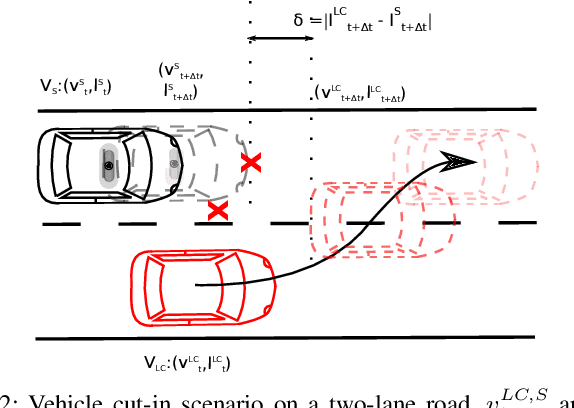
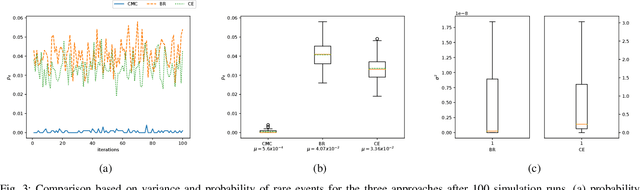
Performance evaluation of urban autonomous vehicles requires a realistic model of the behavior of other road users in the environment. Learning such models from data involves collecting naturalistic data of real-world human behavior. In many cases, acquisition of this data can be prohibitively expensive or intrusive. Additionally, the available data often contain only typical behaviors and exclude behaviors that are classified as rare events. To evaluate the performance of AV in such situations, we develop a model of traffic behavior based on the theory of bounded rationality. Based on the experiments performed on a large naturalistic driving data, we show that the developed model can be applied to estimate probability of rare events, as well as to generate new traffic situations.
A Brandom-ian view of Reinforcement Learning towards strong-AI
Mar 07, 2018
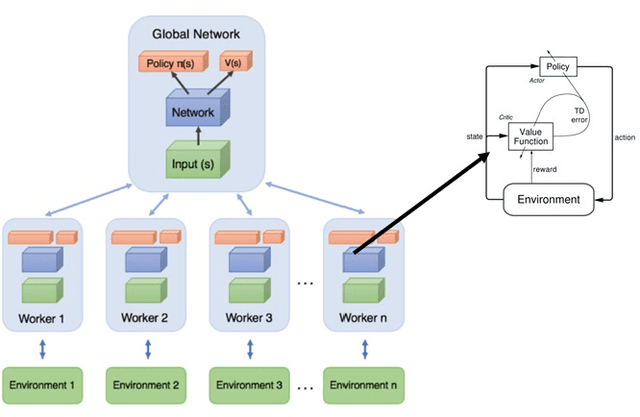
The analytic philosophy of Robert Brandom, based on the ideas of pragmatism, paints a picture of sapience, through inferentialism. In this paper, we present a theory, that utilizes essential elements of Brandom's philosophy, towards the objective of achieving strong-AI. We do this by connecting the constitutive elements of reinforcement learning and the Game Of Giving and Asking For Reasons. Further, following Brandom's prescriptive thoughts, we restructure the popular reinforcement learning algorithm A3C, and show that RL algorithms can be tuned towards the objective of strong-AI.