 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Between Spectral and Spatial Estimation for Speech Separation and Enhancement
Nov 18, 2019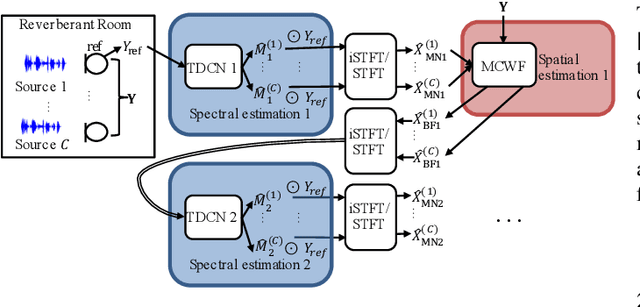
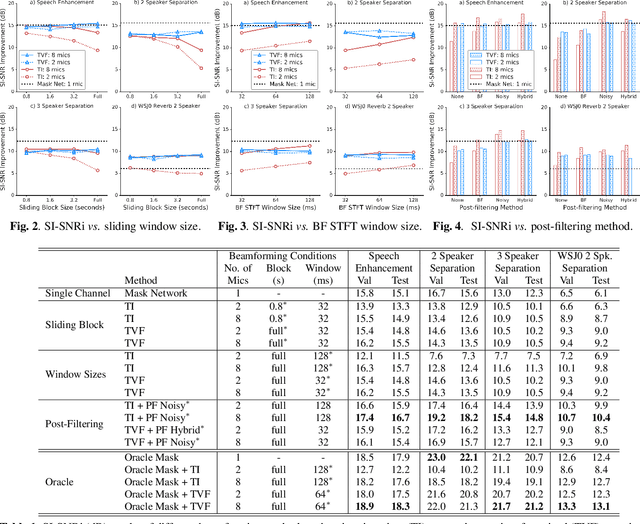
This work investigates alternation between spectral separation using masking-based networks and spatial separation using multichannel beamforming. In this framework, the spectral separation is performed using a mask-based deep network. The result of mask-based separation is used, in turn, to estimate a spatial beamformer. The output of the beamformer is fed back into another mask-based separation network. We explore multiple ways of computing time-varying covariance matrices to improve beamforming, including factorizing the spatial covariance into a time-varying amplitude component and time-invariant spatial component. For the subsequent mask-based filtering, we consider different modes, including masking the noisy input, masking the beamformer output, and a hybrid approach combining both. Our best method first uses spectral separation, then spatial beamforming, and finally a spectral post-filter, and demonstrates an average improvement of 2.8 dB over baseline mask-based separation, across four different reverberant speech enhancement and separation tasks.
Improving Universal Sound Separation Using Sound Classification
Nov 18, 2019
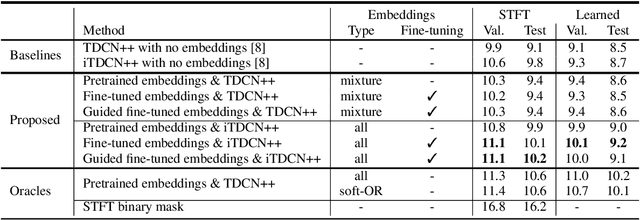
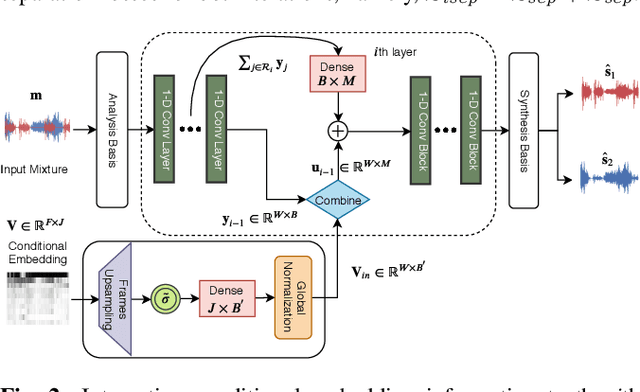
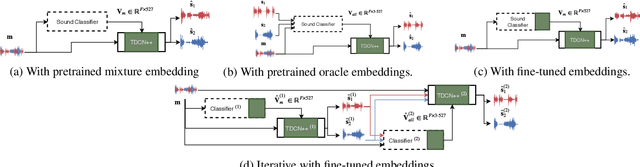
Deep learning approaches have recently achieved impressive performance on both audio source separation and sound classification. Most audio source separation approaches focus only on separating sources belonging to a restricted domain of source classes, such as speech and music. However, recent work has demonstrated the possibility of "universal sound separation", which aims to separate acoustic sources from an open domain, regardless of their class. In this paper, we utilize the semantic information learned by sound classifier networks trained on a vast amount of diverse sounds to improve universal sound separation. In particular, we show that semantic embeddings extracted from a sound classifier can be used to condition a separation network, providing it with useful additional information. This approach is especially useful in an iterative setup, where source estimates from an initial separation stage and their corresponding classifier-derived embeddings are fed to a second separation network. By performing a thorough hyperparameter search consisting of over a thousand experiments, we find that classifier embeddings from clean sources provide nearly one dB of SNR gain, and our best iterative models achieve a significant fraction of this oracle performance, establishing a new state-of-the-art for universal sound separation.
Universal Sound Separation
May 08, 2019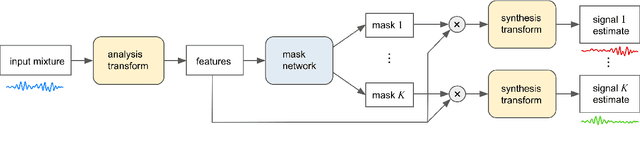
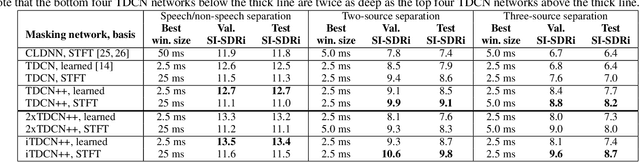
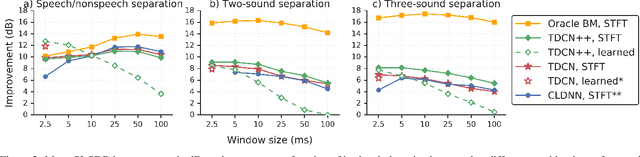
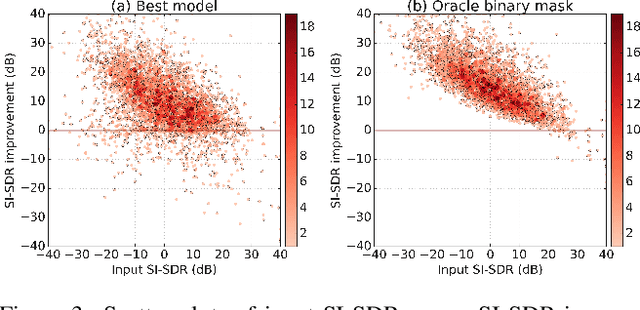
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown whether performance on speech tasks carries over to non-speech tasks. To study this question, we develop a universal dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore using either a short-time Fourier transform (STFT) or a learnable basis, as used in ConvTasNet, and for both of these bases, we examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.
Transfer Learning From Sound Representations For Anger Detection in Speech
Feb 06, 2019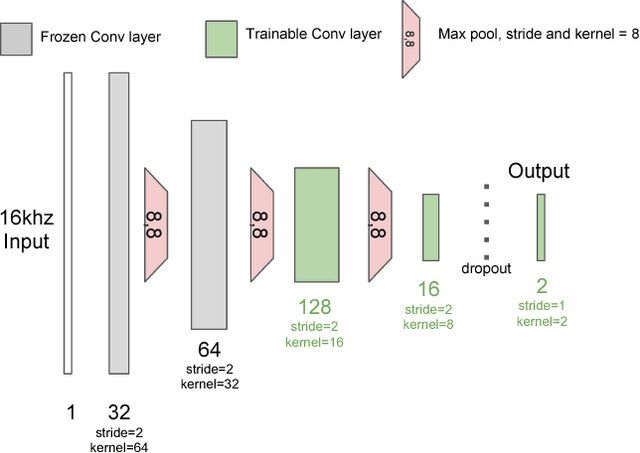
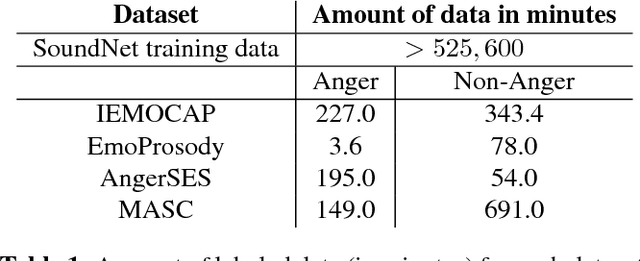
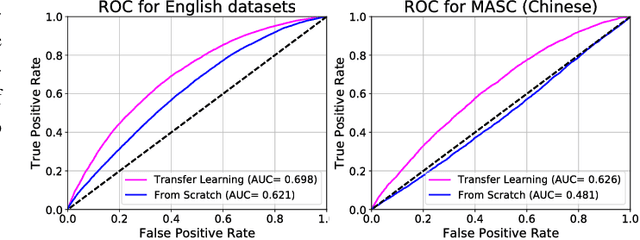
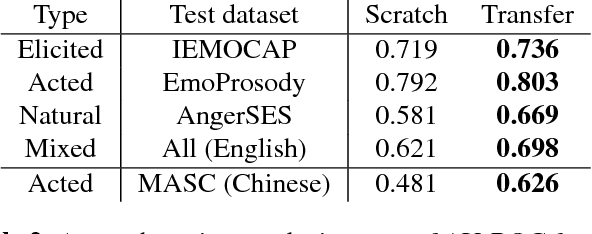
In this work, we train fully convolutional networks to detect anger in speech. Since training these deep architectures requires large amounts of data and the size of emotion datasets is relatively small, we use transfer learning. However, unlike previous approaches that use speech or emotion-based tasks for the source model, we instead use SoundNet, a fully convolutional neural network trained multimodally on a massive video dataset to classify audio, with ground-truth labels provided by vision-based classifiers. As a result of transfer learning from SoundNet, our trained anger detection model improves performance and generalizes well on a variety of acted, elicited, and natural emotional speech datasets. We also test the cross-lingual effectiveness of our model by evaluating our English-trained model on Mandarin Chinese speech emotion data. Furthermore, our proposed system has low latency suitable for real-time applications, only requiring 1.2 seconds of audio to make a reliable classification.
Deep Recurrent NMF for Speech Separation by Unfolding Iterative Thresholding
Sep 21, 2017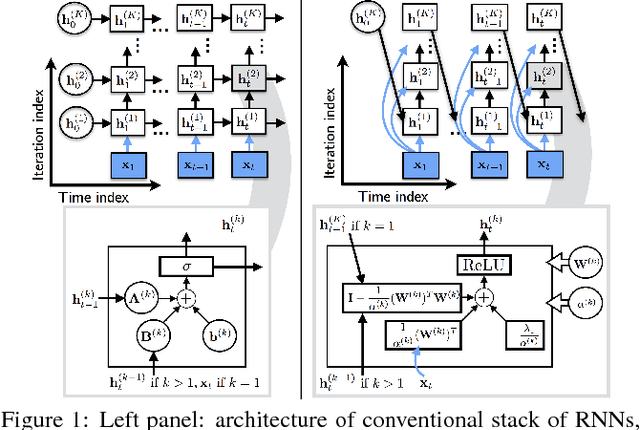
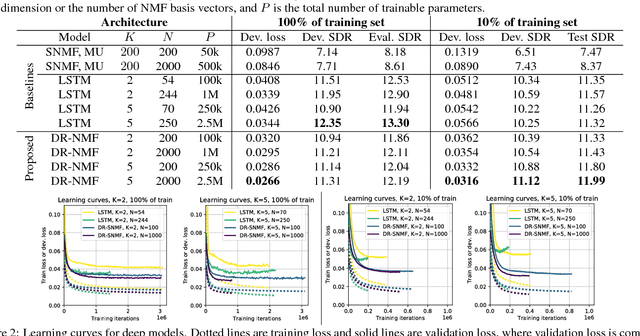
In this paper, we propose a novel recurrent neural network architecture for speech separation. This architecture is constructed by unfolding the iterations of a sequential iterative soft-thresholding algorithm (ISTA) that solves the optimization problem for sparse nonnegative matrix factorization (NMF) of spectrograms. We name this network architecture deep recurrent NMF (DR-NMF). The proposed DR-NMF network has three distinct advantages. First, DR-NMF provides better interpretability than other deep architectures, since the weights correspond to NMF model parameters, even after training. This interpretability also provides principled initializations that enable faster training and convergence to better solutions compared to conventional random initialization. Second, like many deep networks, DR-NMF is an order of magnitude faster at test time than NMF, since computation of the network output only requires evaluating a few layers at each time step. Third, when a limited amount of training data is available, DR-NMF exhibits stronger generalization and separation performance compared to sparse NMF and state-of-the-art long-short term memory (LSTM) networks. When a large amount of training data is available, DR-NMF achieves lower yet competitive separation performance compared to LSTM networks.
Interpretable Recurrent Neural Networks Using Sequential Sparse Recovery
Nov 22, 2016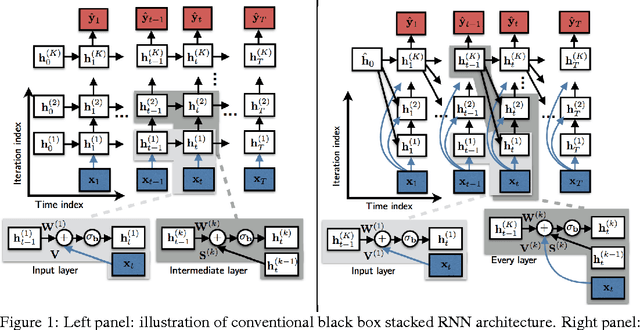
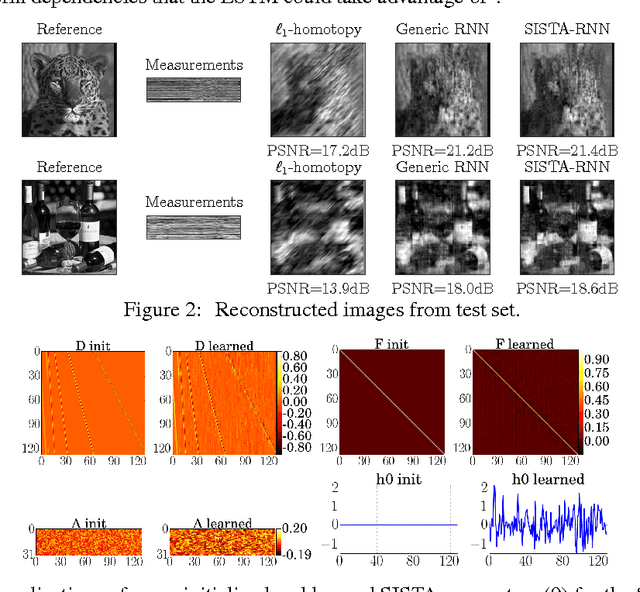
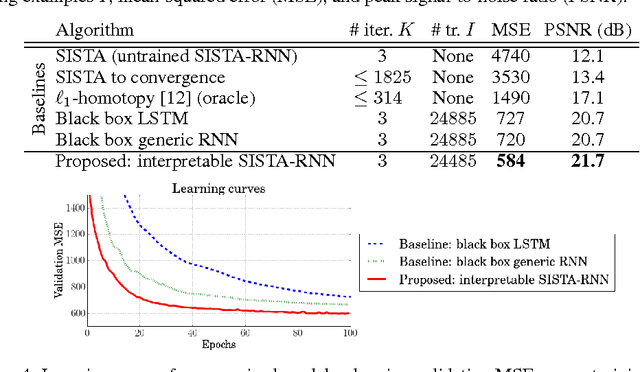
Recurrent neural networks (RNNs) are powerful and effective for processing sequential data. However, RNNs are usually considered "black box" models whose internal structure and learned parameters are not interpretable. In this paper, we propose an interpretable RNN based on the sequential iterative soft-thresholding algorithm (SISTA) for solving the sequential sparse recovery problem, which models a sequence of correlated observations with a sequence of sparse latent vectors. The architecture of the resulting SISTA-RNN is implicitly defined by the computational structure of SISTA, which results in a novel stacked RNN architecture. Furthermore, the weights of the SISTA-RNN are perfectly interpretable as the parameters of a principled statistical model, which in this case include a sparsifying dictionary, iterative step size, and regularization parameters. In addition, on a particular sequential compressive sensing task, the SISTA-RNN trains faster and achieves better performance than conventional state-of-the-art black box RNNs, including long-short term memory (LSTM) RNNs.
Full-Capacity Unitary Recurrent Neural Networks
Oct 31, 2016Recurrent neural networks are powerful models for processing sequential data, but they are generally plagued by vanishing and exploding gradient problems. Unitary recurrent neural networks (uRNNs), which use unitary recurrence matrices, have recently been proposed as a means to avoid these issues. However, in previous experiments, the recurrence matrices were restricted to be a product of parameterized unitary matrices, and an open question remains: when does such a parameterization fail to represent all unitary matrices, and how does this restricted representational capacity limit what can be learned? To address this question, we propose full-capacity uRNNs that optimize their recurrence matrix over all unitary matrices, leading to significantly improved performance over uRNNs that use a restricted-capacity recurrence matrix. Our contribution consists of two main components. First, we provide a theoretical argument to determine if a unitary parameterization has restricted capacity. Using this argument, we show that a recently proposed unitary parameterization has restricted capacity for hidden state dimension greater than 7. Second, we show how a complete, full-capacity unitary recurrence matrix can be optimized over the differentiable manifold of unitary matrices. The resulting multiplicative gradient step is very simple and does not require gradient clipping or learning rate adaptation. We confirm the utility of our claims by empirically evaluating our new full-capacity uRNNs on both synthetic and natural data, achieving superior performance compared to both LSTMs and the original restricted-capacity uRNNs.
Enhancement and Recognition of Reverberant and Noisy Speech by Extending Its Coherence
Sep 02, 2015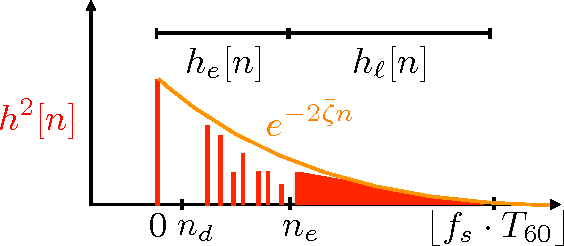
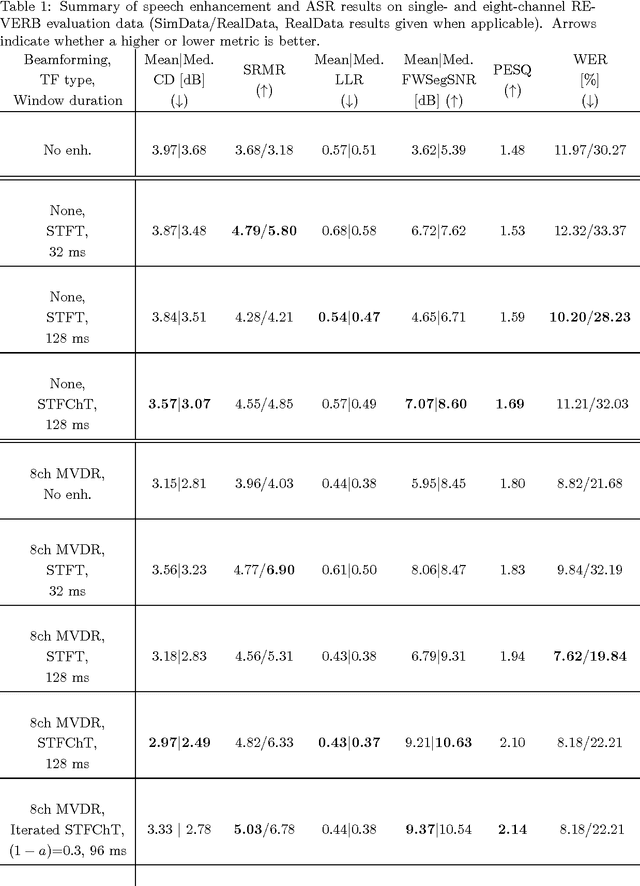
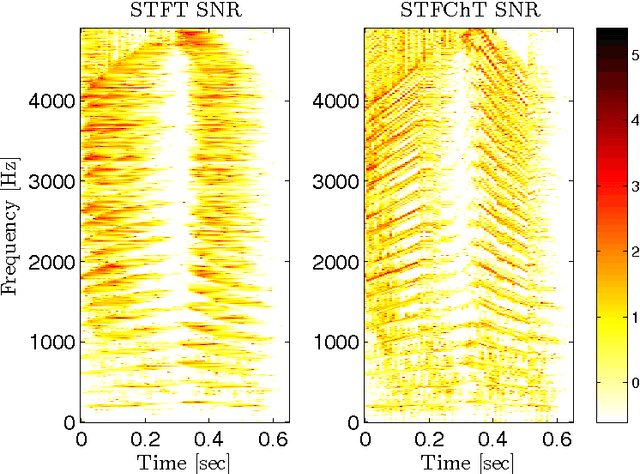
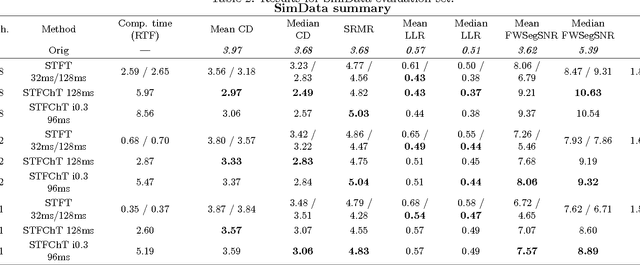
Most speech enhancement algorithms make use of the short-time Fourier transform (STFT), which is a simple and flexible time-frequency decomposition that estimates the short-time spectrum of a signal. However, the duration of short STFT frames are inherently limited by the nonstationarity of speech signals. The main contribution of this paper is a demonstration of speech enhancement and automatic speech recognition in the presence of reverberation and noise by extending the length of analysis windows. We accomplish this extension by performing enhancement in the short-time fan-chirp transform (STFChT) domain, an overcomplete time-frequency representation that is coherent with speech signals over longer analysis window durations than the STFT. This extended coherence is gained by using a linear model of fundamental frequency variation of voiced speech signals. Our approach centers around using a single-channel minimum mean-square error log-spectral amplitude (MMSE-LSA) estimator proposed by Habets, which scales coefficients in a time-frequency domain to suppress noise and reverberation. In the case of multiple microphones, we preprocess the data with either a minimum variance distortionless response (MVDR) beamformer, or a delay-and-sum beamformer (DSB). We evaluate our algorithm on both speech enhancement and recognition tasks for the REVERB challenge dataset. Compared to the same processing done in the STFT domain, our approach achieves significant improvement in terms of objective enhancement metrics (including PESQ---the ITU-T standard measurement for speech quality). In terms of automatic speech recognition (ASR) performance as measured by word error rate (WER), our experiments indicate that the STFT with a long window is more effective for ASR.