 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Corner Patches: Semantics-Aware Backdoor Attack in Federated Learning
Mar 31, 2026Backdoor attacks on federated learning (FL) are most often evaluated with synthetic corner patches or out-of-distribution (OOD) patterns that are unlikely to arise in practice. In this paper, we revisit the backdoor threat to standard FL (a single global model) under a more realistic setting where triggers must be semantically meaningful, in-distribution, and visually plausible. We propose SABLE, a Semantics-Aware Backdoor for LEarning in federated settings, which constructs natural, content-consistent triggers (e.g., semantic attribute changes such as sunglasses) and optimizes an aggregation-aware malicious objective with feature separation and parameter regularization to keep attacker updates close to benign ones. We instantiate SABLE on CelebA hair-color classification and the German Traffic Sign Recognition Benchmark (GTSRB), poisoning only a small, interpretable subset of each malicious client's local data while otherwise following the standard FL protocol. Across heterogeneous client partitions and multiple aggregation rules (FedAvg, Trimmed Mean, MultiKrum, and FLAME), our semantics-driven triggers achieve high targeted attack success rates while preserving benign test accuracy. These results show that semantics-aligned backdoors remain a potent and practical threat in federated learning, and that robustness claims based solely on synthetic patch triggers can be overly optimistic.
Hubs and Spokes Learning: Efficient and Scalable Collaborative Machine Learning
Apr 29, 2025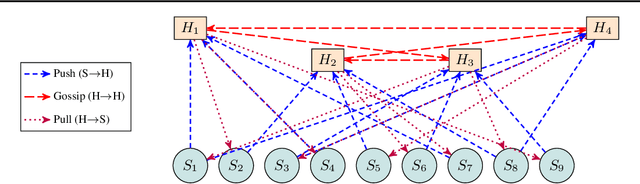
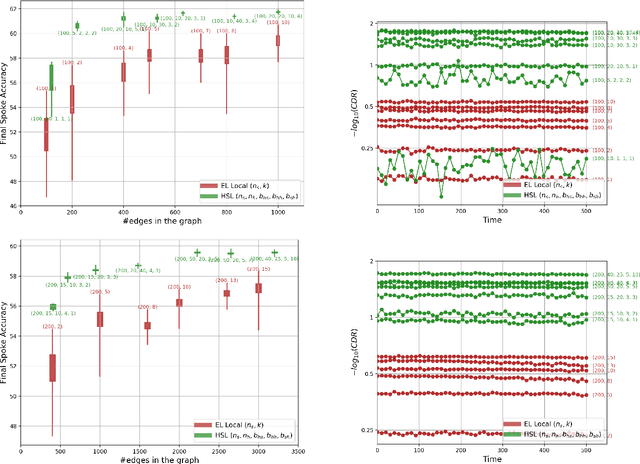
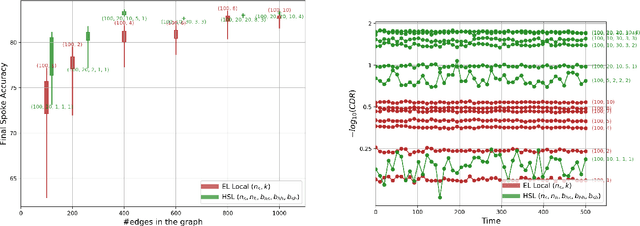
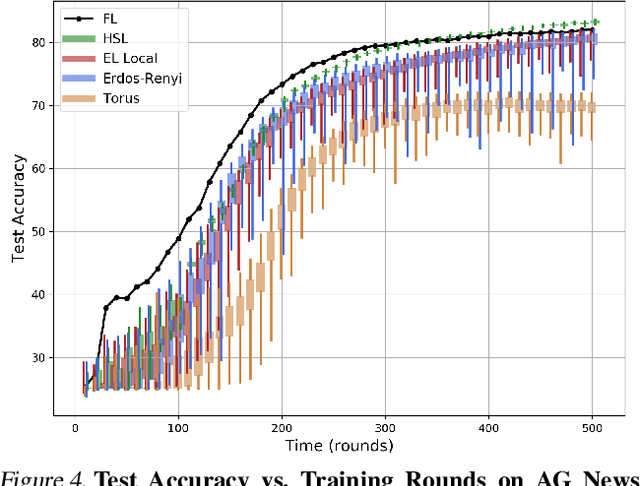
We introduce the Hubs and Spokes Learning (HSL) framework, a novel paradigm for collaborative machine learning that combines the strengths of Federated Learning (FL) and Decentralized Learning (P2PL). HSL employs a two-tier communication structure that avoids the single point of failure inherent in FL and outperforms the state-of-the-art P2PL framework, Epidemic Learning Local (ELL). At equal communication budgets (total edges), HSL achieves higher performance than ELL, while at significantly lower communication budgets, it can match ELL's performance. For instance, with only 400 edges, HSL reaches the same test accuracy that ELL achieves with 1000 edges for 100 peers (spokes) on CIFAR-10, demonstrating its suitability for resource-constrained systems. HSL also achieves stronger consensus among nodes after mixing, resulting in improved performance with fewer training rounds. We substantiate these claims through rigorous theoretical analyses and extensive experimental results, showcasing HSL's practicality for large-scale collaborative learning.