 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Cleansing for GANs
Apr 01, 2025



As the application of generative adversarial networks (GANs) expands, it becomes increasingly critical to develop a unified approach that improves performance across various generative tasks. One effective strategy that applies to any machine learning task is identifying harmful instances, whose removal improves the performance. While previous studies have successfully estimated these harmful training instances in supervised settings, their approaches are not easily applicable to GANs. The challenge lies in two requirements of the previous approaches that do not apply to GANs. First, previous approaches require that the absence of a training instance directly affects the parameters. However, in the training for GANs, the instances do not directly affect the generator's parameters since they are only fed into the discriminator. Second, previous approaches assume that the change in loss directly quantifies the harmfulness of the instance to a model's performance, while common types of GAN losses do not always reflect the generative performance. To overcome the first challenge, we propose influence estimation methods that use the Jacobian of the generator's gradient with respect to the discriminator's parameters (and vice versa). Such a Jacobian represents the indirect effect between two models: how removing an instance from the discriminator's training changes the generator's parameters. Second, we propose an instance evaluation scheme that measures the harmfulness of each training instance based on how a GAN evaluation metric (e.g., Inception score) is expected to change by the instance's removal. Furthermore, we demonstrate that removing the identified harmful instances significantly improves the generative performance on various GAN evaluation metrics.
Rule Mining for Correcting Classification Models
Oct 14, 2023Machine learning models need to be continually updated or corrected to ensure that the prediction accuracy remains consistently high. In this study, we consider scenarios where developers should be careful to change the prediction results by the model correction, such as when the model is part of a complex system or software. In such scenarios, the developers want to control the specification of the corrections. To achieve this, the developers need to understand which subpopulations of the inputs get inaccurate predictions by the model. Therefore, we propose correction rule mining to acquire a comprehensive list of rules that describe inaccurate subpopulations and how to correct them. We also develop an efficient correction rule mining algorithm that is a combination of frequent itemset mining and a unique pruning technique for correction rules. We observed that the proposed algorithm found various rules which help to collect data insufficiently learned, directly correct model outputs, and analyze concept drift.
Personalized Decentralized Bilevel Optimization over Stochastic and Directed Networks
Oct 05, 2022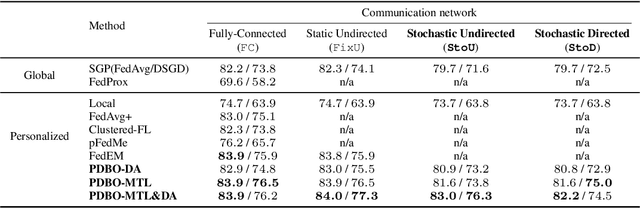
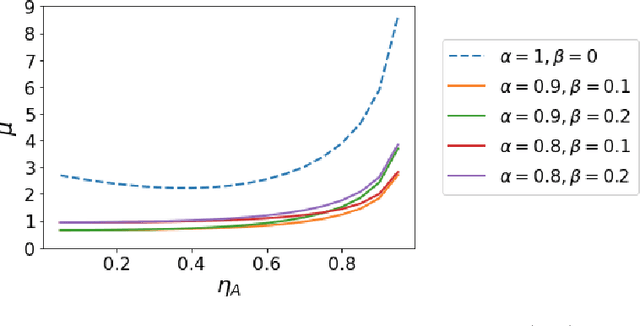
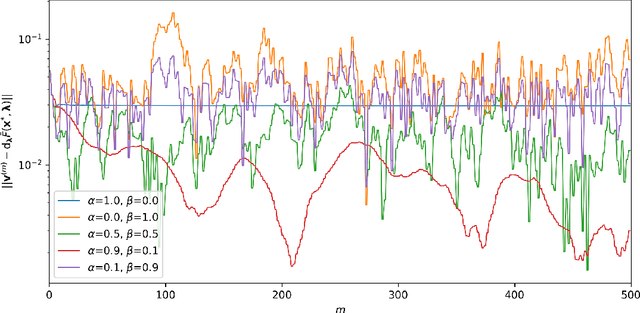
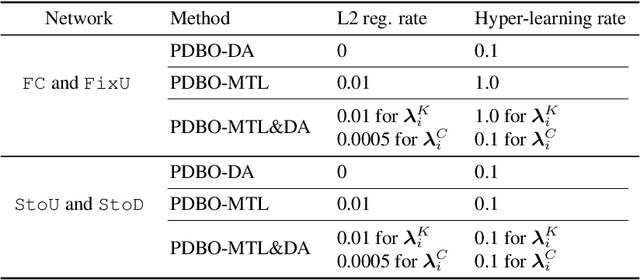
While personalization in distributed learning has been extensively studied, existing approaches employ dedicated algorithms to optimize their specific type of parameters (e.g., client clusters or model interpolation weights), making it difficult to simultaneously optimize different types of parameters to yield better performance. Moreover, their algorithms require centralized or static undirected communication networks, which can be vulnerable to center-point failures or deadlocks. This study proposes optimizing various types of parameters using a single algorithm that runs on more practical communication environments. First, we propose a gradient-based bilevel optimization that reduces most personalization approaches to the optimization of client-wise hyperparameters. Second, we propose a decentralized algorithm to estimate gradients with respect to the hyperparameters, which can run even on stochastic and directed communication networks. Our empirical results demonstrated that the gradient-based bilevel optimization enabled combining existing personalization approaches which led to state-of-the-art performance, confirming it can perform on multiple simulated communication environments including a stochastic and directed network.
Fooling SHAP with Stealthily Biased Sampling
May 30, 2022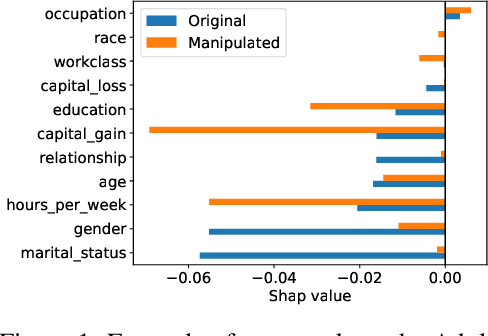
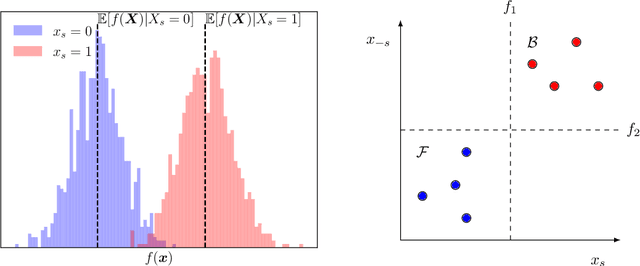

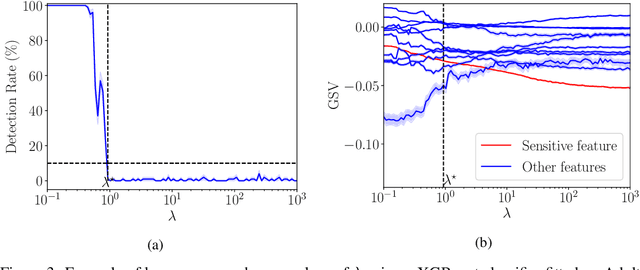
SHAP explanations aim at identifying which features contribute the most to the difference in model prediction at a specific input versus a background distribution. Recent studies have shown that they can be manipulated by malicious adversaries to produce arbitrary desired explanations. However, existing attacks focus solely on altering the black-box model itself. In this paper, we propose a complementary family of attacks that leave the model intact and manipulate SHAP explanations using stealthily biased sampling of the data points used to approximate expectations w.r.t the background distribution. In the context of fairness audit, we show that our attack can reduce the importance of a sensitive feature when explaining the difference in outcomes between groups, while remaining undetected. These results highlight the manipulability of SHAP explanations and encourage auditors to treat post-hoc explanations with skepticism.
Characterizing the risk of fairwashing
Jun 14, 2021
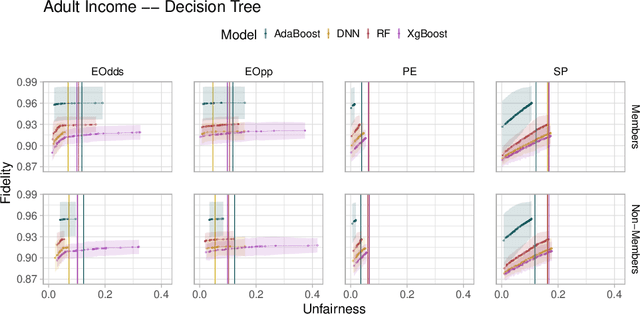
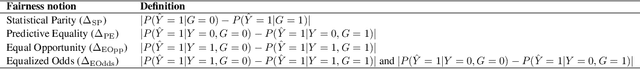

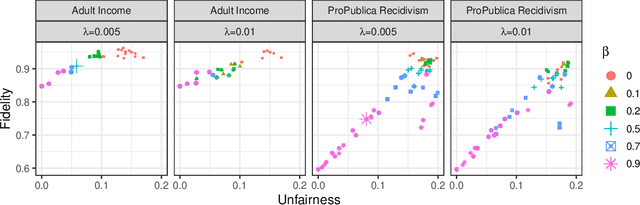
Fairwashing refers to the risk that an unfair black-box model can be explained by a fairer model through post-hoc explanations' manipulation. However, to realize this, the post-hoc explanation model must produce different predictions than the original black-box on some inputs, leading to a decrease in the fidelity imposed by the difference in unfairness. In this paper, our main objective is to characterize the risk of fairwashing attacks, in particular by investigating the fidelity-unfairness trade-off. First, we demonstrate through an in-depth empirical study on black-box models trained on several real-world datasets and for several statistical notions of fairness that it is possible to build high-fidelity explanation models with low unfairness. For instance, we find that fairwashed explanation models can exhibit up to $99.20\%$ fidelity to the black-box models they explain while being $50\%$ less unfair. These results suggest that fidelity alone should not be used as a proxy for the quality of black-box explanations. Second, we show that fairwashed explanation models can generalize beyond the suing group (\emph{i.e.}, data points that are being explained), which will only worsen as more stable fairness methods get developed. Finally, we demonstrate that fairwashing attacks can transfer across black-box models, meaning that other black-box models can perform fairwashing without explicitly using their predictions.
Evaluation Criteria for Instance-based Explanation
Jun 08, 2020

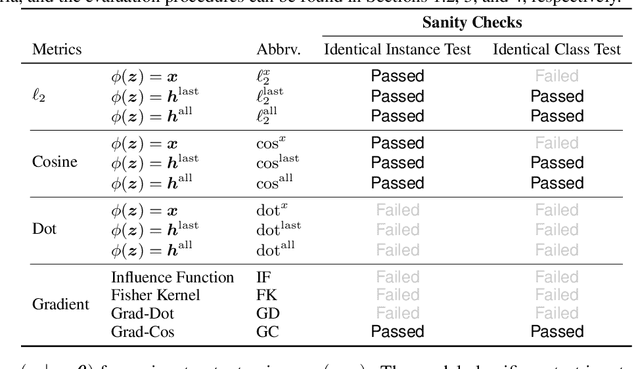
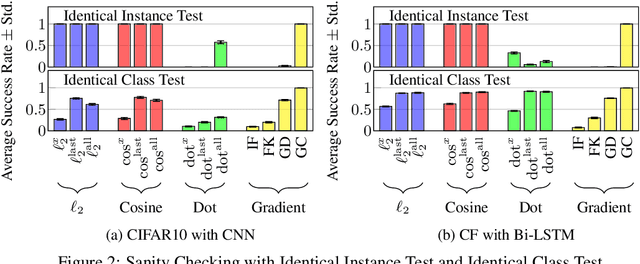
Explaining predictions made by complex machine learning models helps users understand and accept the predicted outputs with confidence. Instance-based explanation provides such help by identifying relevant instances as evidence to support a model's prediction result. To find relevant instances, several relevance metrics have been proposed. In this study, we ask the following research question: "Do the metrics actually work in practice?" To address this question, we propose two sanity check criteria that valid metrics should pass, and two additional criteria to evaluate the practical utility of the metrics. All criteria are designed in terms of whether the metric can pick up instances of desirable properties that the users expect in practice. Through experiments, we obtained two insights. First, some popular relevance metrics do not pass sanity check criteria. Second, some metrics based on cosine similarity perform better than other metrics, which would be recommended choices in practice. We also analyze why some metrics are successful and why some are not. We expect our insights to help further researches such as developing better explanation methods or designing new evaluation criteria.
Interpretable Companions for Black-Box Models
Feb 11, 2020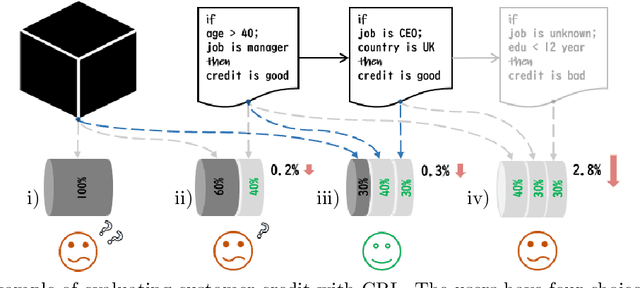
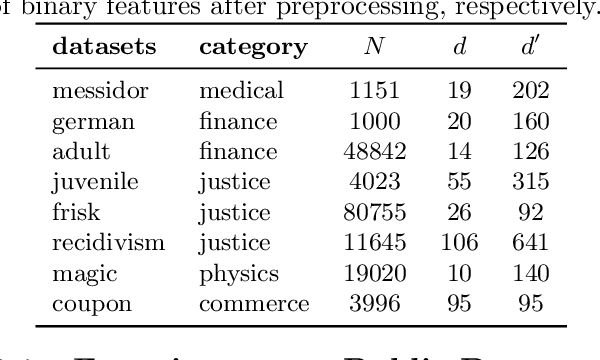
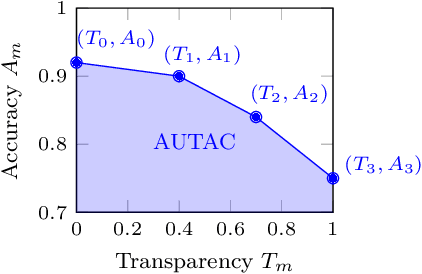
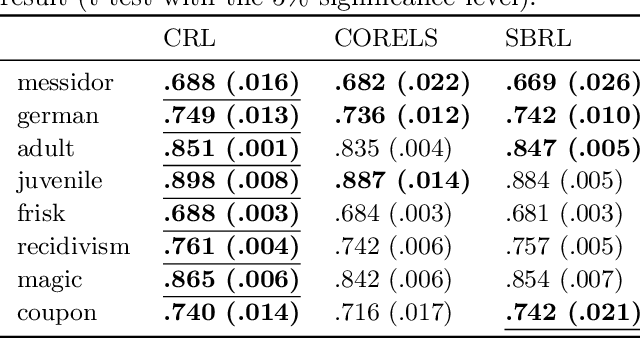
We present an interpretable companion model for any pre-trained black-box classifiers. The idea is that for any input, a user can decide to either receive a prediction from the black-box model, with high accuracy but no explanations, or employ a companion rule to obtain an interpretable prediction with slightly lower accuracy. The companion model is trained from data and the predictions of the black-box model, with the objective combining area under the transparency--accuracy curve and model complexity. Our model provides flexible choices for practitioners who face the dilemma of choosing between always using interpretable models and always using black-box models for a predictive task, so users can, for any given input, take a step back to resort to an interpretable prediction if they find the predictive performance satisfying, or stick to the black-box model if the rules are unsatisfying. To show the value of companion models, we design a human evaluation on more than a hundred people to investigate the tolerable accuracy loss to gain interpretability for humans.
Data Cleansing for Models Trained with SGD
Jun 20, 2019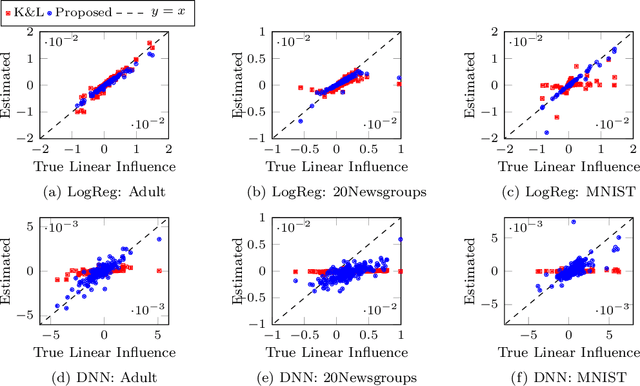

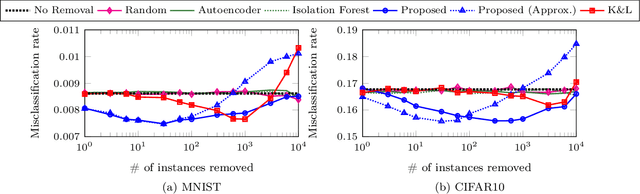
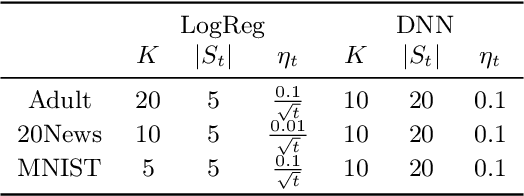
Data cleansing is a typical approach used to improve the accuracy of machine learning models, which, however, requires extensive domain knowledge to identify the influential instances that affect the models. In this paper, we propose an algorithm that can suggest influential instances without using any domain knowledge. With the proposed method, users only need to inspect the instances suggested by the algorithm, implying that users do not need extensive knowledge for this procedure, which enables even non-experts to conduct data cleansing and improve the model. The existing methods require the loss function to be convex and an optimal model to be obtained, which is not always the case in modern machine learning. To overcome these limitations, we propose a novel approach specifically designed for the models trained with stochastic gradient descent (SGD). The proposed method infers the influential instances by retracing the steps of the SGD while incorporating intermediate models computed in each step. Through experiments, we demonstrate that the proposed method can accurately infer the influential instances. Moreover, we used MNIST and CIFAR10 to show that the models can be effectively improved by removing the influential instances suggested by the proposed method.
Enumeration of Distinct Support Vectors for Interactive Decision Making
Jun 05, 2019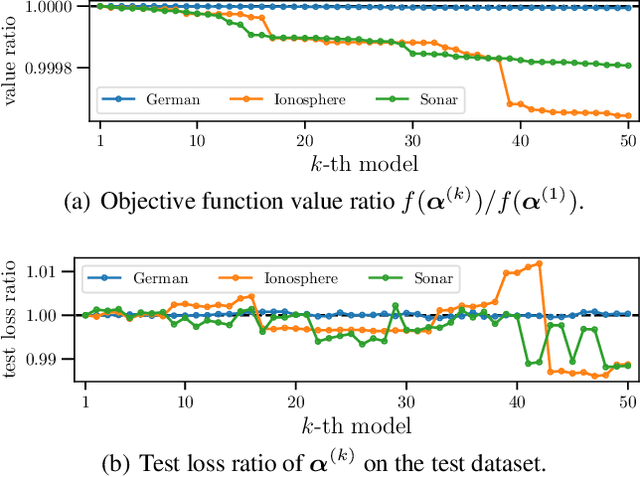
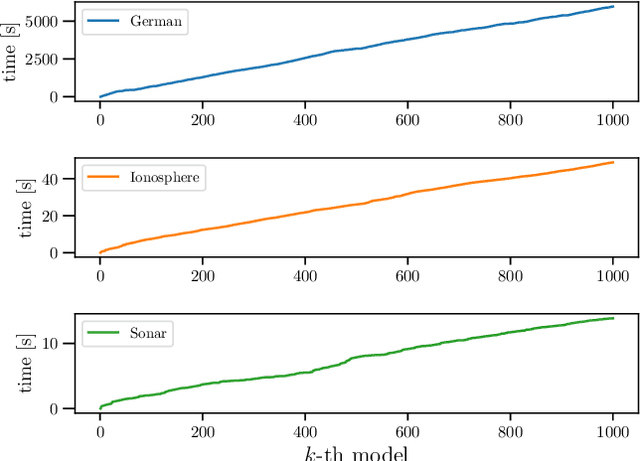
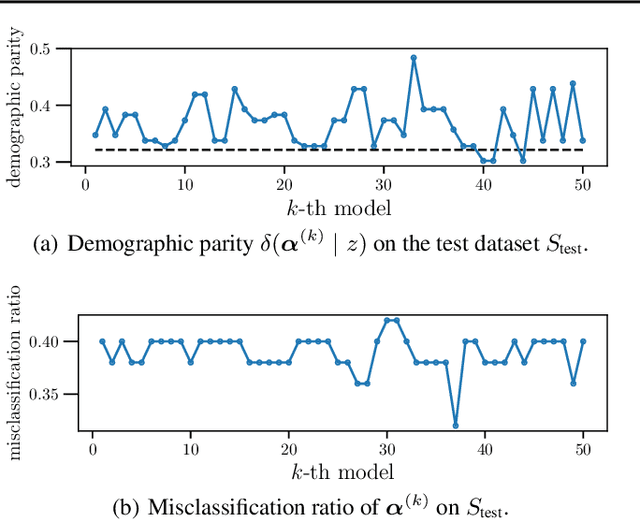
In conventional prediction tasks, a machine learning algorithm outputs a single best model that globally optimizes its objective function, which typically is accuracy. Therefore, users cannot access the other models explicitly. In contrast to this, multiple model enumeration attracts increasing interests in non-standard machine learning applications where other criteria, e.g., interpretability or fairness, than accuracy are main concern and a user may want to access more than one non-optimal, but suitable models. In this paper, we propose a K-best model enumeration algorithm for Support Vector Machines (SVM) that given a dataset S and an integer K>0, enumerates the K-best models on S with distinct support vectors in the descending order of the objective function values in the dual SVM problem. Based on analysis of the lattice structure of support vectors, our algorithm efficiently finds the next best model with small latency. This is useful in supporting users's interactive examination of their requirements on enumerated models. By experiments on real datasets, we evaluated the efficiency and usefulness of our algorithm.
Fairwashing: the risk of rationalization
Jan 28, 2019
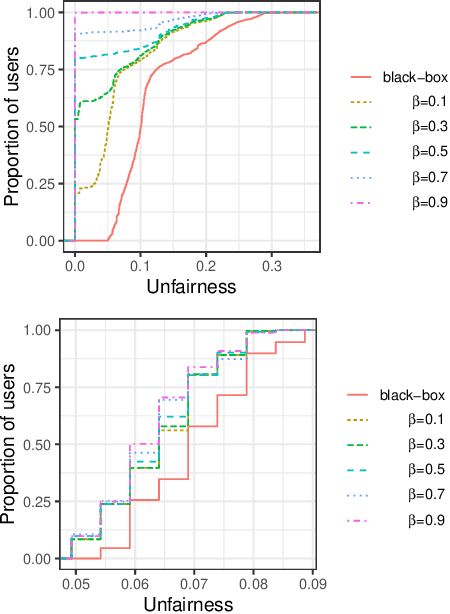
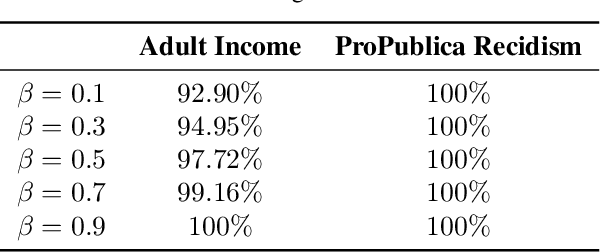
Black-box explanation is the problem of explaining how a machine learning model -- whose internal logic is hidden to the auditor and generally complex -- produces its outcomes. Current approaches for solving this problem include model explanation, outcome explanation as well as model inspection. While these techniques can be beneficial by providing interpretability, they can be used in a negative manner to perform fairwashing, which we define as promoting the perception that a machine learning model respects some ethical values while it might not be the case. In particular, we demonstrate that it is possible to systematically rationalize decisions taken by an unfair black-box model using the model explanation as well as the outcome explanation approaches with a given fairness metric. Our solution, LaundryML, is based on a regularized rule list enumeration algorithm whose objective is to search for fair rule lists approximating an unfair black-box model. We empirically evaluate our rationalization technique on black-box models trained on real-world datasets and show that one can obtain rule lists with high fidelity to the black-box model while being considerably less unfair at the same time.