 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Visual Encoder Learn to See Arrows?
May 26, 2025



The diagram is a visual representation of a relationship illustrated with edges (lines or arrows), which is widely used in industrial and scientific communication. Although recognizing diagrams is essential for vision language models (VLMs) to comprehend domain-specific knowledge, recent studies reveal that many VLMs fail to identify edges in images. We hypothesize that these failures stem from an over-reliance on textual and positional biases, preventing VLMs from learning explicit edge features. Based on this idea, we empirically investigate whether the image encoder in VLMs can learn edge representation through training on a diagram dataset in which edges are biased neither by textual nor positional information. To this end, we conduct contrastive learning on an artificially generated diagram--caption dataset to train an image encoder and evaluate its diagram-related features on three tasks: probing, image retrieval, and captioning. Our results show that the finetuned model outperforms pretrained CLIP in all tasks and surpasses zero-shot GPT-4o and LLaVA-Mistral in the captioning task. These findings confirm that eliminating textual and positional biases fosters accurate edge recognition in VLMs, offering a promising path for advancing diagram understanding.
Data Cleansing for GANs
Apr 01, 2025



As the application of generative adversarial networks (GANs) expands, it becomes increasingly critical to develop a unified approach that improves performance across various generative tasks. One effective strategy that applies to any machine learning task is identifying harmful instances, whose removal improves the performance. While previous studies have successfully estimated these harmful training instances in supervised settings, their approaches are not easily applicable to GANs. The challenge lies in two requirements of the previous approaches that do not apply to GANs. First, previous approaches require that the absence of a training instance directly affects the parameters. However, in the training for GANs, the instances do not directly affect the generator's parameters since they are only fed into the discriminator. Second, previous approaches assume that the change in loss directly quantifies the harmfulness of the instance to a model's performance, while common types of GAN losses do not always reflect the generative performance. To overcome the first challenge, we propose influence estimation methods that use the Jacobian of the generator's gradient with respect to the discriminator's parameters (and vice versa). Such a Jacobian represents the indirect effect between two models: how removing an instance from the discriminator's training changes the generator's parameters. Second, we propose an instance evaluation scheme that measures the harmfulness of each training instance based on how a GAN evaluation metric (e.g., Inception score) is expected to change by the instance's removal. Furthermore, we demonstrate that removing the identified harmful instances significantly improves the generative performance on various GAN evaluation metrics.
Personalized Decentralized Bilevel Optimization over Stochastic and Directed Networks
Oct 05, 2022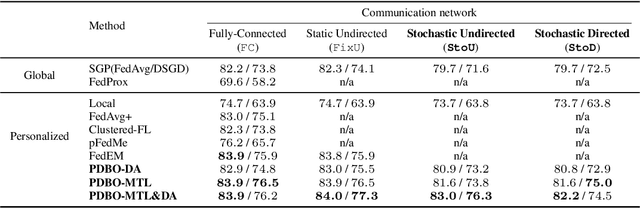
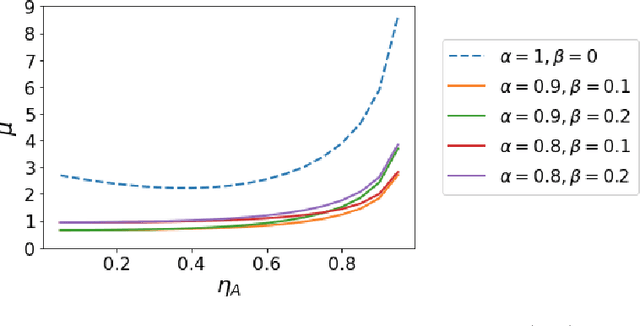
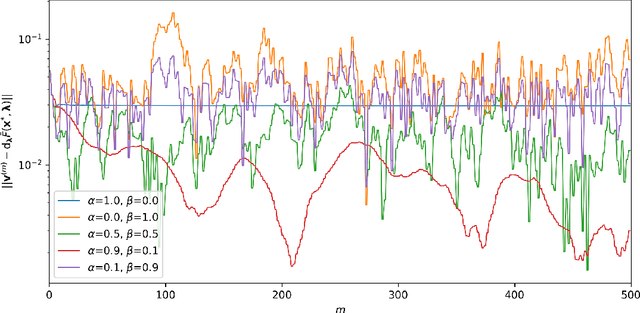
While personalization in distributed learning has been extensively studied, existing approaches employ dedicated algorithms to optimize their specific type of parameters (e.g., client clusters or model interpolation weights), making it difficult to simultaneously optimize different types of parameters to yield better performance. Moreover, their algorithms require centralized or static undirected communication networks, which can be vulnerable to center-point failures or deadlocks. This study proposes optimizing various types of parameters using a single algorithm that runs on more practical communication environments. First, we propose a gradient-based bilevel optimization that reduces most personalization approaches to the optimization of client-wise hyperparameters. Second, we propose a decentralized algorithm to estimate gradients with respect to the hyperparameters, which can run even on stochastic and directed communication networks. Our empirical results demonstrated that the gradient-based bilevel optimization enabled combining existing personalization approaches which led to state-of-the-art performance, confirming it can perform on multiple simulated communication environments including a stochastic and directed network.
Influence Estimation for Generative Adversarial Networks
Jan 20, 2021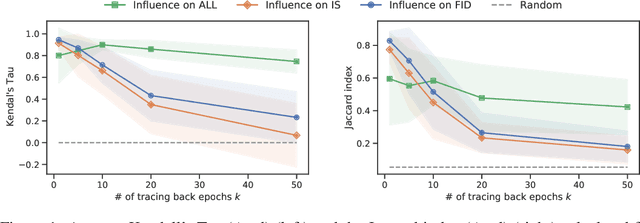

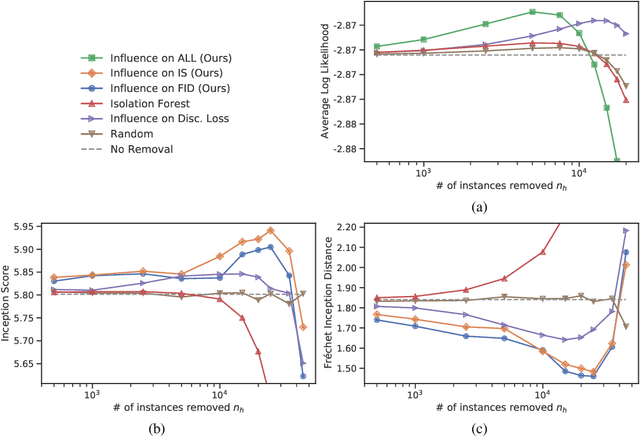

Identifying harmful instances, whose absence in a training dataset improves model performance, is important for building better machine learning models. Although previous studies have succeeded in estimating harmful instances under supervised settings, they cannot be trivially extended to generative adversarial networks (GANs). This is because previous approaches require that (1) the absence of a training instance directly affects the loss value and that (2) the change in the loss directly measures the harmfulness of the instance for the performance of a model. In GAN training, however, neither of the requirements is satisfied. This is because, (1) the generator's loss is not directly affected by the training instances as they are not part of the generator's training steps, and (2) the values of GAN's losses normally do not capture the generative performance of a model. To this end, (1) we propose an influence estimation method that uses the Jacobian of the gradient of the generator's loss with respect to the discriminator's parameters (and vice versa) to trace how the absence of an instance in the discriminator's training affects the generator's parameters, and (2) we propose a novel evaluation scheme, in which we assess harmfulness of each training instance on the basis of how GAN evaluation metric (e.g., inception score) is expect to change due to the removal of the instance. We experimentally verified that our influence estimation method correctly inferred the changes in GAN evaluation metrics. Further, we demonstrated that the removal of the identified harmful instances effectively improved the model's generative performance with respect to various GAN evaluation metrics.