 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Prediction Network
Nov 06, 2017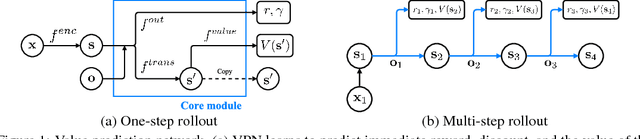
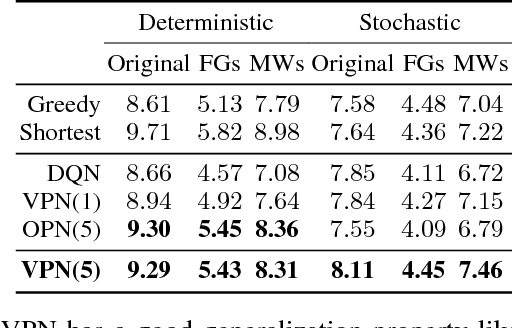
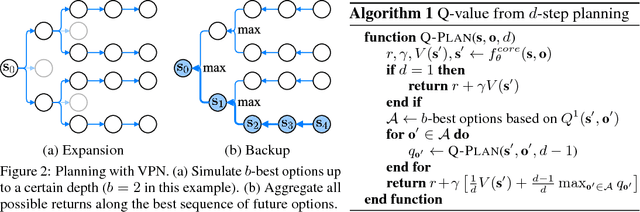

This paper proposes a novel deep reinforcement learning (RL) architecture, called Value Prediction Network (VPN), which integrates model-free and model-based RL methods into a single neural network. In contrast to typical model-based RL methods, VPN learns a dynamics model whose abstract states are trained to make option-conditional predictions of future values (discounted sum of rewards) rather than of future observations. Our experimental results show that VPN has several advantages over both model-free and model-based baselines in a stochastic environment where careful planning is required but building an accurate observation-prediction model is difficult. Furthermore, VPN outperforms Deep Q-Network (DQN) on several Atari games even with short-lookahead planning, demonstrating its potential as a new way of learning a good state representation.
Repeated Inverse Reinforcement Learning
Nov 04, 2017We introduce a novel repeated Inverse Reinforcement Learning problem: the agent has to act on behalf of a human in a sequence of tasks and wishes to minimize the number of tasks that it surprises the human by acting suboptimally with respect to how the human would have acted. Each time the human is surprised, the agent is provided a demonstration of the desired behavior by the human. We formalize this problem, including how the sequence of tasks is chosen, in a few different ways and provide some foundational results.
Minimizing Maximum Regret in Commitment Constrained Sequential Decision Making
Mar 14, 2017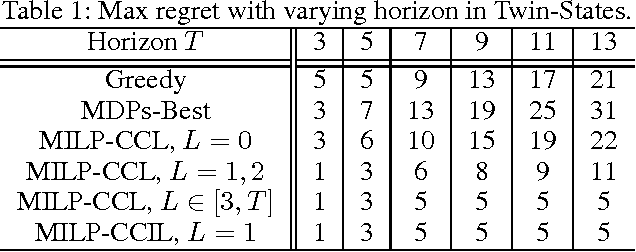
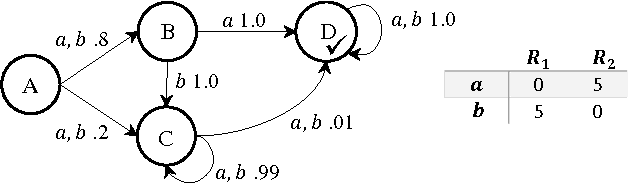
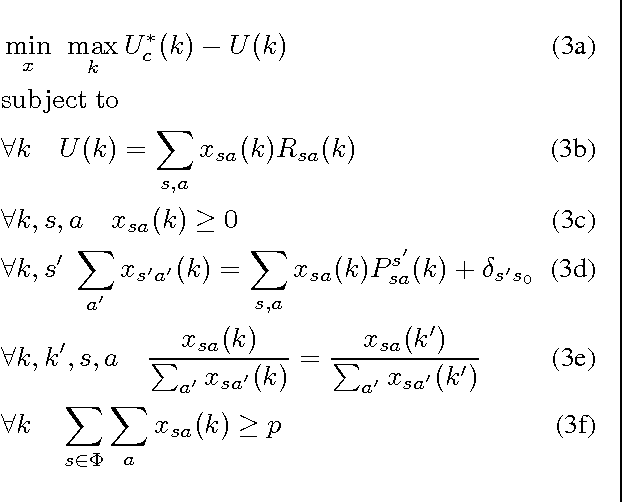
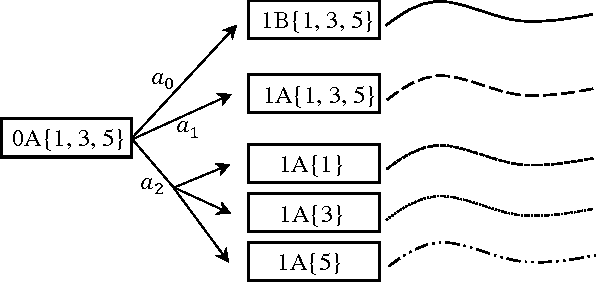
In cooperative multiagent planning, it can often be beneficial for an agent to make commitments about aspects of its behavior to others, allowing them in turn to plan their own behaviors without taking the agent's detailed behavior into account. Extending previous work in the Bayesian setting, we consider instead a worst-case setting in which the agent has a set of possible environments (MDPs) it could be in, and develop a commitment semantics that allows for probabilistic guarantees on the agent's behavior in any of the environments it could end up facing. Crucially, an agent receives observations (of reward and state transitions) that allow it to potentially eliminate possible environments and thus obtain higher utility by adapting its policy to the history of observations. We develop algorithms and provide theory and some preliminary empirical results showing that they ensure an agent meets its commitments with history-dependent policies while minimizing maximum regret over the possible environments.
Control of Memory, Active Perception, and Action in Minecraft
May 30, 2016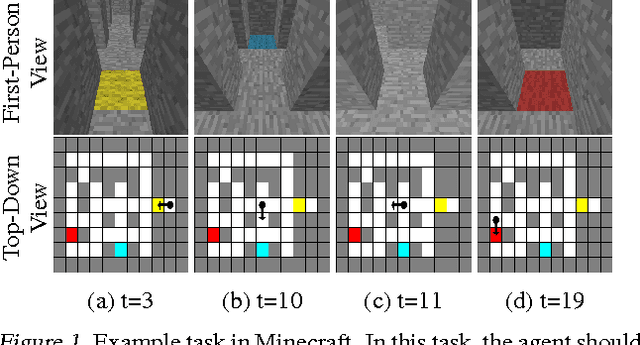
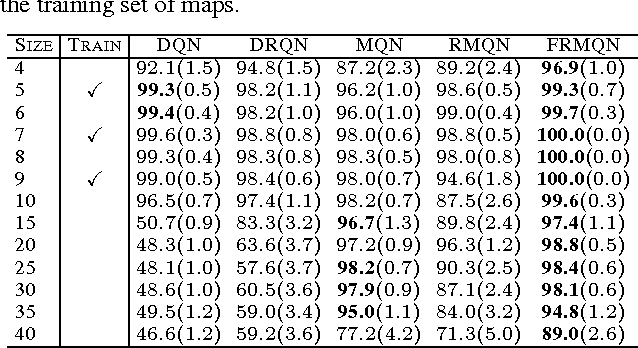
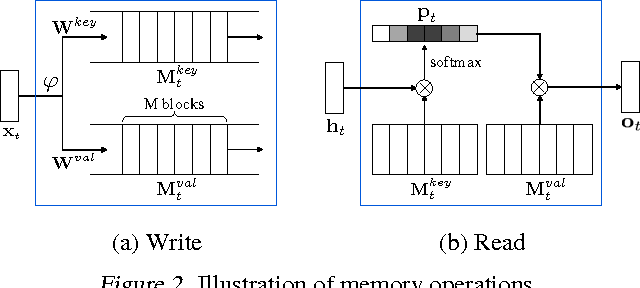
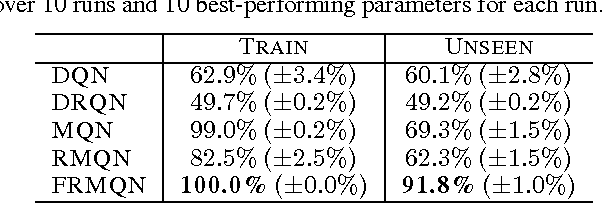
In this paper, we introduce a new set of reinforcement learning (RL) tasks in Minecraft (a flexible 3D world). We then use these tasks to systematically compare and contrast existing deep reinforcement learning (DRL) architectures with our new memory-based DRL architectures. These tasks are designed to emphasize, in a controllable manner, issues that pose challenges for RL methods including partial observability (due to first-person visual observations), delayed rewards, high-dimensional visual observations, and the need to use active perception in a correct manner so as to perform well in the tasks. While these tasks are conceptually simple to describe, by virtue of having all of these challenges simultaneously they are difficult for current DRL architectures. Additionally, we evaluate the generalization performance of the architectures on environments not used during training. The experimental results show that our new architectures generalize to unseen environments better than existing DRL architectures.
Deep Learning for Reward Design to Improve Monte Carlo Tree Search in ATARI Games
Apr 24, 2016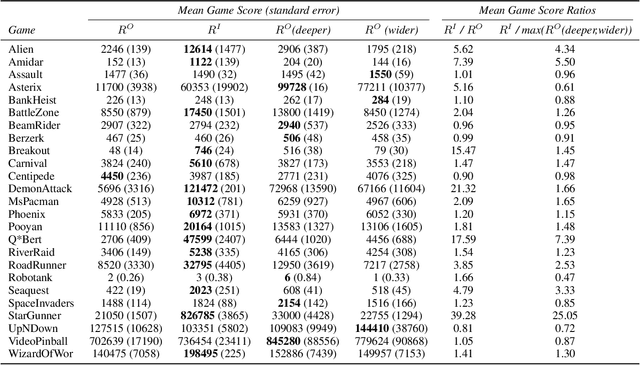
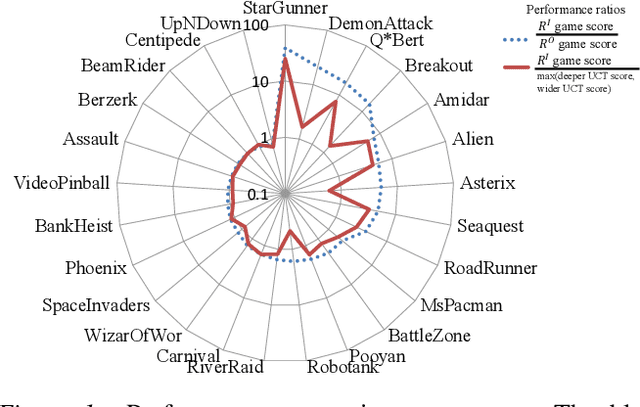
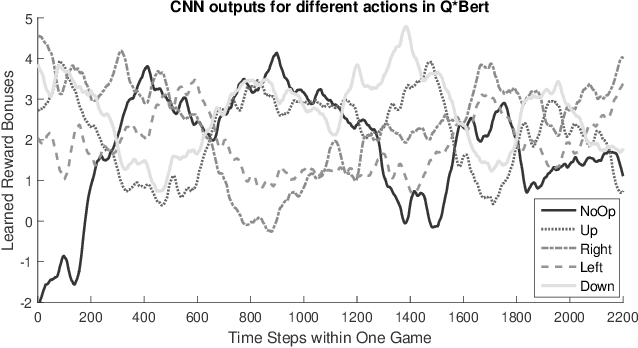
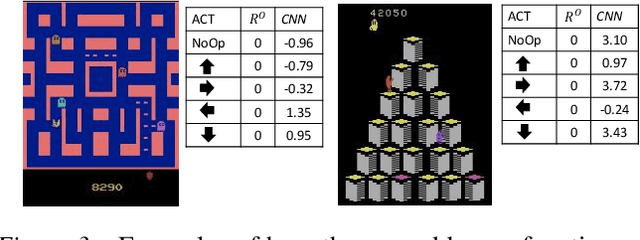
Monte Carlo Tree Search (MCTS) methods have proven powerful in planning for sequential decision-making problems such as Go and video games, but their performance can be poor when the planning depth and sampling trajectories are limited or when the rewards are sparse. We present an adaptation of PGRD (policy-gradient for reward-design) for learning a reward-bonus function to improve UCT (a MCTS algorithm). Unlike previous applications of PGRD in which the space of reward-bonus functions was limited to linear functions of hand-coded state-action-features, we use PGRD with a multi-layer convolutional neural network to automatically learn features from raw perception as well as to adapt the non-linear reward-bonus function parameters. We also adopt a variance-reducing gradient method to improve PGRD's performance. The new method improves UCT's performance on multiple ATARI games compared to UCT without the reward bonus. Combining PGRD and Deep Learning in this way should make adapting rewards for MCTS algorithms far more widely and practically applicable than before.
Towards Resolving Unidentifiability in Inverse Reinforcement Learning
Jan 25, 2016
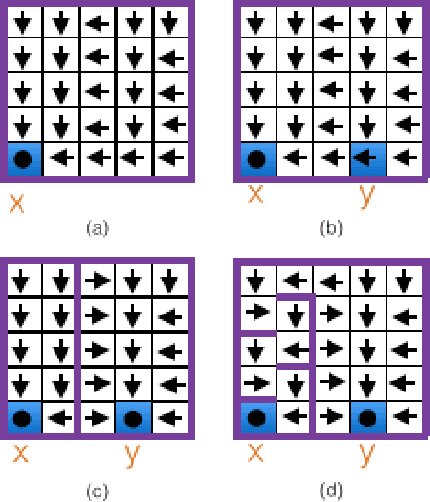
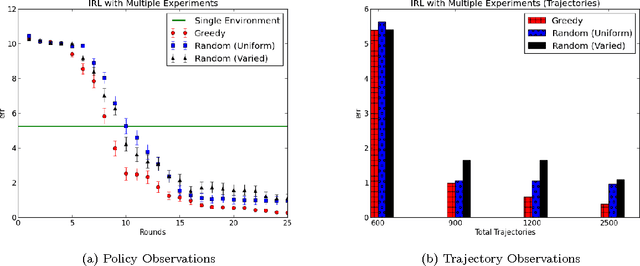
We consider a setting for Inverse Reinforcement Learning (IRL) where the learner is extended with the ability to actively select multiple environments, observing an agent's behavior on each environment. We first demonstrate that if the learner can experiment with any transition dynamics on some fixed set of states and actions, then there exists an algorithm that reconstructs the agent's reward function to the fullest extent theoretically possible, and that requires only a small (logarithmic) number of experiments. We contrast this result to what is known about IRL in single fixed environments, namely that the true reward function is fundamentally unidentifiable. We then extend this setting to the more realistic case where the learner may not select any transition dynamic, but rather is restricted to some fixed set of environments that it may try. We connect the problem of maximizing the information derived from experiments to submodular function maximization and demonstrate that a greedy algorithm is near optimal (up to logarithmic factors). Finally, we empirically validate our algorithm on an environment inspired by behavioral psychology.
Action-Conditional Video Prediction using Deep Networks in Atari Games
Dec 22, 2015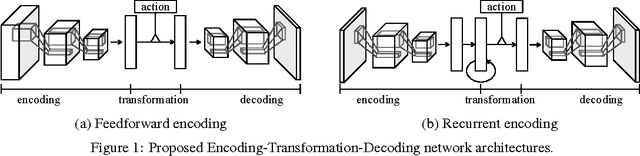
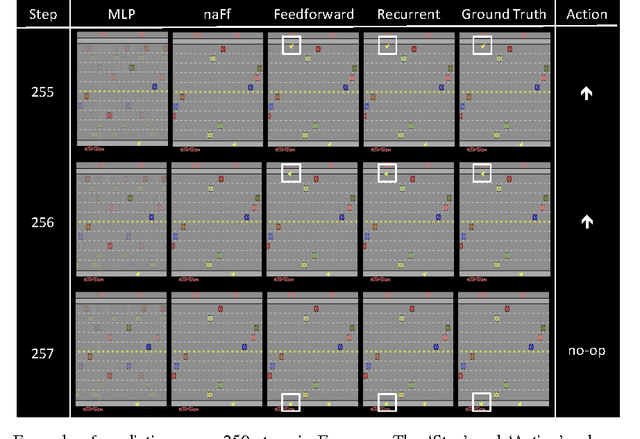
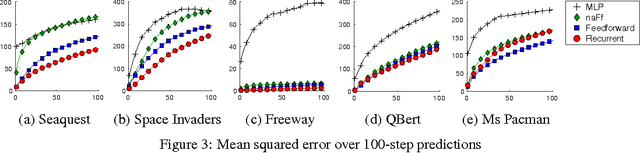
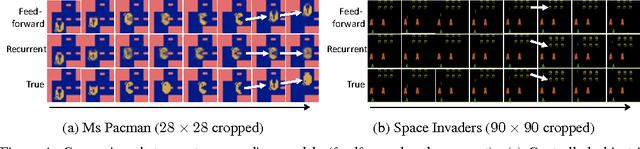
Motivated by vision-based reinforcement learning (RL) problems, in particular Atari games from the recent benchmark Aracade Learning Environment (ALE), we consider spatio-temporal prediction problems where future (image-)frames are dependent on control variables or actions as well as previous frames. While not composed of natural scenes, frames in Atari games are high-dimensional in size, can involve tens of objects with one or more objects being controlled by the actions directly and many other objects being influenced indirectly, can involve entry and departure of objects, and can involve deep partial observability. We propose and evaluate two deep neural network architectures that consist of encoding, action-conditional transformation, and decoding layers based on convolutional neural networks and recurrent neural networks. Experimental results show that the proposed architectures are able to generate visually-realistic frames that are also useful for control over approximately 100-step action-conditional futures in some games. To the best of our knowledge, this paper is the first to make and evaluate long-term predictions on high-dimensional video conditioned by control inputs.
Graphical Models for Game Theory
Mar 08, 2015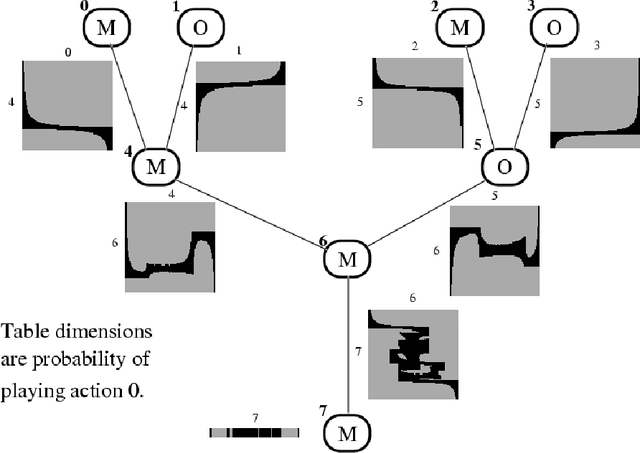
In this work, we introduce graphical modelsfor multi-player game theory, and give powerful algorithms for computing their Nash equilibria in certain cases. An n-player game is given by an undirected graph on n nodes and a set of n local matrices. The interpretation is that the payoff to player i is determined entirely by the actions of player i and his neighbors in the graph, and thus the payoff matrix to player i is indexed only by these players. We thus view the global n-player game as being composed of interacting local games, each involving many fewer players. Each player's action may have global impact, but it occurs through the propagation of local influences.Our main technical result is an efficient algorithm for computing Nash equilibria when the underlying graph is a tree (or can be turned into a tree with few node mergings). The algorithm runs in time polynomial in the size of the representation (the graph and theassociated local game matrices), and comes in two related but distinct flavors. The first version involves an approximation step, and computes a representation of all approximate Nash equilibria (of which there may be an exponential number in general). The second version allows the exact computation of Nash equilibria at the expense of weakened complexity bounds. The algorithm requires only local message-passing between nodes (and thus can be implemented by the players themselves in a distributed manner). Despite an analogy to inference in Bayes nets that we develop, the analysis of our algorithm is more involved than that for the polytree algorithm in, owing partially to the fact that we must either compute, or select from, an exponential number of potential solutions. We discuss a number of extensions, such as the computation of equilibria with desirable global properties (e.g. maximizing global return), and directions for further research.
Learning to Make Predictions In Partially Observable Environments Without a Generative Model
Jan 16, 2014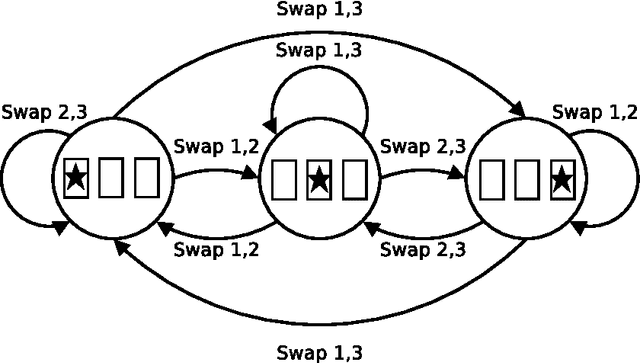
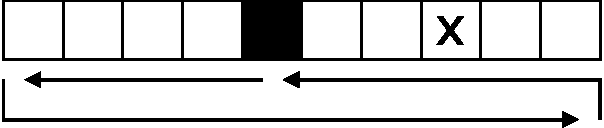
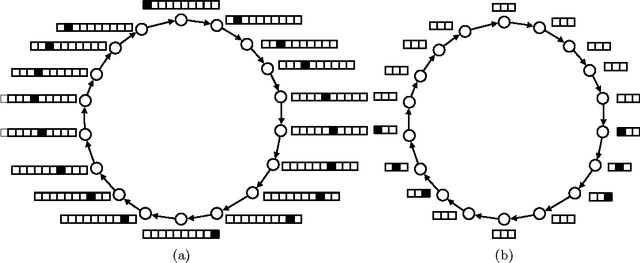
When faced with the problem of learning a model of a high-dimensional environment, a common approach is to limit the model to make only a restricted set of predictions, thereby simplifying the learning problem. These partial models may be directly useful for making decisions or may be combined together to form a more complete, structured model. However, in partially observable (non-Markov) environments, standard model-learning methods learn generative models, i.e. models that provide a probability distribution over all possible futures (such as POMDPs). It is not straightforward to restrict such models to make only certain predictions, and doing so does not always simplify the learning problem. In this paper we present prediction profile models: non-generative partial models for partially observable systems that make only a given set of predictions, and are therefore far simpler than generative models in some cases. We formalize the problem of learning a prediction profile model as a transformation of the original model-learning problem, and show empirically that one can learn prediction profile models that make a small set of important predictions even in systems that are too complex for standard generative models.
Approximate Planning for Factored POMDPs using Belief State Simplification
Jan 23, 2013We are interested in the problem of planning for factored POMDPs. Building on the recent results of Kearns, Mansour and Ng, we provide a planning algorithm for factored POMDPs that exploits the accuracy-efficiency tradeoff in the belief state simplification introduced by Boyen and Koller.