 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Guided 3D Gaussian Splatting for Transient Object Removal
Feb 17, 2026Transient objects in casual multi-view captures cause ghosting artifacts in 3D Gaussian Splatting (3DGS) reconstruction. Existing solutions relied on scene decomposition at significant memory cost or on motion-based heuristics that were vulnerable to parallax ambiguity. A semantic filtering framework was proposed for category-aware transient removal using vision-language models. CLIP similarity scores between rendered views and distractor text prompts were accumulated per-Gaussian across training iterations. Gaussians exceeding a calibrated threshold underwent opacity regularization and periodic pruning. Unlike motion-based approaches, semantic classification resolved parallax ambiguity by identifying object categories independently of motion patterns. Experiments on the RobustNeRF benchmark demonstrated consistent improvement in reconstruction quality over vanilla 3DGS across four sequences, while maintaining minimal memory overhead and real-time rendering performance. Threshold calibration and comparisons with baselines validated semantic guidance as a practical strategy for transient removal in scenarios with predictable distractor categories.
Bidirectional Quantum Processor Interfacing by a 4-Kelvin Analog Signal Chain for Superconducting Qubit Control and Quantum State Readout
Feb 15, 2026This paper presents a comprehensive cryogenic analog signal processing architecture designed for superconducting qubit control and quantum state readout operating at 4 Kelvin. The proposed system implements a complete bidirectional signal path bridging room-temperature digital controllers with quantum processors at millikelvin stages. The control path incorporates a Phase-Locked Loop (PLL) for stable local oscillator generation, In-phase/Quadrature (I/Q) modulation for precise qubit gate operations, and a cryogenic power amplifier for signal conditioning. The readout path features a Low Noise Amplifier (LNA) with 14 dB gain and 8-Phase Shift Keying (8-PSK) demodulation for quantum state discrimination. All circuit blocks are designed and validated through SPICE simulations employing cryogenic MOSFET models at 180nm that account for carrier freeze-out, threshold voltage elevation, and enhanced mobility at 4 K. Simulation results demonstrate successful end-to-end signal integrity with I/Q phase error below 2°, image rejection ratio exceeding 35~dB, and symbol error rate below $10^{-6}$. This work provides a modular, simulation-validated framework for scalable cryogenic quantum control systems.
Dual-Signal Adaptive KV-Cache Optimization for Long-Form Video Understanding in Vision-Language Models
Feb 15, 2026Vision-Language Models (VLMs) face a critical memory bottleneck when processing long-form video content due to the linear growth of the Key-Value (KV) cache with sequence length. Existing solutions predominantly employ reactive eviction strategies that compute full attention matrices before discarding tokens, resulting in substantial computational waste. We propose Sali-Cache, a novel a priori optimization framework that implements dual-signal adaptive caching through proactive memory management. By integrating a temporal filter based on optical flow analysis for detecting inter-frame redundancy and a spatial filter leveraging saliency detection for identifying visually significant regions, Sali-Cache intelligently manages memory allocation before entering computationally expensive attention operations. Experimental evaluation on the LLaVA 1.6 architecture demonstrates that our method achieves a 2.20x compression ratio in effective memory usage while maintaining 100% accuracy across BLEU, ROUGE-L, and Exact Match metrics. Furthermore, under identical memory budget constraints, Sali-Cache preserves context-rich features over extended temporal durations without degrading model performance, enabling efficient processing of long-form video content on consumer-grade hardware.
TernaryLM: Memory-Efficient Language Modeling via Native 1-Bit Quantization with Adaptive Layer-wise Scaling
Feb 07, 2026Large language models (LLMs) achieve remarkable performance but demand substantial computational resources, limiting deployment on edge devices and resource-constrained environments. We present TernaryLM, a 132M parameter transformer architecture that employs native 1-bit ternary quantization {-1, 0, +1} during training, achieving significant memory reduction without sacrificing language modeling capability. Unlike post-training quantization approaches that quantize pre-trained full-precision models, TernaryLM learns quantization-aware representations from scratch using straight-through estimators and adaptive per-layer scaling factors. Our experiments demonstrate: (1) validation perplexity of 58.42 on TinyStories; (2) downstream transfer with 82.47 percent F1 on MRPC paraphrase detection; (3) 2.4x memory reduction (498MB vs 1197MB) with comparable inference latency; and (4) stable training dynamics across diverse corpora. We provide layer-wise quantization analysis showing that middle transformer layers exhibit highest compatibility with extreme quantization, informing future non-uniform precision strategies. Our results suggest that native 1-bit training is a promising direction for efficient neural language models. Code is available at https://github.com/1nisharg/TernaryLM-Memory-Efficient-Language-Modeling.
Navigating the Unknown: Uncertainty-Aware Compute-in-Memory Autonomy of Edge Robotics
Jan 30, 2024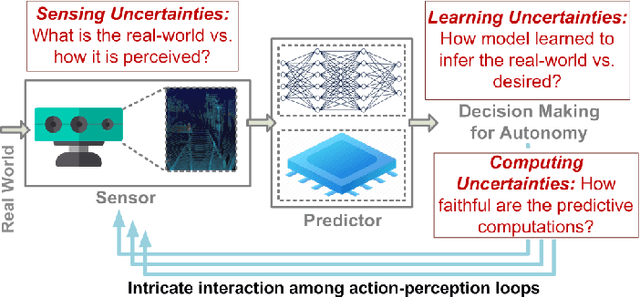
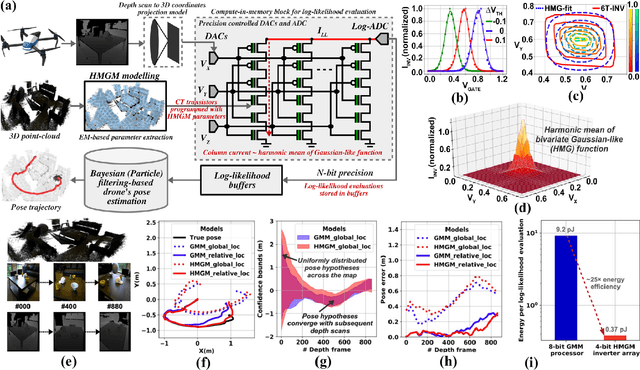
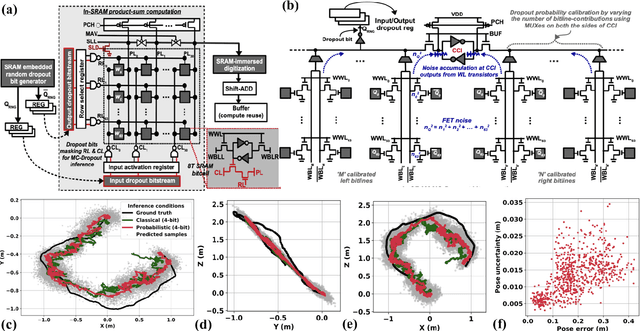
This paper addresses the challenging problem of energy-efficient and uncertainty-aware pose estimation in insect-scale drones, which is crucial for tasks such as surveillance in constricted spaces and for enabling non-intrusive spatial intelligence in smart homes. Since tiny drones operate in highly dynamic environments, where factors like lighting and human movement impact their predictive accuracy, it is crucial to deploy uncertainty-aware prediction algorithms that can account for environmental variations and express not only the prediction but also confidence in the prediction. We address both of these challenges with Compute-in-Memory (CIM) which has become a pivotal technology for deep learning acceleration at the edge. While traditional CIM techniques are promising for energy-efficient deep learning, to bring in the robustness of uncertainty-aware predictions at the edge, we introduce a suite of novel techniques: First, we discuss CIM-based acceleration of Bayesian filtering methods uniquely by leveraging the Gaussian-like switching current of CMOS inverters along with co-design of kernel functions to operate with extreme parallelism and with extreme energy efficiency. Secondly, we discuss the CIM-based acceleration of variational inference of deep learning models through probabilistic processing while unfolding iterative computations of the method with a compute reuse strategy to significantly minimize the workload. Overall, our co-design methodologies demonstrate the potential of CIM to improve the processing efficiency of uncertainty-aware algorithms by orders of magnitude, thereby enabling edge robotics to access the robustness of sophisticated prediction frameworks within their extremely stringent area/power resources.
Robust Monocular Localization of Drones by Adapting Domain Maps to Depth Prediction Inaccuracies
Oct 27, 2022



We present a novel monocular localization framework by jointly training deep learning-based depth prediction and Bayesian filtering-based pose reasoning. The proposed cross-modal framework significantly outperforms deep learning-only predictions with respect to model scalability and tolerance to environmental variations. Specifically, we show little-to-no degradation of pose accuracy even with extremely poor depth estimates from a lightweight depth predictor. Our framework also maintains high pose accuracy in extreme lighting variations compared to standard deep learning, even without explicit domain adaptation. By openly representing the map and intermediate feature maps (such as depth estimates), our framework also allows for faster updates and reusing intermediate predictions for other tasks, such as obstacle avoidance, resulting in much higher resource efficiency.
MC-CIM: Compute-in-Memory with Monte-Carlo Dropouts for Bayesian Edge Intelligence
Nov 13, 2021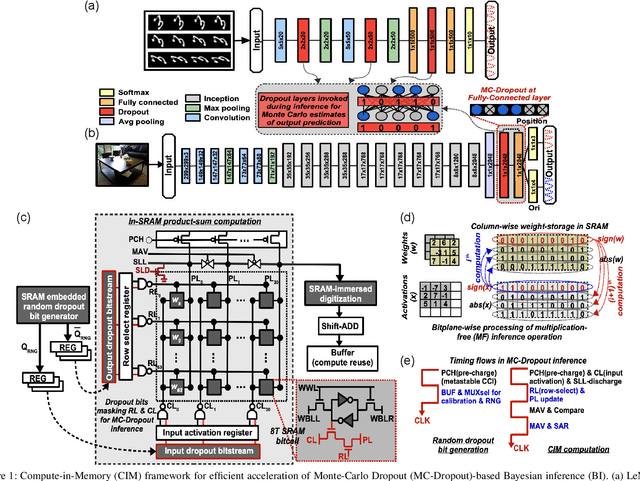
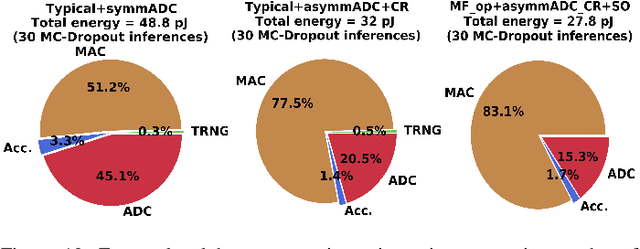
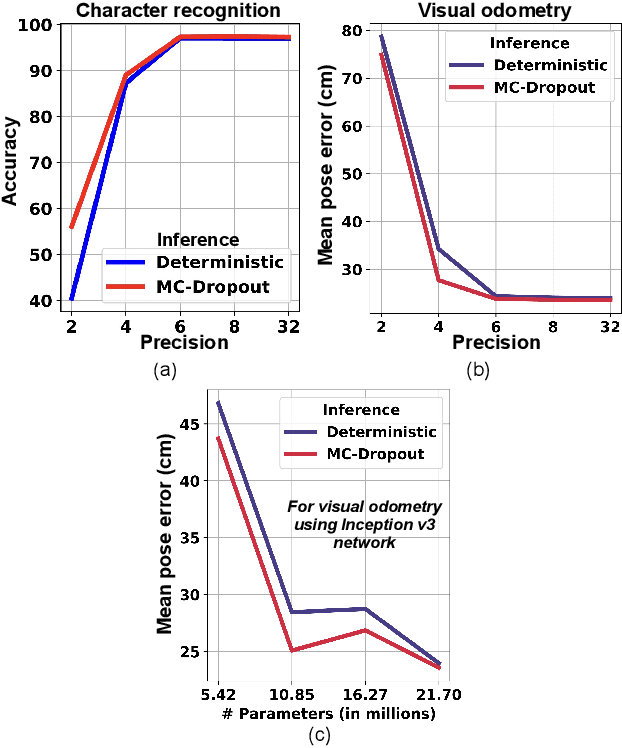
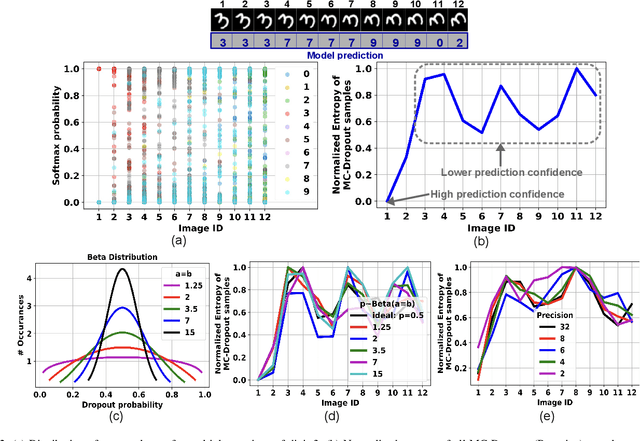
We propose MC-CIM, a compute-in-memory (CIM) framework for robust, yet low power, Bayesian edge intelligence. Deep neural networks (DNN) with deterministic weights cannot express their prediction uncertainties, thereby pose critical risks for applications where the consequences of mispredictions are fatal such as surgical robotics. To address this limitation, Bayesian inference of a DNN has gained attention. Using Bayesian inference, not only the prediction itself, but the prediction confidence can also be extracted for planning risk-aware actions. However, Bayesian inference of a DNN is computationally expensive, ill-suited for real-time and/or edge deployment. An approximation to Bayesian DNN using Monte Carlo Dropout (MC-Dropout) has shown high robustness along with low computational complexity. Enhancing the computational efficiency of the method, we discuss a novel CIM module that can perform in-memory probabilistic dropout in addition to in-memory weight-input scalar product to support the method. We also propose a compute-reuse reformulation of MC-Dropout where each successive instance can utilize the product-sum computations from the previous iteration. Even more, we discuss how the random instances can be optimally ordered to minimize the overall MC-Dropout workload by exploiting combinatorial optimization methods. Application of the proposed CIM-based MC-Dropout execution is discussed for MNIST character recognition and visual odometry (VO) of autonomous drones. The framework reliably gives prediction confidence amidst non-idealities imposed by MC-CIM to a good extent. Proposed MC-CIM with 16x31 SRAM array, 0.85 V supply, 16nm low-standby power (LSTP) technology consumes 27.8 pJ for 30 MC-Dropout instances of probabilistic inference in its most optimal computing and peripheral configuration, saving 43% energy compared to typical execution.
Probabilistic Localization of Insect-Scale Drones on Floating-Gate Inverter Arrays
Feb 16, 2021
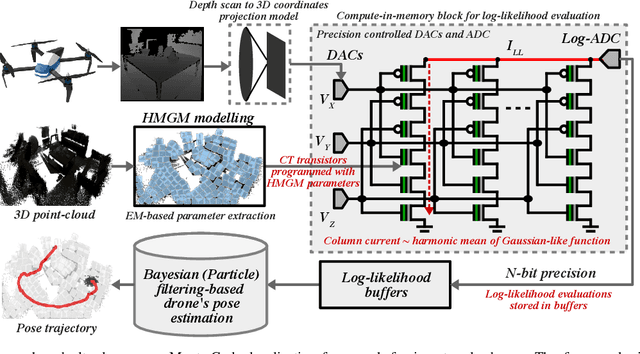
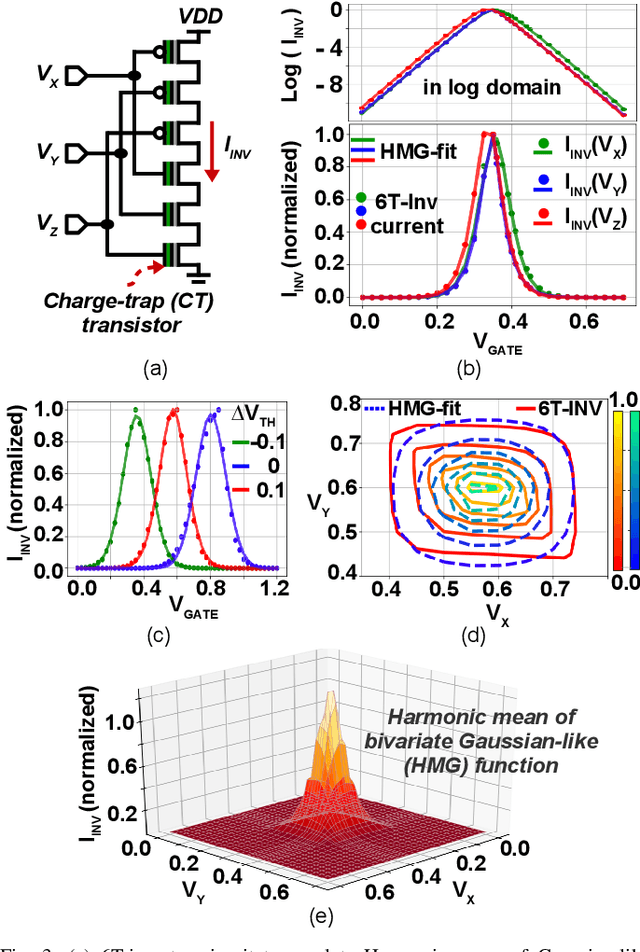
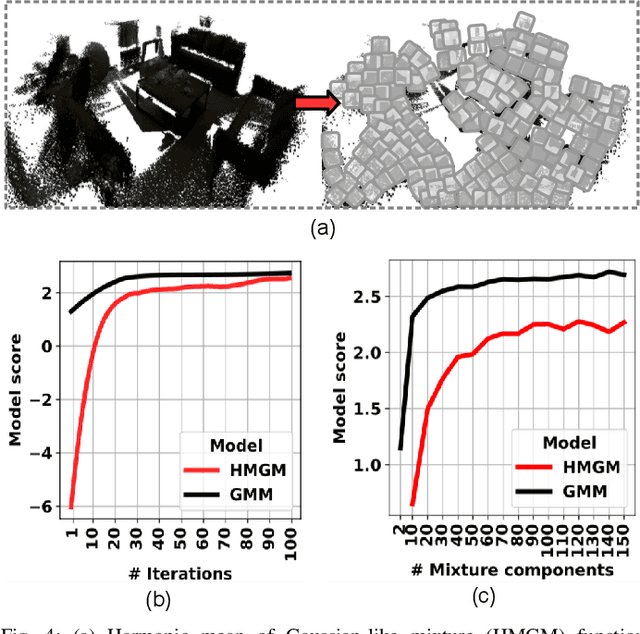
We propose a novel compute-in-memory (CIM)-based ultra-low-power framework for probabilistic localization of insect-scale drones. The conventional probabilistic localization approaches rely on the three-dimensional (3D) Gaussian Mixture Model (GMM)-based representation of a 3D map. A GMM model with hundreds of mixture functions is typically needed to adequately learn and represent the intricacies of the map. Meanwhile, localization using complex GMM map models is computationally intensive. Since insect-scale drones operate under extremely limited area/power budget, continuous localization using GMM models entails much higher operating energy -- thereby, limiting flying duration and/or size of the drone due to a larger battery. Addressing the computational challenges of localization in an insect-scale drone using a CIM approach, we propose a novel framework of 3D map representation using a harmonic mean of "Gaussian-like" mixture (HMGM) model. The likelihood function useful for drone localization can be efficiently implemented by connecting many multi-input inverters in parallel, each programmed with the parameters of the 3D map model represented as HMGM. When the depth measurements are projected to the input of the implementation, the summed current of the inverters emulates the likelihood of the measurement. We have characterized our approach on an RGB-D indoor localization dataset. The average localization error in our approach is $\sim$0.1125 m which is only slightly degraded than software-based evaluation ($\sim$0.08 m). Meanwhile, our localization framework is ultra-low-power, consuming as little as $\sim$17 $\mu$W power while processing a depth frame in 1.33 ms over hundred pose hypotheses in the particle-filtering (PF) algorithm used to localize the drone.
$MC^2RAM$: Markov Chain Monte Carlo Sampling in SRAM for Fast Bayesian Inference
Feb 28, 2020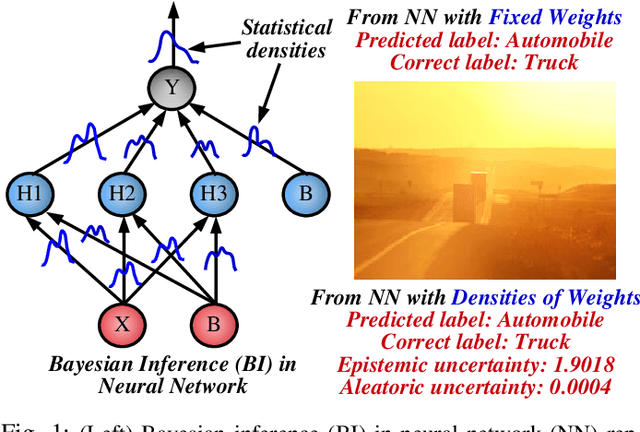
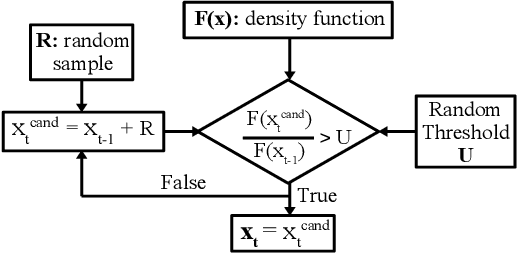
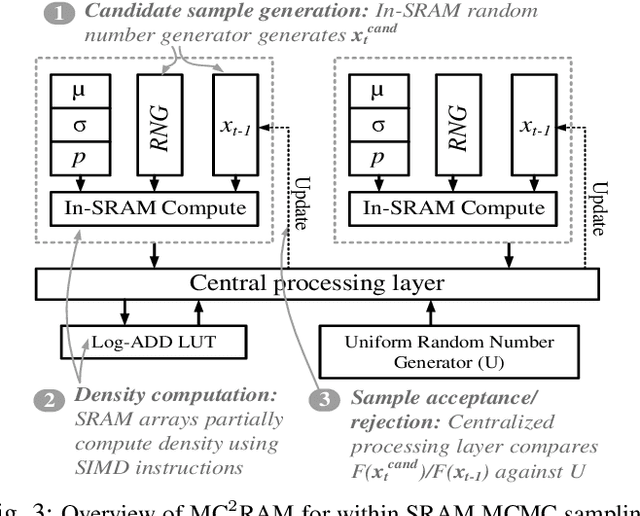
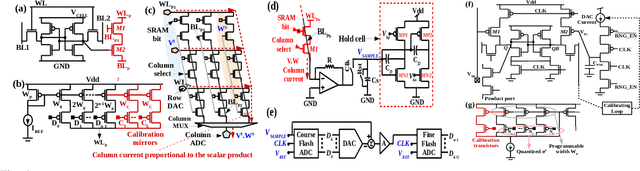
This work discusses the implementation of Markov Chain Monte Carlo (MCMC) sampling from an arbitrary Gaussian mixture model (GMM) within SRAM. We show a novel architecture of SRAM by embedding it with random number generators (RNGs), digital-to-analog converters (DACs), and analog-to-digital converters (ADCs) so that SRAM arrays can be used for high performance Metropolis-Hastings (MH) algorithm-based MCMC sampling. Most of the expensive computations are performed within the SRAM and can be parallelized for high speed sampling. Our iterative compute flow minimizes data movement during sampling. We characterize power-performance trade-off of our design by simulating on 45 nm CMOS technology. For a two-dimensional, two mixture GMM, the implementation consumes ~ 91 micro-Watts power per sampling iteration and produces 500 samples in 2000 clock cycles on an average at 1 GHz clock frequency. Our study highlights interesting insights on how low-level hardware non-idealities can affect high-level sampling characteristics, and recommends ways to optimally operate SRAM within area/power constraints for high performance sampling.