 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-Proto: Language-Aware Episodic Prototypical Training for Multilingual Speaker Verification
Jun 16, 2026Multilingual speaker verification remains challenging because language-dependent acoustic variability causes speaker identity to become entangled with linguistic characteristics, degrading generalization across languages. In multilingual training, embeddings often encode language cues with speaker identity, causing speakers to form language-specific clusters. We propose L-Proto, a language-aware episodic prototypical training strategy that constructs language-consistent episodes. By sampling speakers from a single language per episode, L-Proto reduces language-driven variation during training and encourages embeddings to focus more directly on speaker identity. Experiments on the TidyVoice Challenge benchmark demonstrate consistent performance improvements over conventional fine-tuning and random episodic sampling across multiple backbone architectures.
Toward Complex-Valued Neural Networks for Waveform Generation
Mar 12, 2026Neural vocoders have recently advanced waveform generation, yielding natural and expressive audio. Among these approaches, iSTFT-based vocoders have recently gained attention. They predict a complex-valued spectrogram and then synthesize the waveform via iSTFT, thereby avoiding learned upsampling stages that can increase computational cost. However, current approaches use real-valued networks that process the real and imaginary parts independently. This separation limits their ability to capture the inherent structure of complex spectrograms. We present ComVo, a Complex-valued neural Vocoder whose generator and discriminator use native complex arithmetic. This enables an adversarial training framework that provides structured feedback in complex-valued representations. To guide phase transformations in a structured manner, we introduce phase quantization, which discretizes phase values and regularizes the training process. Finally, we propose a block-matrix computation scheme to improve training efficiency by reducing redundant operations. Experiments demonstrate that ComVo achieves higher synthesis quality than comparable real-valued baselines, and that its block-matrix scheme reduces training time by 25%. Audio samples and code are available at https://hs-oh-prml.github.io/ComVo/.
VibE-SVC: Vibrato Extraction with High-frequency F0 Contour for Singing Voice Conversion
May 27, 2025Controlling singing style is crucial for achieving an expressive and natural singing voice. Among the various style factors, vibrato plays a key role in conveying emotions and enhancing musical depth. However, modeling vibrato remains challenging due to its dynamic nature, making it difficult to control in singing voice conversion. To address this, we propose VibESVC, a controllable singing voice conversion model that explicitly extracts and manipulates vibrato using discrete wavelet transform. Unlike previous methods that model vibrato implicitly, our approach decomposes the F0 contour into frequency components, enabling precise transfer. This allows vibrato control for enhanced flexibility. Experimental results show that VibE-SVC effectively transforms singing styles while preserving speaker similarity. Both subjective and objective evaluations confirm high-quality conversion.
EmoSphere-SER: Enhancing Speech Emotion Recognition Through Spherical Representation with Auxiliary Classification
May 26, 2025Speech emotion recognition predicts a speaker's emotional state from speech signals using discrete labels or continuous dimensions such as arousal, valence, and dominance (VAD). We propose EmoSphere-SER, a joint model that integrates spherical VAD region classification to guide VAD regression for improved emotion prediction. In our framework, VAD values are transformed into spherical coordinates that are divided into multiple spherical regions, and an auxiliary classification task predicts which spherical region each point belongs to, guiding the regression process. Additionally, we incorporate a dynamic weighting scheme and a style pooling layer with multi-head self-attention to capture spectral and temporal dynamics, further boosting performance. This combined training strategy reinforces structured learning and improves prediction consistency. Experimental results show that our approach exceeds baseline methods, confirming the validity of the proposed framework.
DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speech
May 26, 2025Cross-speaker emotion transfer in speech synthesis relies on extracting speaker-independent emotion embeddings for accurate emotion modeling without retaining speaker traits. However, existing timbre compression methods fail to fully separate speaker and emotion characteristics, causing speaker leakage and degraded synthesis quality. To address this, we propose DiEmo-TTS, a self-supervised distillation method to minimize emotional information loss and preserve speaker identity. We introduce cluster-driven sampling and information perturbation to preserve emotion while removing irrelevant factors. To facilitate this process, we propose an emotion clustering and matching approach using emotional attribute prediction and speaker embeddings, enabling generalization to unlabeled data. Additionally, we designed a dual conditioning transformer to integrate style features better. Experimental results confirm the effectiveness of our method in learning speaker-irrelevant emotion embeddings.
JELLY: Joint Emotion Recognition and Context Reasoning with LLMs for Conversational Speech Synthesis
Jan 09, 2025Recently, there has been a growing demand for conversational speech synthesis (CSS) that generates more natural speech by considering the conversational context. To address this, we introduce JELLY, a novel CSS framework that integrates emotion recognition and context reasoning for generating appropriate speech in conversation by fine-tuning a large language model (LLM) with multiple partial LoRA modules. We propose an Emotion-aware Q-former encoder, which enables the LLM to perceive emotions in speech. The encoder is trained to align speech emotions with text, utilizing datasets of emotional speech. The entire model is then fine-tuned with conversational speech data to infer emotional context for generating emotionally appropriate speech in conversation. Our experimental results demonstrate that JELLY excels in emotional context modeling, synthesizing speech that naturally aligns with conversation, while mitigating the scarcity of emotional conversational speech datasets.
EmoSphere++: Emotion-Controllable Zero-Shot Text-to-Speech via Emotion-Adaptive Spherical Vector
Nov 04, 2024



Emotional text-to-speech (TTS) technology has achieved significant progress in recent years; however, challenges remain owing to the inherent complexity of emotions and limitations of the available emotional speech datasets and models. Previous studies typically relied on limited emotional speech datasets or required extensive manual annotations, restricting their ability to generalize across different speakers and emotional styles. In this paper, we present EmoSphere++, an emotion-controllable zero-shot TTS model that can control emotional style and intensity to resemble natural human speech. We introduce a novel emotion-adaptive spherical vector that models emotional style and intensity without human annotation. Moreover, we propose a multi-level style encoder that can ensure effective generalization for both seen and unseen speakers. We also introduce additional loss functions to enhance the emotion transfer performance for zero-shot scenarios. We employ a conditional flow matching-based decoder to achieve high-quality and expressive emotional TTS in a few sampling steps. Experimental results demonstrate the effectiveness of the proposed framework.
EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
Jun 12, 2024Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
DiffProsody: Diffusion-based Latent Prosody Generation for Expressive Speech Synthesis with Prosody Conditional Adversarial Training
Jul 31, 2023



Expressive text-to-speech systems have undergone significant advancements owing to prosody modeling, but conventional methods can still be improved. Traditional approaches have relied on the autoregressive method to predict the quantized prosody vector; however, it suffers from the issues of long-term dependency and slow inference. This study proposes a novel approach called DiffProsody in which expressive speech is synthesized using a diffusion-based latent prosody generator and prosody conditional adversarial training. Our findings confirm the effectiveness of our prosody generator in generating a prosody vector. Furthermore, our prosody conditional discriminator significantly improves the quality of the generated speech by accurately emulating prosody. We use denoising diffusion generative adversarial networks to improve the prosody generation speed. Consequently, DiffProsody is capable of generating prosody 16 times faster than the conventional diffusion model. The superior performance of our proposed method has been demonstrated via experiments.
HierVST: Hierarchical Adaptive Zero-shot Voice Style Transfer
Jul 30, 2023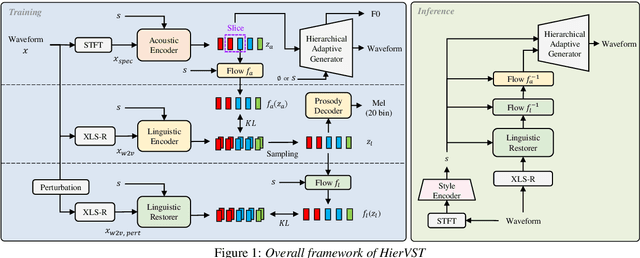
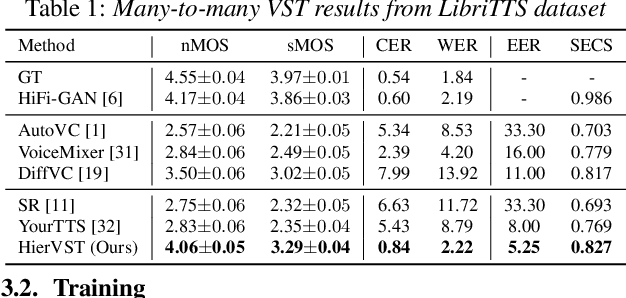
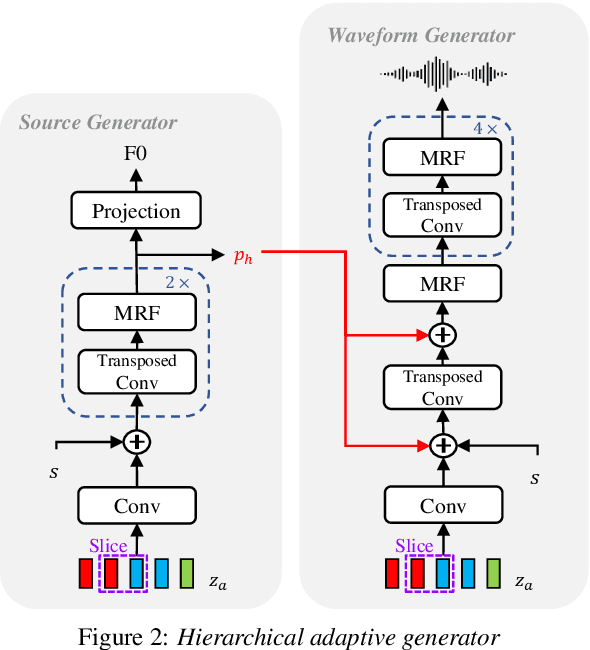
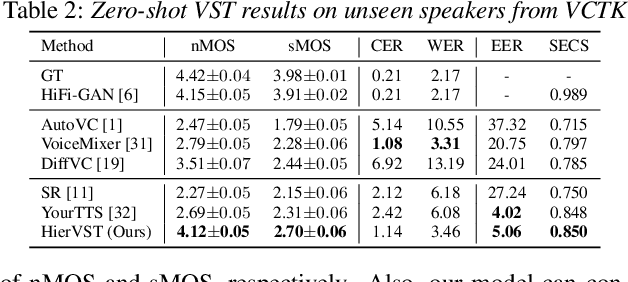
Despite rapid progress in the voice style transfer (VST) field, recent zero-shot VST systems still lack the ability to transfer the voice style of a novel speaker. In this paper, we present HierVST, a hierarchical adaptive end-to-end zero-shot VST model. Without any text transcripts, we only use the speech dataset to train the model by utilizing hierarchical variational inference and self-supervised representation. In addition, we adopt a hierarchical adaptive generator that generates the pitch representation and waveform audio sequentially. Moreover, we utilize unconditional generation to improve the speaker-relative acoustic capacity in the acoustic representation. With a hierarchical adaptive structure, the model can adapt to a novel voice style and convert speech progressively. The experimental results demonstrate that our method outperforms other VST models in zero-shot VST scenarios. Audio samples are available at \url{https://hiervst.github.io/}.