 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitmus (Re)Agent: A Benchmark and Agentic System for Predictive Evaluation of Multilingual Models
Apr 10, 2026We study predictive multilingual evaluation: estimating how well a model will perform on a task in a target language when direct benchmark results are missing. This problem is common in multilingual deployment, where evaluation coverage is sparse and published evidence is uneven across languages, tasks, and model families. We introduce a controlled benchmark of 1,500 questions spanning six tasks and five evidence scenarios. The benchmark separates accessible evidence from ground truth, enabling evaluation of systems that must infer missing results from incomplete literature evidence. We also present Litmus (Re)Agent, a DAG-orchestrated agentic system that decomposes queries into hypotheses, retrieves evidence, and synthesises predictions through feature-aware aggregation. Across six systems, Litmus (Re)Agent achieves the best overall performance, with the largest gains in transfer-heavy scenarios where direct evidence is weak or absent. These results show that structured agentic reasoning is a promising approach to multilingual performance estimation under incomplete evidence.
$\texttt{SAGE}$: A Generic Framework for LLM Safety Evaluation
Apr 28, 2025



Safety evaluation of Large Language Models (LLMs) has made progress and attracted academic interest, but it remains challenging to keep pace with the rapid integration of LLMs across diverse applications. Different applications expose users to various harms, necessitating application-specific safety evaluations with tailored harms and policies. Another major gap is the lack of focus on the dynamic and conversational nature of LLM systems. Such potential oversights can lead to harms that go unnoticed in standard safety benchmarks. This paper identifies the above as key requirements for robust LLM safety evaluation and recognizing that current evaluation methodologies do not satisfy these, we introduce the $\texttt{SAGE}$ (Safety AI Generic Evaluation) framework. $\texttt{SAGE}$ is an automated modular framework designed for customized and dynamic harm evaluations. It utilizes adversarial user models that are system-aware and have unique personalities, enabling a holistic red-teaming evaluation. We demonstrate $\texttt{SAGE}$'s effectiveness by evaluating seven state-of-the-art LLMs across three applications and harm policies. Our experiments with multi-turn conversational evaluations revealed a concerning finding that harm steadily increases with conversation length. Furthermore, we observe significant disparities in model behavior when exposed to different user personalities and scenarios. Our findings also reveal that some models minimize harmful outputs by employing severe refusal tactics that can hinder their usefulness. These insights highlight the necessity of adaptive and context-specific testing to ensure better safety alignment and safer deployment of LLMs in real-world scenarios.
LLM Safety for Children
Feb 18, 2025



This paper analyzes the safety of Large Language Models (LLMs) in interactions with children below age of 18 years. Despite the transformative applications of LLMs in various aspects of children's lives such as education and therapy, there remains a significant gap in understanding and mitigating potential content harms specific to this demographic. The study acknowledges the diverse nature of children often overlooked by standard safety evaluations and proposes a comprehensive approach to evaluating LLM safety specifically for children. We list down potential risks that children may encounter when using LLM powered applications. Additionally we develop Child User Models that reflect the varied personalities and interests of children informed by literature in child care and psychology. These user models aim to bridge the existing gap in child safety literature across various fields. We utilize Child User Models to evaluate the safety of six state of the art LLMs. Our observations reveal significant safety gaps in LLMs particularly in categories harmful to children but not adults
Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation
Dec 18, 2024



With the growth of social media and large language models, content moderation has become crucial. Many existing datasets lack adequate representation of different groups, resulting in unreliable assessments. To tackle this, we propose a socio-culturally aware evaluation framework for LLM-driven content moderation and introduce a scalable method for creating diverse datasets using persona-based generation. Our analysis reveals that these datasets provide broader perspectives and pose greater challenges for LLMs than diversity-focused generation methods without personas. This challenge is especially pronounced in smaller LLMs, emphasizing the difficulties they encounter in moderating such diverse content.
DiTTO: A Feature Representation Imitation Approach for Improving Cross-Lingual Transfer
Mar 04, 2023Zero-shot cross-lingual transfer is promising, however has been shown to be sub-optimal, with inferior transfer performance across low-resource languages. In this work, we envision languages as domains for improving zero-shot transfer by jointly reducing the feature incongruity between the source and the target language and increasing the generalization capabilities of pre-trained multilingual transformers. We show that our approach, DiTTO, significantly outperforms the standard zero-shot fine-tuning method on multiple datasets across all languages using solely unlabeled instances in the target language. Empirical results show that jointly reducing feature incongruity for multiple target languages is vital for successful cross-lingual transfer. Moreover, our model enables better cross-lingual transfer than standard fine-tuning methods, even in the few-shot setting.
Too Brittle To Touch: Comparing the Stability of Quantization and Distillation Towards Developing Lightweight Low-Resource MT Models
Nov 09, 2022



Leveraging shared learning through Massively Multilingual Models, state-of-the-art machine translation models are often able to adapt to the paucity of data for low-resource languages. However, this performance comes at the cost of significantly bloated models which are not practically deployable. Knowledge Distillation is one popular technique to develop competitive, lightweight models: In this work, we first evaluate its use to compress MT models focusing on languages with extremely limited training data. Through our analysis across 8 languages, we find that the variance in the performance of the distilled models due to their dependence on priors including the amount of synthetic data used for distillation, the student architecture, training hyperparameters and confidence of the teacher models, makes distillation a brittle compression mechanism. To mitigate this, we explore the use of post-training quantization for the compression of these models. Here, we find that while distillation provides gains across some low-resource languages, quantization provides more consistent performance trends for the entire range of languages, especially the lowest-resource languages in our target set.
"Diversity and Uncertainty in Moderation" are the Key to Data Selection for Multilingual Few-shot Transfer
Jun 30, 2022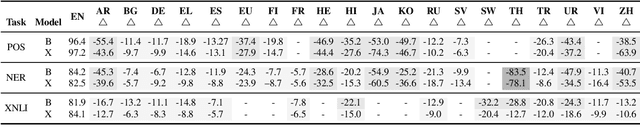

Few-shot transfer often shows substantial gain over zero-shot transfer~\cite{lauscher2020zero}, which is a practically useful trade-off between fully supervised and unsupervised learning approaches for multilingual pretrained model-based systems. This paper explores various strategies for selecting data for annotation that can result in a better few-shot transfer. The proposed approaches rely on multiple measures such as data entropy using $n$-gram language model, predictive entropy, and gradient embedding. We propose a loss embedding method for sequence labeling tasks, which induces diversity and uncertainty sampling similar to gradient embedding. The proposed data selection strategies are evaluated and compared for POS tagging, NER, and NLI tasks for up to 20 languages. Our experiments show that the gradient and loss embedding-based strategies consistently outperform random data selection baselines, with gains varying with the initial performance of the zero-shot transfer. Furthermore, the proposed method shows similar trends in improvement even when the model is fine-tuned using a lower proportion of the original task-specific labeled training data for zero-shot transfer.
Beyond Static Models and Test Sets: Benchmarking the Potential of Pre-trained Models Across Tasks and Languages
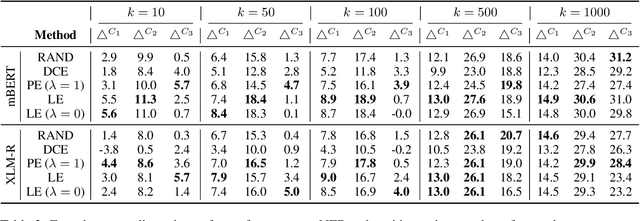
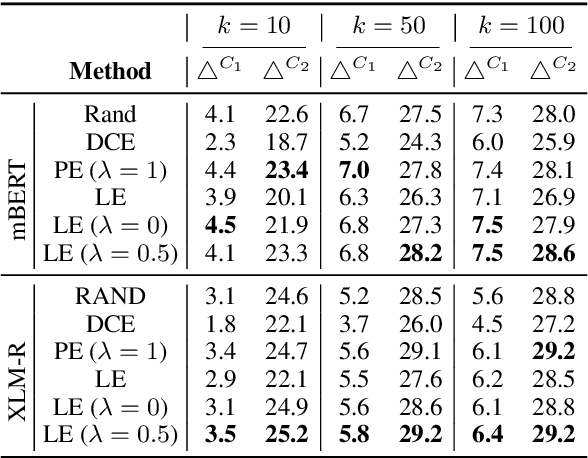
May 12, 2022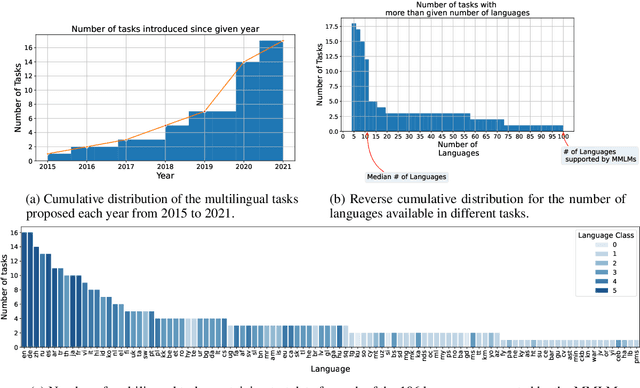


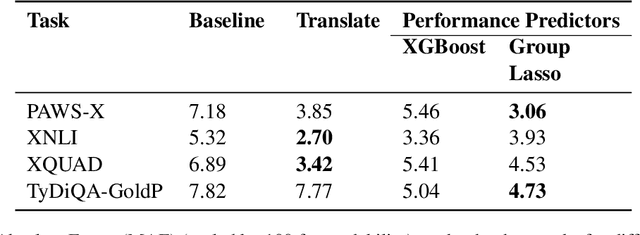
Although recent Massively Multilingual Language Models (MMLMs) like mBERT and XLMR support around 100 languages, most existing multilingual NLP benchmarks provide evaluation data in only a handful of these languages with little linguistic diversity. We argue that this makes the existing practices in multilingual evaluation unreliable and does not provide a full picture of the performance of MMLMs across the linguistic landscape. We propose that the recent work done in Performance Prediction for NLP tasks can serve as a potential solution in fixing benchmarking in Multilingual NLP by utilizing features related to data and language typology to estimate the performance of an MMLM on different languages. We compare performance prediction with translating test data with a case study on four different multilingual datasets, and observe that these methods can provide reliable estimates of the performance that are often on-par with the translation based approaches, without the need for any additional translation as well as evaluation costs.
On the Economics of Multilingual Few-shot Learning: Modeling the Cost-Performance Trade-offs of Machine Translated and Manual Data
May 12, 2022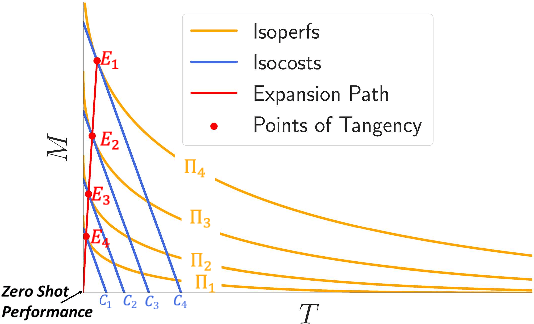

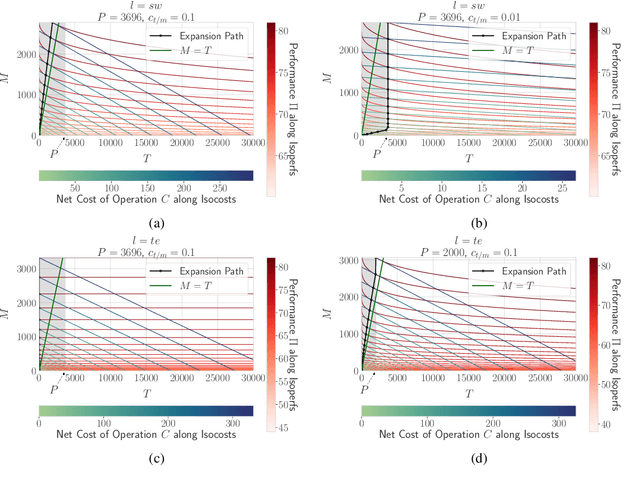
Borrowing ideas from {\em Production functions} in micro-economics, in this paper we introduce a framework to systematically evaluate the performance and cost trade-offs between machine-translated and manually-created labelled data for task-specific fine-tuning of massively multilingual language models. We illustrate the effectiveness of our framework through a case-study on the TyDIQA-GoldP dataset. One of the interesting conclusions of the study is that if the cost of machine translation is greater than zero, the optimal performance at least cost is always achieved with at least some or only manually-created data. To our knowledge, this is the first attempt towards extending the concept of production functions to study data collection strategies for training multilingual models, and can serve as a valuable tool for other similar cost vs data trade-offs in NLP.
Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models
May 12, 2022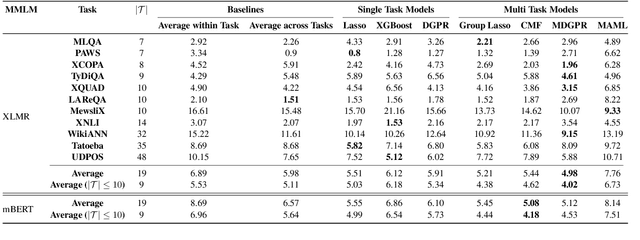
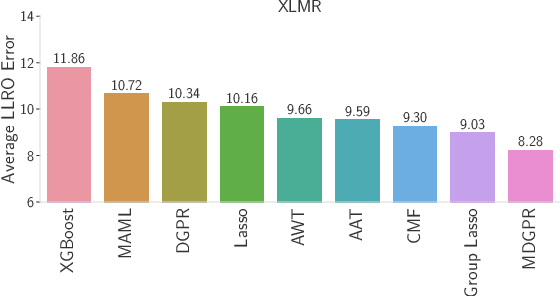
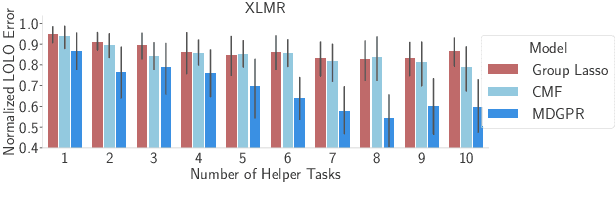
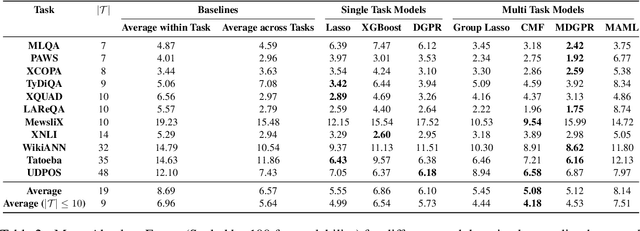
Massively Multilingual Transformer based Language Models have been observed to be surprisingly effective on zero-shot transfer across languages, though the performance varies from language to language depending on the pivot language(s) used for fine-tuning. In this work, we build upon some of the existing techniques for predicting the zero-shot performance on a task, by modeling it as a multi-task learning problem. We jointly train predictive models for different tasks which helps us build more accurate predictors for tasks where we have test data in very few languages to measure the actual performance of the model. Our approach also lends us the ability to perform a much more robust feature selection and identify a common set of features that influence zero-shot performance across a variety of tasks.