 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPRA: Video Prediction for Robot Actions
Nov 11, 2025



Can we turn a video prediction model into a robot policy? Videos, including those of humans or teleoperated robots, capture rich physical interactions. However, most of them lack labeled actions, which limits their use in robot learning. We present Video Prediction for Robot Actions (ViPRA), a simple pretraining-finetuning framework that learns continuous robot control from these actionless videos. Instead of directly predicting actions, we train a video-language model to predict both future visual observations and motion-centric latent actions, which serve as intermediate representations of scene dynamics. We train these latent actions using perceptual losses and optical flow consistency to ensure they reflect physically grounded behavior. For downstream control, we introduce a chunked flow matching decoder that maps latent actions to robot-specific continuous action sequences, using only 100 to 200 teleoperated demonstrations. This approach avoids expensive action annotation, supports generalization across embodiments, and enables smooth, high-frequency continuous control upto 22 Hz via chunked action decoding. Unlike prior latent action works that treat pretraining as autoregressive policy learning, explicitly models both what changes and how. Our method outperforms strong baselines, with a 16% gain on the SIMPLER benchmark and a 13% improvement across real world manipulation tasks. We will release models and code at https://vipra-project.github.io
CS-NET at SemEval-2020 Task 4: Siamese BERT for ComVE
Jul 21, 2020

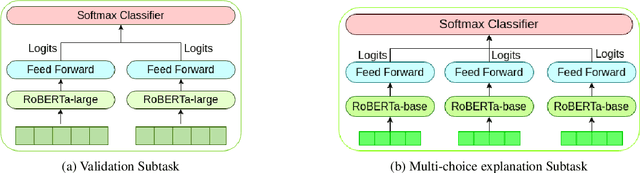

In this paper, we describe our system for Task 4 of SemEval 2020, which involves differentiating between natural language statements that confirm to common sense and those that do not. The organizers propose three subtasks - first, selecting between two sentences, the one which is against common sense. Second, identifying the most crucial reason why a statement does not make sense. Third, generating novel reasons for explaining the against common sense statement. Out of the three subtasks, this paper reports the system description of subtask A and subtask B. This paper proposes a model based on transformer neural network architecture for addressing the subtasks. The novelty in work lies in the architecture design, which handles the logical implication of contradicting statements and simultaneous information extraction from both sentences. We use a parallel instance of transformers, which is responsible for a boost in the performance. We achieved an accuracy of 94.8% in subtask A and 89% in subtask B on the test set.