 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-CrossRE A Multi-Lingual Multi-Domain Dataset for Relation Extraction
May 18, 2023



Most research in Relation Extraction (RE) involves the English language, mainly due to the lack of multi-lingual resources. We propose Multi-CrossRE, the broadest multi-lingual dataset for RE, including 26 languages in addition to English, and covering six text domains. Multi-CrossRE is a machine translated version of CrossRE (Bassignana and Plank, 2022), with a sub-portion including more than 200 sentences in seven diverse languages checked by native speakers. We run a baseline model over the 26 new datasets and--as sanity check--over the 26 back-translations to English. Results on the back-translated data are consistent with the ones on the original English CrossRE, indicating high quality of the translation and the resulting dataset.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Explaining Classes through Word Attribution
Aug 31, 2021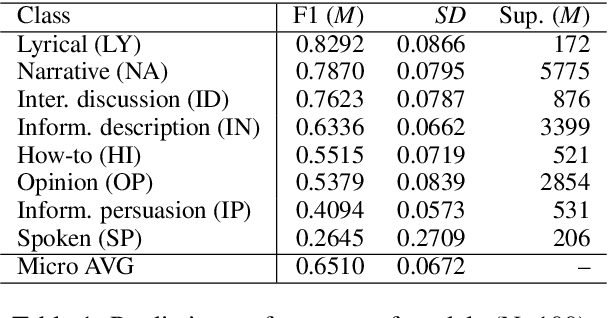
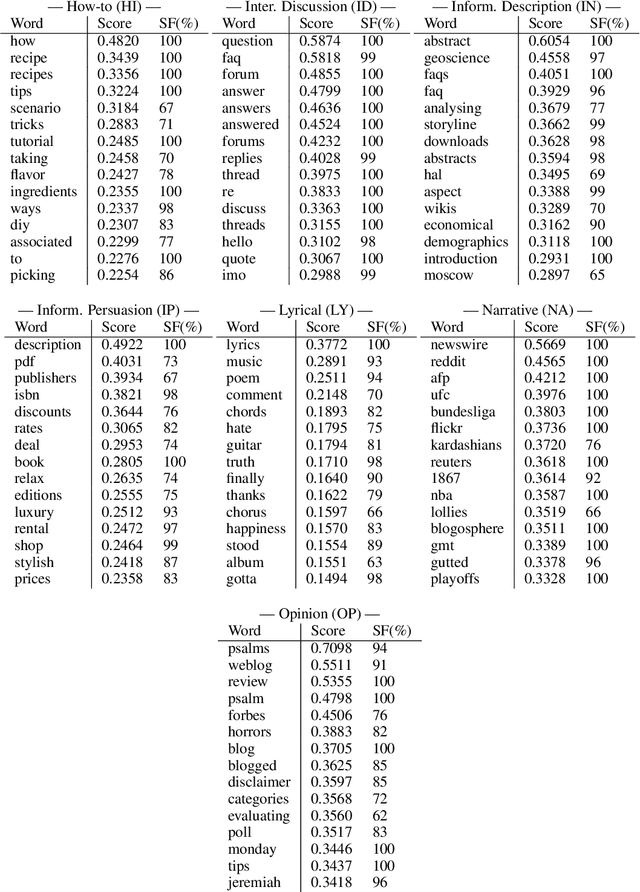
In recent years, several methods have been proposed for explaining individual predictions of deep learning models, yet there has been little study of how to aggregate these predictions to explain how such models view classes as a whole in text classification tasks. In this work, we propose a method for explaining classes using deep learning models and the Integrated Gradients feature attribution technique by aggregating explanations of individual examples in text classification to general descriptions of the classes. We demonstrate the approach on Web register (genre) classification using the XML-R model and the Corpus of Online Registers of English (CORE), finding that the method identifies plausible and discriminative keywords characterizing all but the smallest class.
Quantitative Evaluation of Alternative Translations in a Corpus of Highly Dissimilar Finnish Paraphrases
May 06, 2021
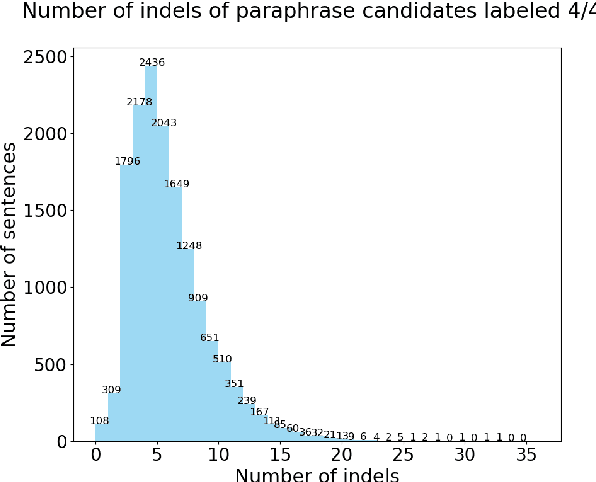
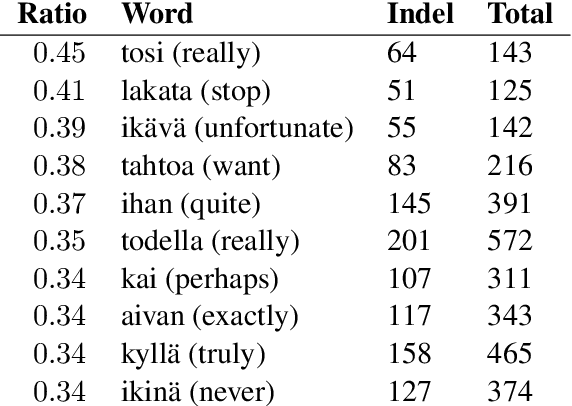

In this paper, we present a quantitative evaluation of differences between alternative translations in a large recently released Finnish paraphrase corpus focusing in particular on non-trivial variation in translation. We combine a series of automatic steps detecting systematic variation with manual analysis to reveal regularities and identify categories of translation differences. We find the paraphrase corpus to contain highly non-trivial translation variants difficult to recognize through automatic approaches.
Deep learning for sentence clustering in essay grading support
Apr 23, 2021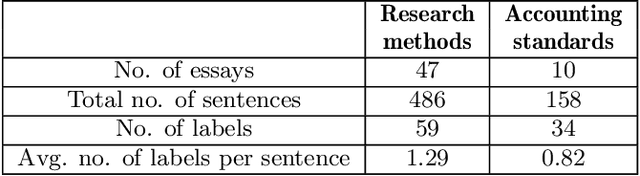
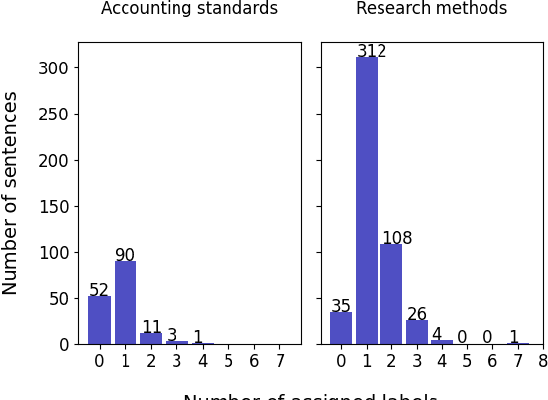

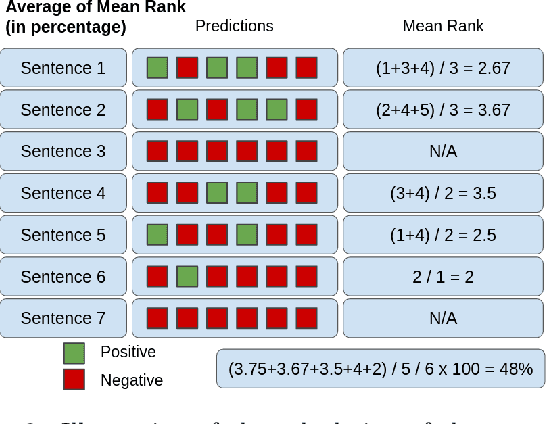
Essays as a form of assessment test student knowledge on a deeper level than short answer and multiple-choice questions. However, the manual evaluation of essays is time- and labor-consuming. Automatic clustering of essays, or their fragments, prior to manual evaluation presents a possible solution to reducing the effort required in the evaluation process. Such clustering presents numerous challenges due to the variability and ambiguity of natural language. In this paper, we introduce two datasets of undergraduate student essays in Finnish, manually annotated for salient arguments on the sentence level. Using these datasets, we evaluate several deep-learning embedding methods for their suitability to sentence clustering in support of essay grading. We find that the choice of the most suitable method depends on the nature of the exam question and the answers, with deep-learning methods being capable of, but not guaranteeing better performance over simpler methods based on lexical overlap.
Beyond the English Web: Zero-Shot Cross-Lingual and Lightweight Monolingual Classification of Registers
Feb 15, 2021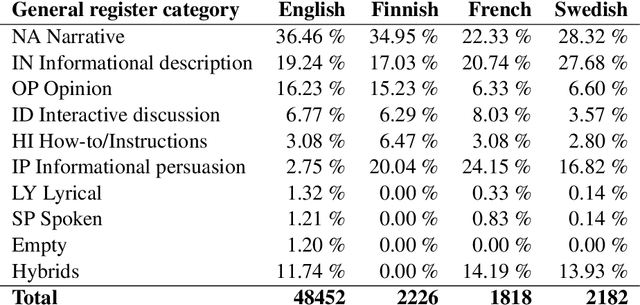
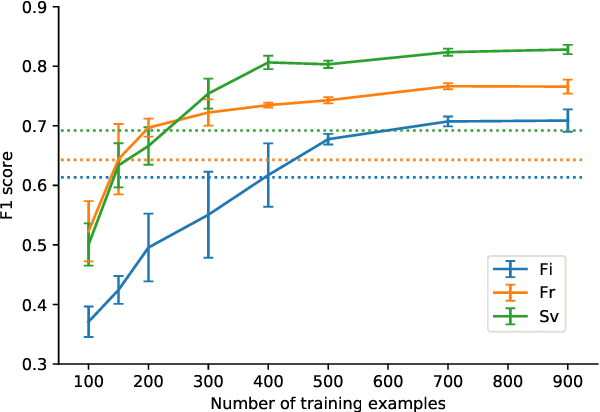
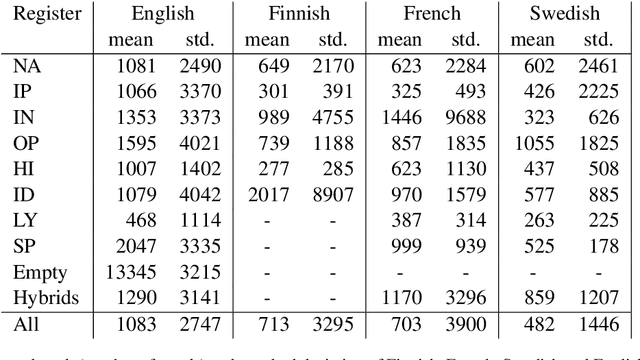
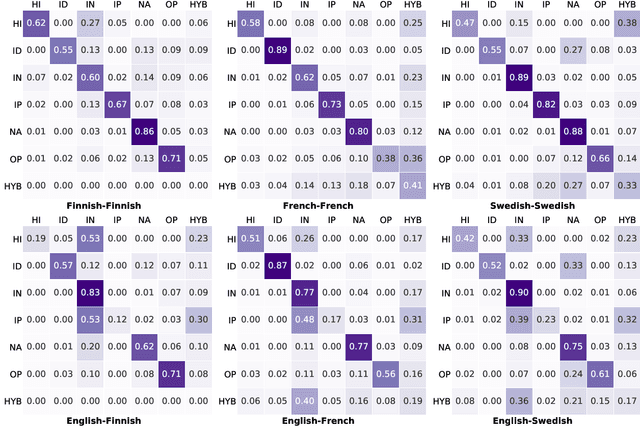
We explore cross-lingual transfer of register classification for web documents. Registers, that is, text varieties such as blogs or news are one of the primary predictors of linguistic variation and thus affect the automatic processing of language. We introduce two new register annotated corpora, FreCORE and SweCORE, for French and Swedish. We demonstrate that deep pre-trained language models perform strongly in these languages and outperform previous state-of-the-art in English and Finnish. Specifically, we show 1) that zero-shot cross-lingual transfer from the large English CORE corpus can match or surpass previously published monolingual models, and 2) that lightweight monolingual classification requiring very little training data can reach or surpass our zero-shot performance. We further analyse classification results finding that certain registers continue to pose challenges in particular for cross-lingual transfer.
Towards Fully Bilingual Deep Language Modeling
Oct 22, 2020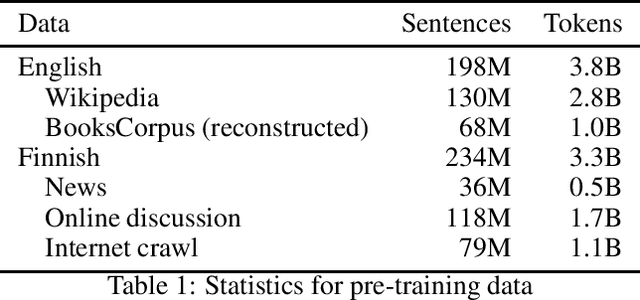


Language models based on deep neural networks have facilitated great advances in natural language processing and understanding tasks in recent years. While models covering a large number of languages have been introduced, their multilinguality has come at a cost in terms of monolingual performance, and the best-performing models at most tasks not involving cross-lingual transfer remain monolingual. In this paper, we consider the question of whether it is possible to pre-train a bilingual model for two remotely related languages without compromising performance at either language. We collect pre-training data, create a Finnish-English bilingual BERT model and evaluate its performance on datasets used to evaluate the corresponding monolingual models. Our bilingual model performs on par with Google's original English BERT on GLUE and nearly matches the performance of monolingual Finnish BERT on a range of Finnish NLP tasks, clearly outperforming multilingual BERT. We find that when the model vocabulary size is increased, the BERT-Base architecture has sufficient capacity to learn two remotely related languages to a level where it achieves comparable performance with monolingual models, demonstrating the feasibility of training fully bilingual deep language models. The model and all tools involved in its creation are freely available at https://github.com/TurkuNLP/biBERT
The birth of Romanian BERT
Sep 18, 2020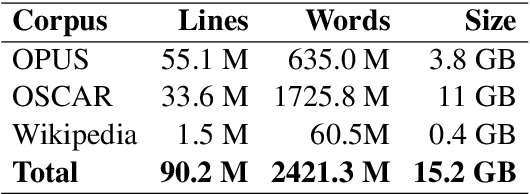
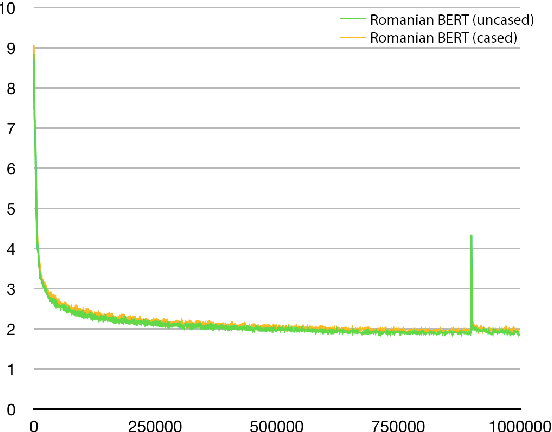

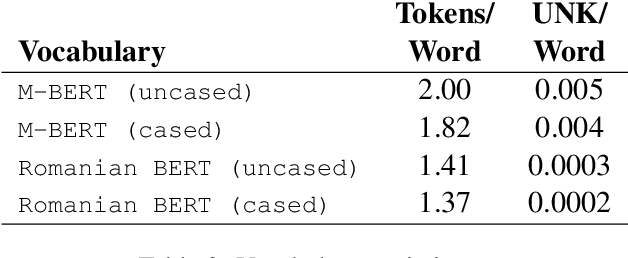
Large-scale pretrained language models have become ubiquitous in Natural Language Processing. However, most of these models are available either in high-resource languages, in particular English, or as multilingual models that compromise performance on individual languages for coverage. This paper introduces Romanian BERT, the first purely Romanian transformer-based language model, pretrained on a large text corpus. We discuss corpus composition and cleaning, the model training process, as well as an extensive evaluation of the model on various Romanian datasets. We open source not only the model itself, but also a repository that contains information on how to obtain the corpus, fine-tune and use this model in production (with practical examples), and how to fully replicate the evaluation process.
Exploring Cross-sentence Contexts for Named Entity Recognition with BERT
Jun 02, 2020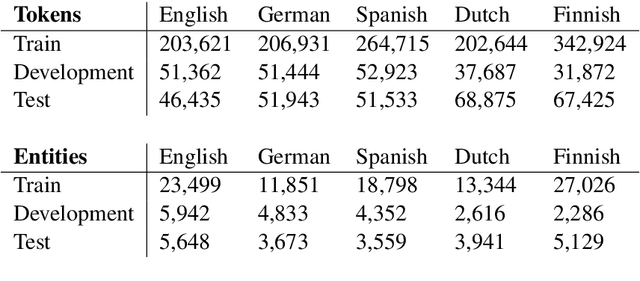
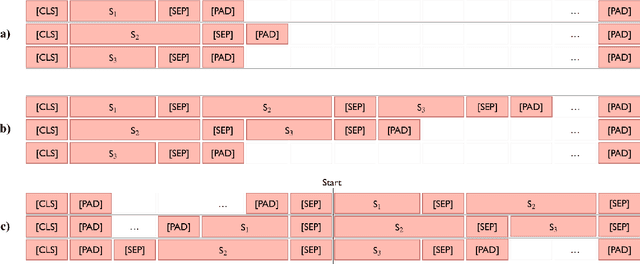
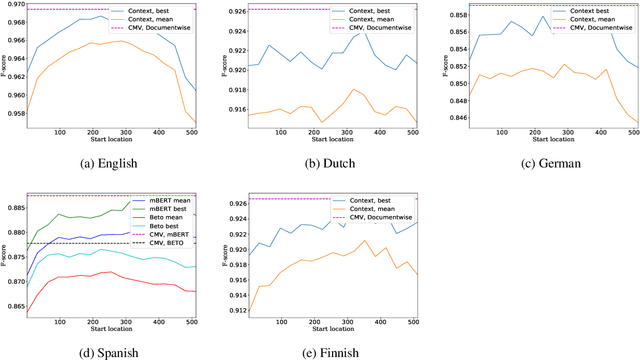
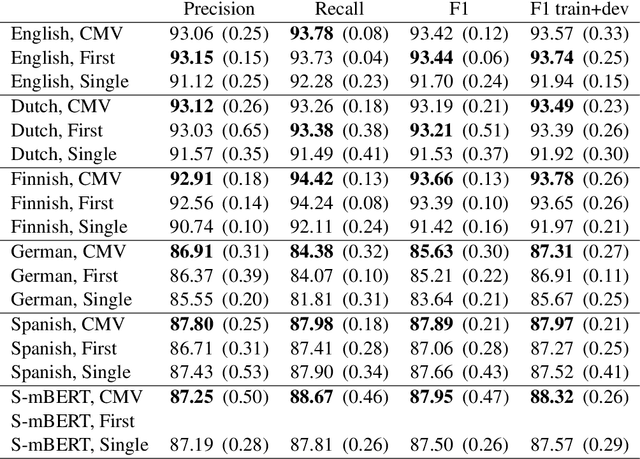
Named entity recognition (NER) is frequently addressed as a sequence classification task where each input consists of one sentence of text. It is nevertheless clear that useful information for the task can often be found outside of the scope of a single-sentence context. Recently proposed self-attention models such as BERT can both efficiently capture long-distance relationships in input as well as represent inputs consisting of several sentences, creating new opportunitites for approaches that incorporate cross-sentence information in natural language processing tasks. In this paper, we present a systematic study exploring the use of cross-sentence information for NER using BERT models in five languages. We find that adding context in the form of additional sentences to BERT input systematically increases NER performance on all of the tested languages and models. Including multiple sentences in each input also allows us to study the predictions of the same sentences in different contexts. We propose a straightforward method, Contextual Majority Voting (CMV), to combine different predictions for sentences and demonstrate this to further increase NER performance with BERT. Our approach does not require any changes to the underlying BERT architecture, rather relying on restructuring examples for training and prediction. Evaluation on established datasets, including the CoNLL'02 and CoNLL'03 NER benchmarks, demonstrates that our proposed approach can improve on the state-of-the-art NER results on English, Dutch, and Finnish, achieves the best reported BERT-based results on German, and is on par with performance reported with other BERT-based approaches in Spanish. We release all methods implemented in this work under open licenses.
WikiBERT models: deep transfer learning for many languages
Jun 02, 2020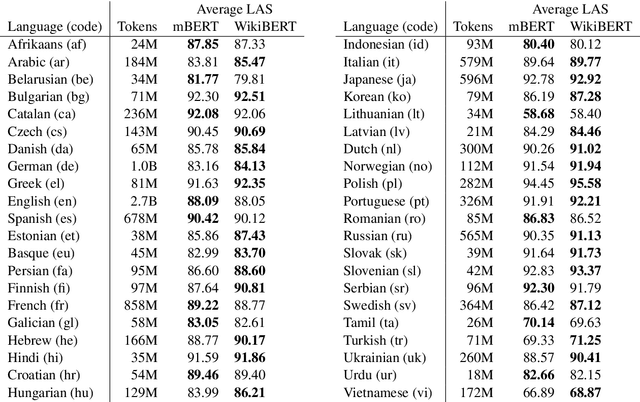
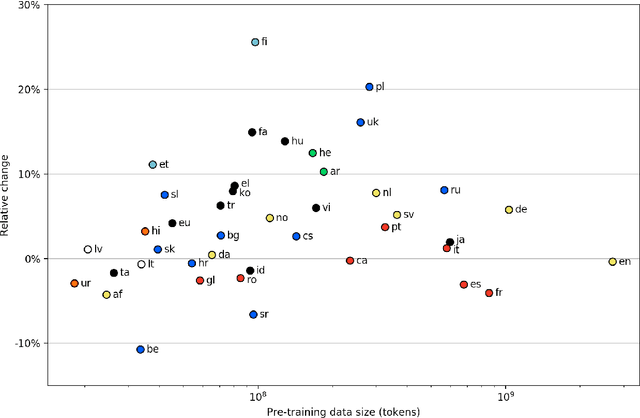
Deep neural language models such as BERT have enabled substantial recent advances in many natural language processing tasks. Due to the effort and computational cost involved in their pre-training, language-specific models are typically introduced only for a small number of high-resource languages such as English. While multilingual models covering large numbers of languages are available, recent work suggests monolingual training can produce better models, and our understanding of the tradeoffs between mono- and multilingual training is incomplete. In this paper, we introduce a simple, fully automated pipeline for creating language-specific BERT models from Wikipedia data and introduce 42 new such models, most for languages up to now lacking dedicated deep neural language models. We assess the merits of these models using the state-of-the-art UDify parser on Universal Dependencies data, contrasting performance with results using the multilingual BERT model. We find that UDify using WikiBERT models outperforms the parser using mBERT on average, with the language-specific models showing substantially improved performance for some languages, yet limited improvement or a decrease in performance for others. We also present preliminary results as first steps toward an understanding of the conditions under which language-specific models are most beneficial. All of the methods and models introduced in this work are available under open licenses from https://github.com/turkunlp/wikibert.