 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Classes through Word Attribution
Aug 31, 2021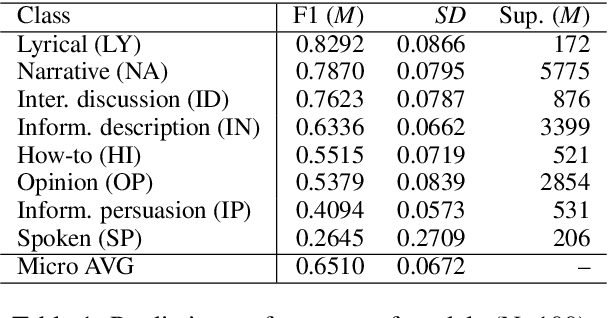
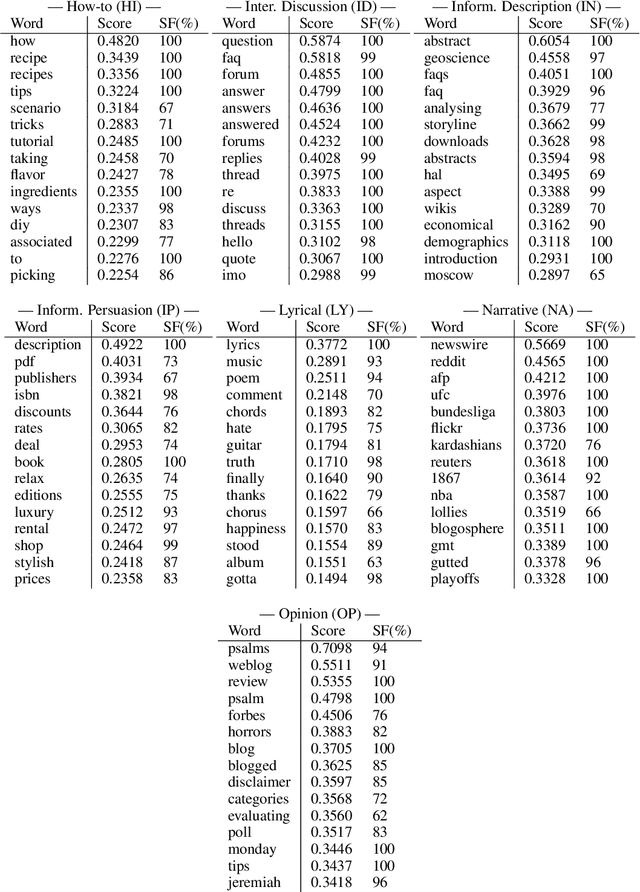
In recent years, several methods have been proposed for explaining individual predictions of deep learning models, yet there has been little study of how to aggregate these predictions to explain how such models view classes as a whole in text classification tasks. In this work, we propose a method for explaining classes using deep learning models and the Integrated Gradients feature attribution technique by aggregating explanations of individual examples in text classification to general descriptions of the classes. We demonstrate the approach on Web register (genre) classification using the XML-R model and the Corpus of Online Registers of English (CORE), finding that the method identifies plausible and discriminative keywords characterizing all but the smallest class.
Beyond the English Web: Zero-Shot Cross-Lingual and Lightweight Monolingual Classification of Registers
Feb 15, 2021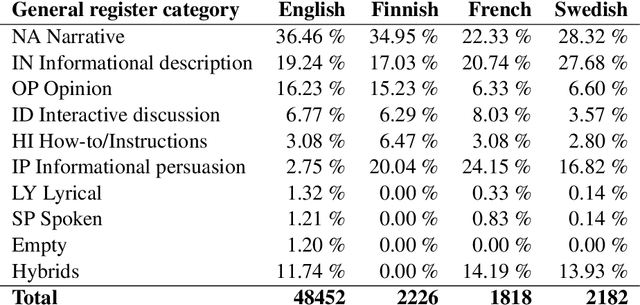
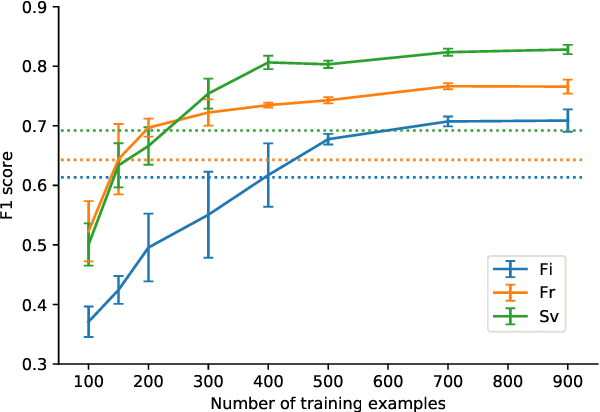
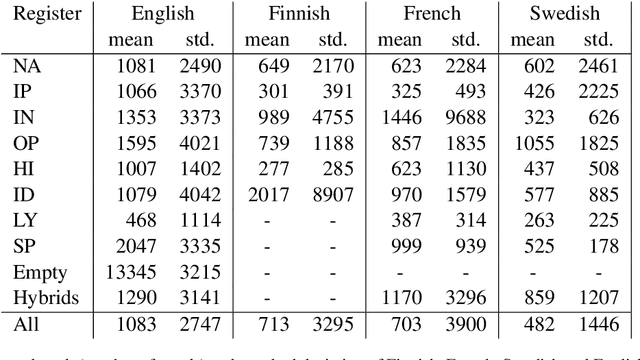
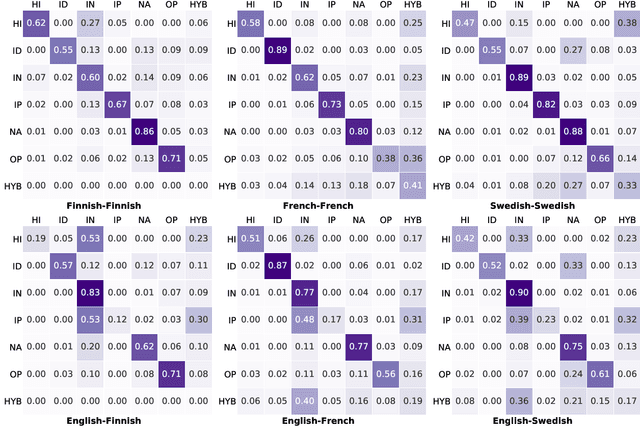
We explore cross-lingual transfer of register classification for web documents. Registers, that is, text varieties such as blogs or news are one of the primary predictors of linguistic variation and thus affect the automatic processing of language. We introduce two new register annotated corpora, FreCORE and SweCORE, for French and Swedish. We demonstrate that deep pre-trained language models perform strongly in these languages and outperform previous state-of-the-art in English and Finnish. Specifically, we show 1) that zero-shot cross-lingual transfer from the large English CORE corpus can match or surpass previously published monolingual models, and 2) that lightweight monolingual classification requiring very little training data can reach or surpass our zero-shot performance. We further analyse classification results finding that certain registers continue to pose challenges in particular for cross-lingual transfer.
Morphological Tagging and Lemmatization of Albanian: A Manually Annotated Corpus and Neural Models
Dec 02, 2019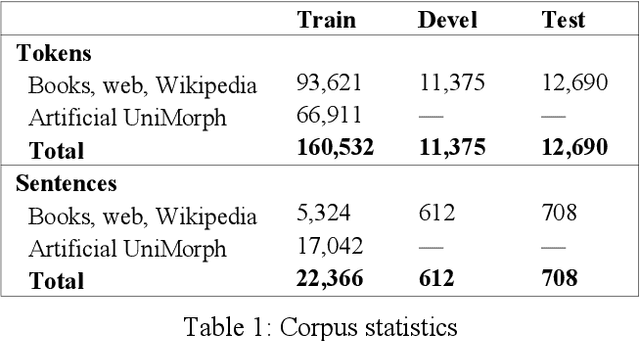
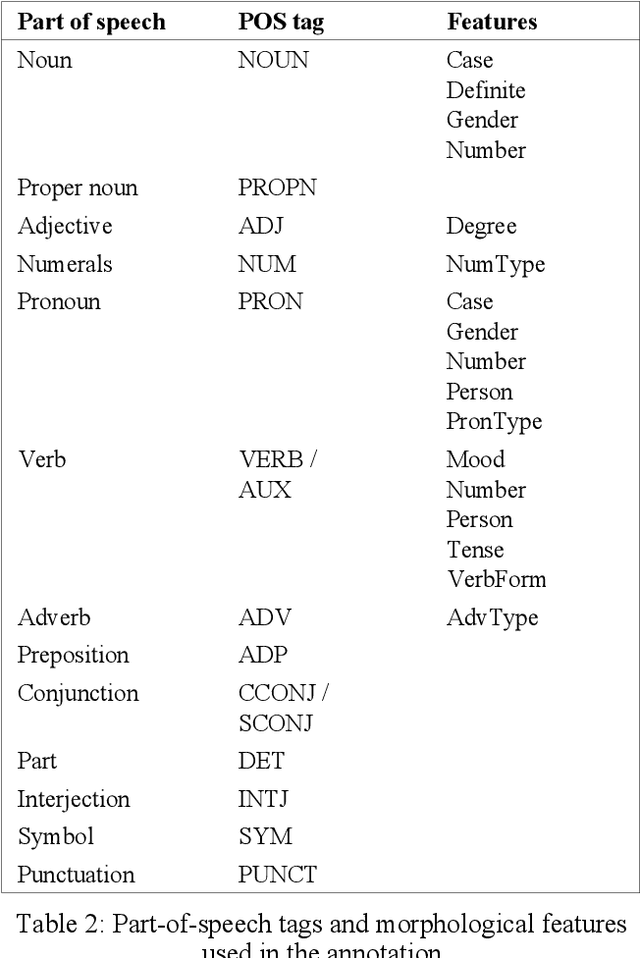

In this paper, we present the first publicly available part-of-speech and morphologically tagged corpus for the Albanian language, as well as a neural morphological tagger and lemmatizer trained on it. There is currently a lack of available NLP resources for Albanian, and its complex grammar and morphology present challenges to their development. We have created an Albanian part-of-speech corpus based on the Universal Dependencies schema for morphological annotation, containing about 118,000 tokens of naturally occuring text collected from different text sources, with an addition of 67,000 tokens of artificially created simple sentences used only in training. On this corpus, we subsequently train and evaluate segmentation, morphological tagging and lemmatization models, using the Turku Neural Parser Pipeline. On the held-out evaluation set, the model achieves 92.74% accuracy on part-of-speech tagging, 85.31% on morphological tagging, and 89.95% on lemmatization. The manually annotated corpus, as well as the trained models are available under an open license.
Is Multilingual BERT Fluent in Language Generation?
Oct 09, 2019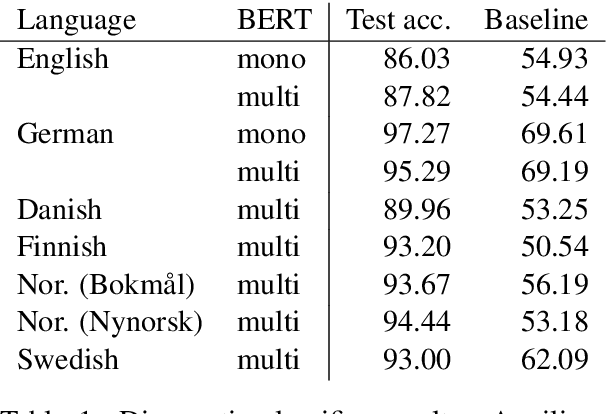

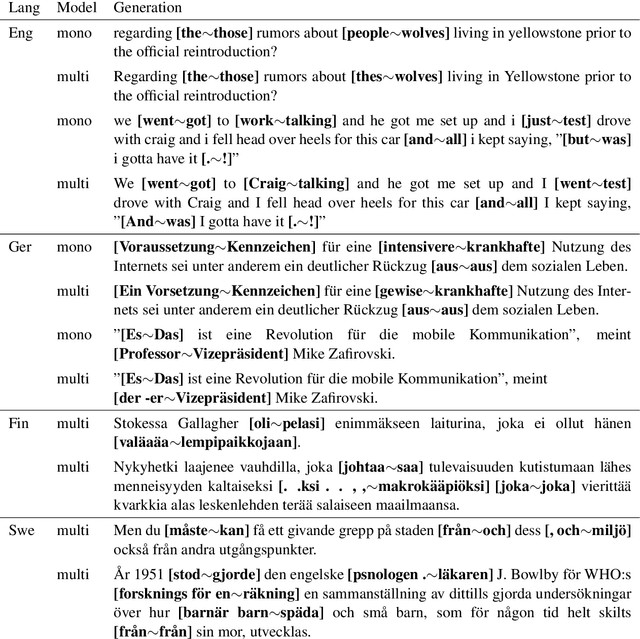

The multilingual BERT model is trained on 104 languages and meant to serve as a universal language model and tool for encoding sentences. We explore how well the model performs on several languages across several tasks: a diagnostic classification probing the embeddings for a particular syntactic property, a cloze task testing the language modelling ability to fill in gaps in a sentence, and a natural language generation task testing for the ability to produce coherent text fitting a given context. We find that the currently available multilingual BERT model is clearly inferior to the monolingual counterparts, and cannot in many cases serve as a substitute for a well-trained monolingual model. We find that the English and German models perform well at generation, whereas the multilingual model is lacking, in particular, for Nordic languages.
Template-free Data-to-Text Generation of Finnish Sports News
Oct 04, 2019
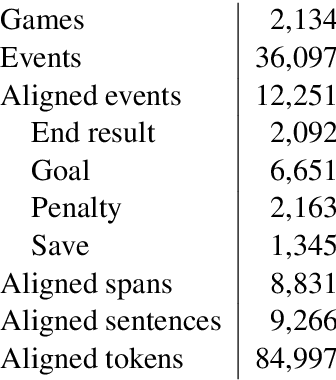
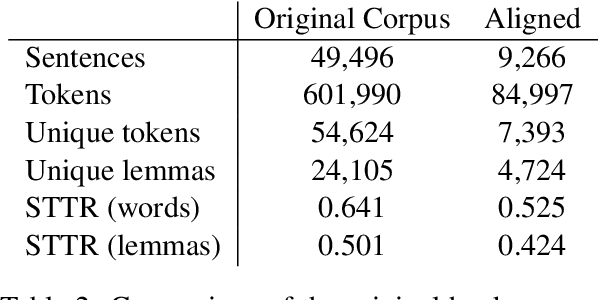
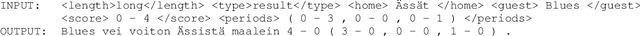
News articles such as sports game reports are often thought to closely follow the underlying game statistics, but in practice they contain a notable amount of background knowledge, interpretation, insight into the game, and quotes that are not present in the official statistics. This poses a challenge for automated data-to-text news generation with real-world news corpora as training data. We report on the development of a corpus of Finnish ice hockey news, edited to be suitable for training of end-to-end news generation methods, as well as demonstrate generation of text, which was judged by journalists to be relatively close to a viable product. The new dataset and system source code are available for research purposes at https://github.com/scoopmatic/finnish-hockey-news-generation-paper.
A Recurrent Neural Model with Attention for the Recognition of Chinese Implicit Discourse Relations
Apr 26, 2017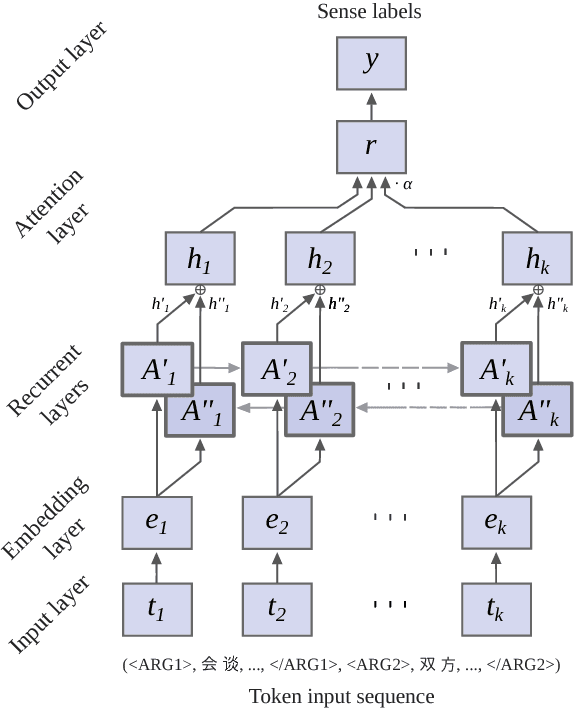
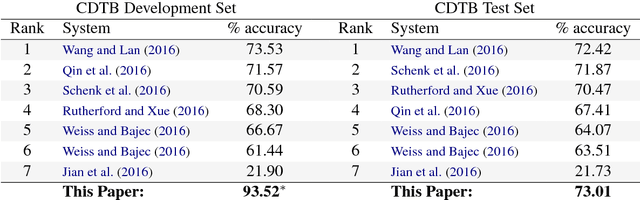
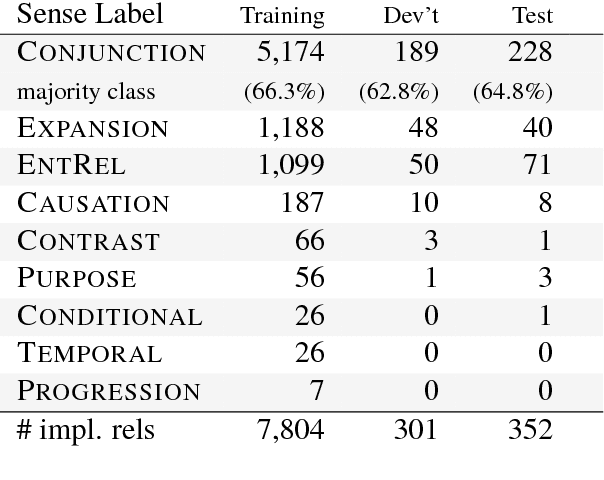

We introduce an attention-based Bi-LSTM for Chinese implicit discourse relations and demonstrate that modeling argument pairs as a joint sequence can outperform word order-agnostic approaches. Our model benefits from a partial sampling scheme and is conceptually simple, yet achieves state-of-the-art performance on the Chinese Discourse Treebank. We also visualize its attention activity to illustrate the model's ability to selectively focus on the relevant parts of an input sequence.
Bank distress in the news: Describing events through deep learning
Dec 27, 2016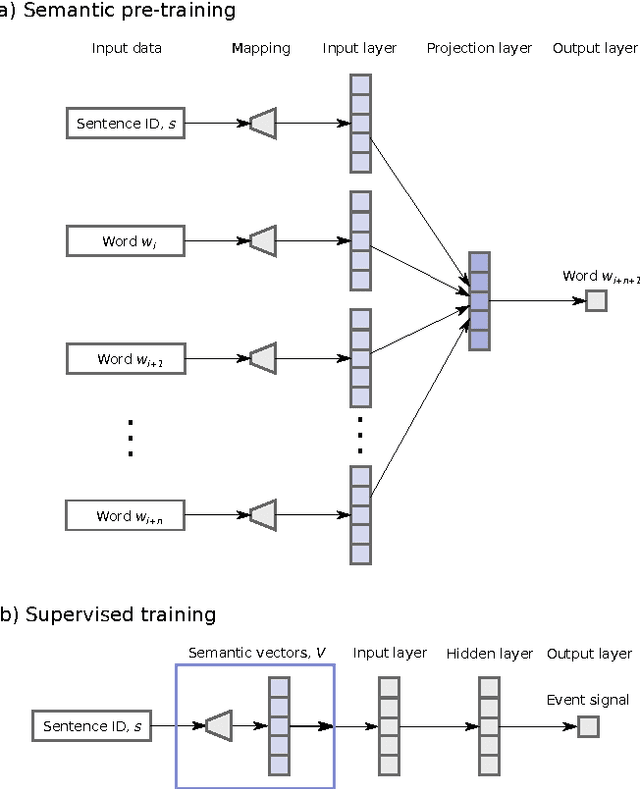
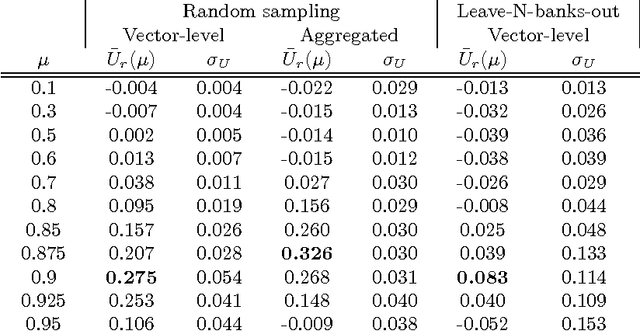
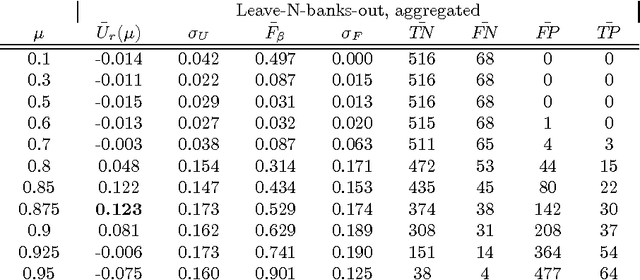
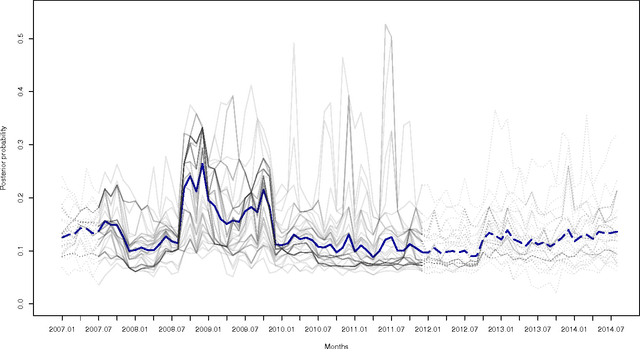
While many models are purposed for detecting the occurrence of significant events in financial systems, the task of providing qualitative detail on the developments is not usually as well automated. We present a deep learning approach for detecting relevant discussion in text and extracting natural language descriptions of events. Supervised by only a small set of event information, comprising entity names and dates, the model is leveraged by unsupervised learning of semantic vector representations on extensive text data. We demonstrate applicability to the study of financial risk based on news (6.6M articles), particularly bank distress and government interventions (243 events), where indices can signal the level of bank-stress-related reporting at the entity level, or aggregated at national or European level, while being coupled with explanations. Thus, we exemplify how text, as timely, widely available and descriptive data, can serve as a useful complementary source of information for financial and systemic risk analytics.
* Forthcoming in Neurocomputing. arXiv admin note: substantial text overlap with arXiv:1507.07870 [in version 1]
Detect & Describe: Deep learning of bank stress in the news
Jul 25, 2015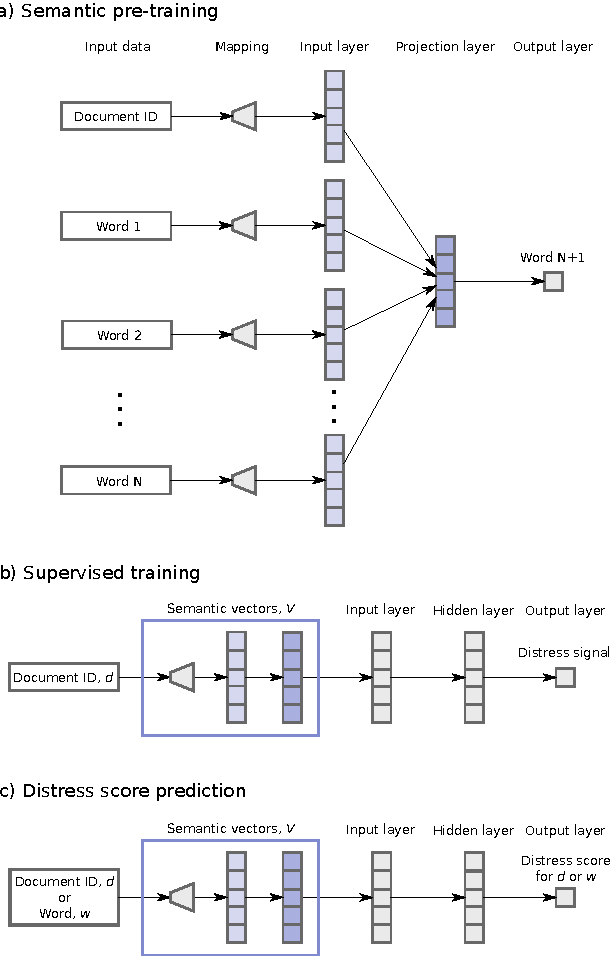
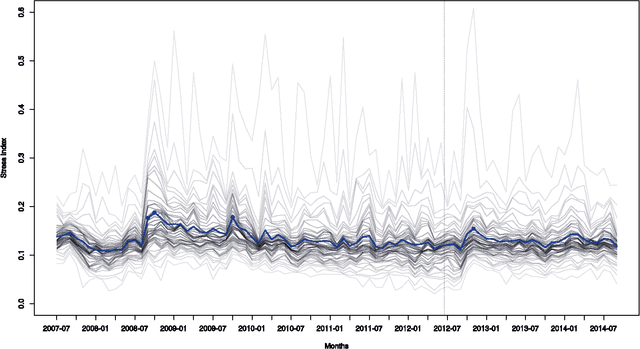
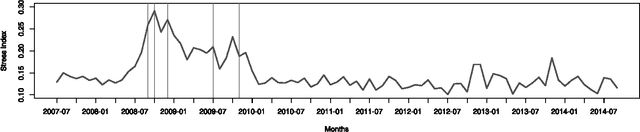
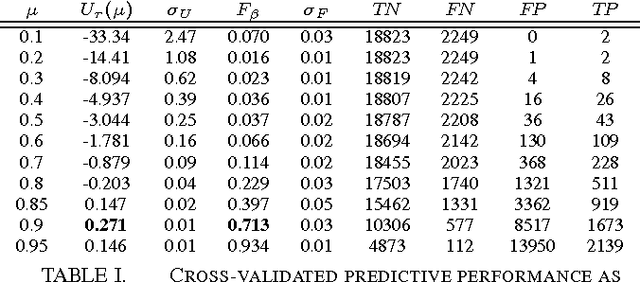
News is a pertinent source of information on financial risks and stress factors, which nevertheless is challenging to harness due to the sparse and unstructured nature of natural text. We propose an approach based on distributional semantics and deep learning with neural networks to model and link text to a scarce set of bank distress events. Through unsupervised training, we learn semantic vector representations of news articles as predictors of distress events. The predictive model that we learn can signal coinciding stress with an aggregated index at bank or European level, while crucially allowing for automatic extraction of text descriptions of the events, based on passages with high stress levels. The method offers insight that models based on other types of data cannot provide, while offering a general means for interpreting this type of semantic-predictive model. We model bank distress with data on 243 events and 6.6M news articles for 101 large European banks.
Exploratory topic modeling with distributional semantics
Jul 16, 2015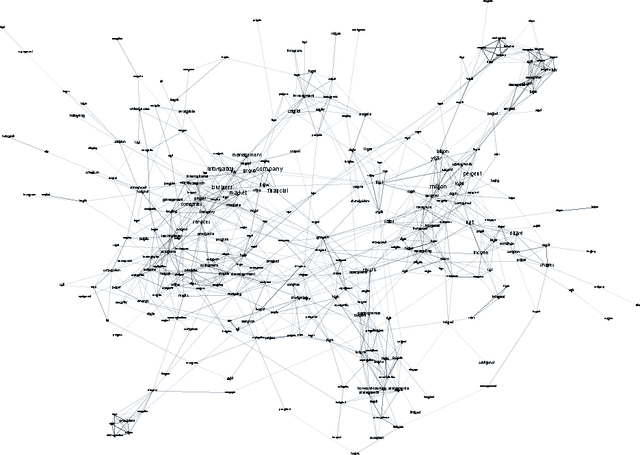
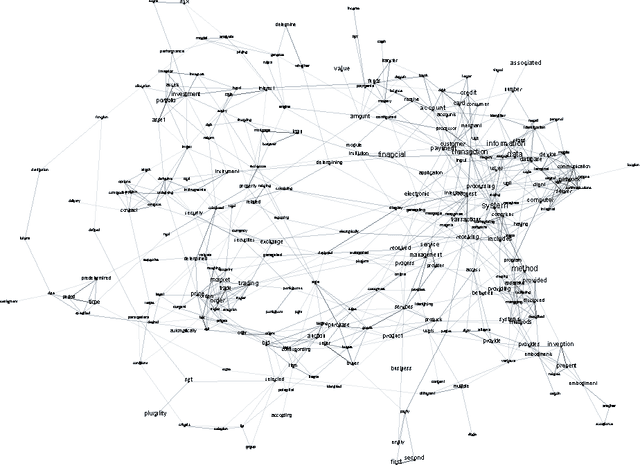
As we continue to collect and store textual data in a multitude of domains, we are regularly confronted with material whose largely unknown thematic structure we want to uncover. With unsupervised, exploratory analysis, no prior knowledge about the content is required and highly open-ended tasks can be supported. In the past few years, probabilistic topic modeling has emerged as a popular approach to this problem. Nevertheless, the representation of the latent topics as aggregations of semi-coherent terms limits their interpretability and level of detail. This paper presents an alternative approach to topic modeling that maps topics as a network for exploration, based on distributional semantics using learned word vectors. From the granular level of terms and their semantic similarity relations global topic structures emerge as clustered regions and gradients of concepts. Moreover, the paper discusses the visual interactive representation of the topic map, which plays an important role in supporting its exploration.
Interactive Visual Exploration of Topic Models using Graphs
Nov 27, 2014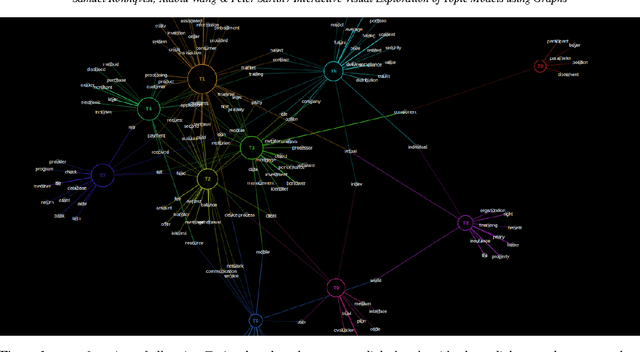
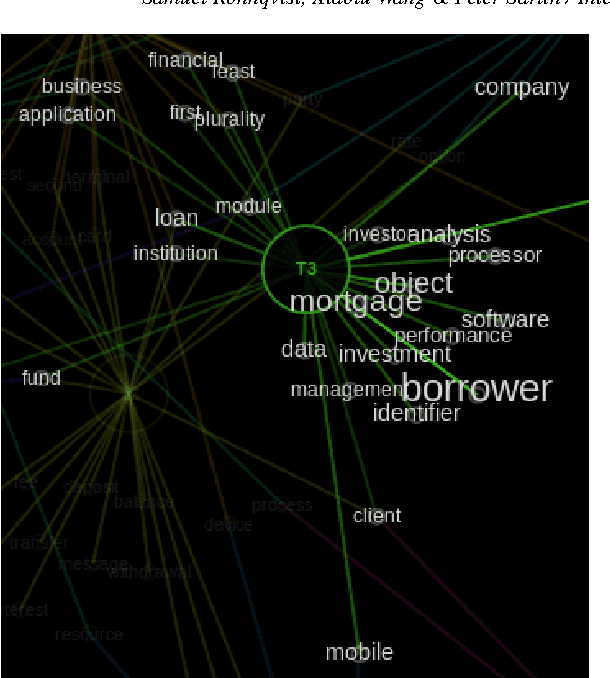
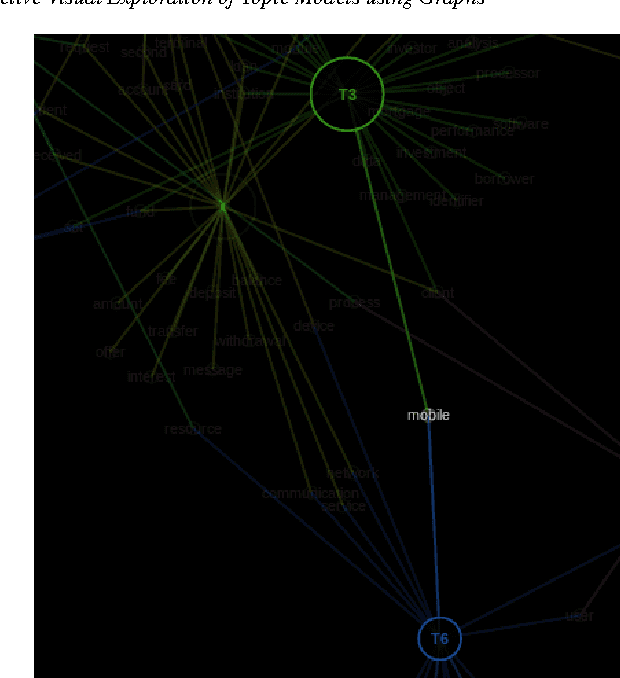
Probabilistic topic modeling is a popular and powerful family of tools for uncovering thematic structure in large sets of unstructured text documents. While much attention has been directed towards the modeling algorithms and their various extensions, comparatively few studies have concerned how to present or visualize topic models in meaningful ways. In this paper, we present a novel design that uses graphs to visually communicate topic structure and meaning. By connecting topic nodes via descriptive keyterms, the graph representation reveals topic similarities, topic meaning and shared, ambiguous keyterms. At the same time, the graph can be used for information retrieval purposes, to find documents by topic or topic subsets. To exemplify the utility of the design, we illustrate its use for organizing and exploring corpora of financial patents.