 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEDNEST: Federated Bilevel, Minimax, and Compositional Optimization
May 10, 2022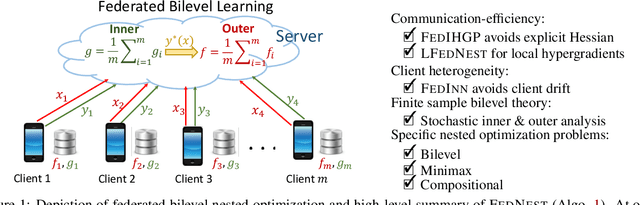
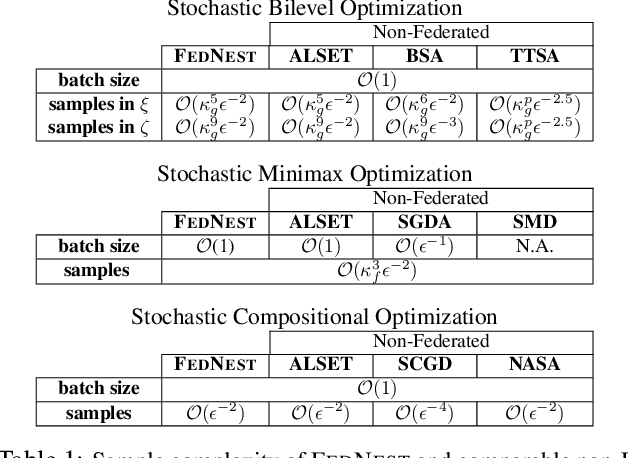
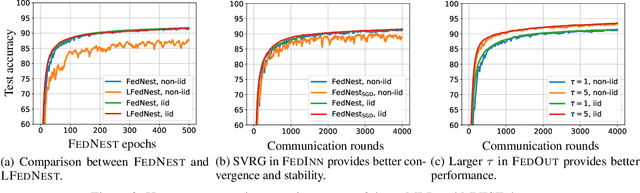
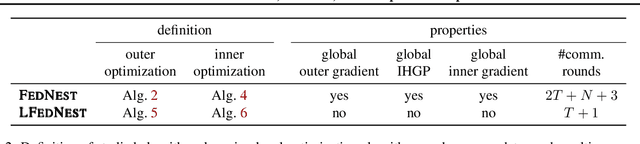
Standard federated optimization methods successfully apply to stochastic problems with single-level structure. However, many contemporary ML problems -- including adversarial robustness, hyperparameter tuning, and actor-critic -- fall under nested bilevel programming that subsumes minimax and compositional optimization. In this work, we propose FEDNEST: A federated alternating stochastic gradient method to address general nested problems. We establish provable convergence rates for FEDNEST in the presence of heterogeneous data and introduce variations for bilevel, minimax, and compositional optimization. FEDNEST introduces multiple innovations including federated hypergradient computation and variance reduction to address inner-level heterogeneity. We complement our theory with experiments on hyperparameter \& hyper-representation learning and minimax optimization that demonstrate the benefits of our method in practice. Code is available at https://github.com/mc-nya/FedNest.
System Identification via Nuclear Norm Regularization
Mar 30, 2022


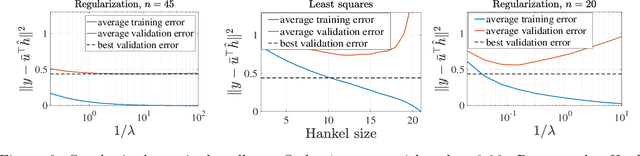
This paper studies the problem of identifying low-order linear systems via Hankel nuclear norm regularization. Hankel regularization encourages the low-rankness of the Hankel matrix, which maps to the low-orderness of the system. We provide novel statistical analysis for this regularization and carefully contrast it with the unregularized ordinary least-squares (OLS) estimator. Our analysis leads to new bounds on estimating the impulse response and the Hankel matrix associated with the linear system. We first design an input excitation and show that Hankel regularization enables one to recover the system using optimal number of observations in the true system order and achieve strong statistical estimation rates. Surprisingly, we demonstrate that the input design indeed matters, by showing that intuitive choices such as i.i.d. Gaussian input leads to provably sub-optimal sample complexity. To better understand the benefits of regularization, we also revisit the OLS estimator. Besides refining existing bounds, we experimentally identify when regularized approach improves over OLS: (1) For low-order systems with slow impulse-response decay, OLS method performs poorly in terms of sample complexity, (2) Hankel matrix returned by regularization has a more clear singular value gap that ease identification of the system order, (3) Hankel regularization is less sensitive to hyperparameter choice. Finally, we establish model selection guarantees through a joint train-validation procedure where we tune the regularization parameter for near-optimal estimation.
Provable and Efficient Continual Representation Learning
Mar 03, 2022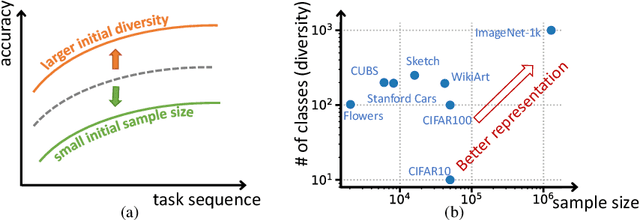
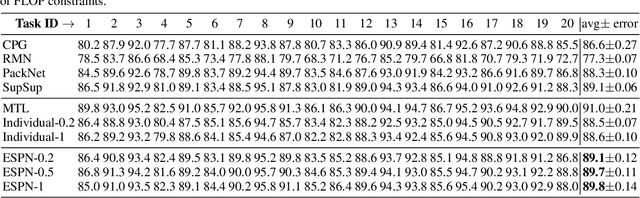
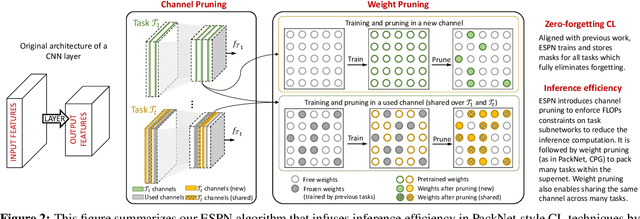
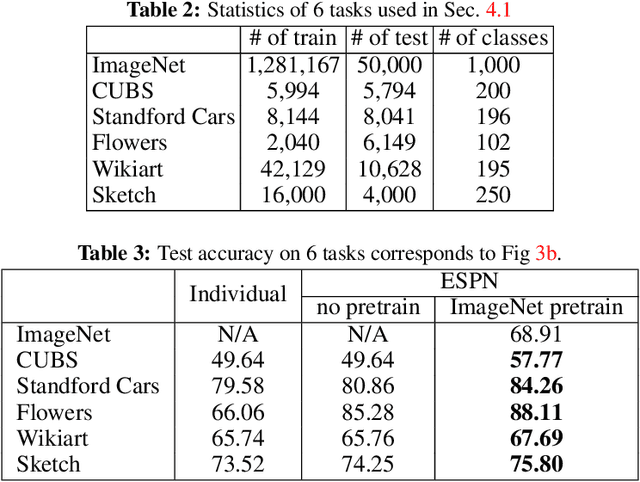
In continual learning (CL), the goal is to design models that can learn a sequence of tasks without catastrophic forgetting. While there is a rich set of techniques for CL, relatively little understanding exists on how representations built by previous tasks benefit new tasks that are added to the network. To address this, we study the problem of continual representation learning (CRL) where we learn an evolving representation as new tasks arrive. Focusing on zero-forgetting methods where tasks are embedded in subnetworks (e.g., PackNet), we first provide experiments demonstrating CRL can significantly boost sample efficiency when learning new tasks. To explain this, we establish theoretical guarantees for CRL by providing sample complexity and generalization error bounds for new tasks by formalizing the statistical benefits of previously-learned representations. Our analysis and experiments also highlight the importance of the order in which we learn the tasks. Specifically, we show that CL benefits if the initial tasks have large sample size and high "representation diversity". Diversity ensures that adding new tasks incurs small representation mismatch and can be learned with few samples while training only few additional nonzero weights. Finally, we ask whether one can ensure each task subnetwork to be efficient during inference time while retaining the benefits of representation learning. To this end, we propose an inference-efficient variation of PackNet called Efficient Sparse PackNet (ESPN) which employs joint channel & weight pruning. ESPN embeds tasks in channel-sparse subnets requiring up to 80% less FLOPs to compute while approximately retaining accuracy and is very competitive with a variety of baselines. In summary, this work takes a step towards data and compute-efficient CL with a representation learning perspective. GitHub page: https://github.com/ucr-optml/CtRL
Towards Sample-efficient Overparameterized Meta-learning
Jan 16, 2022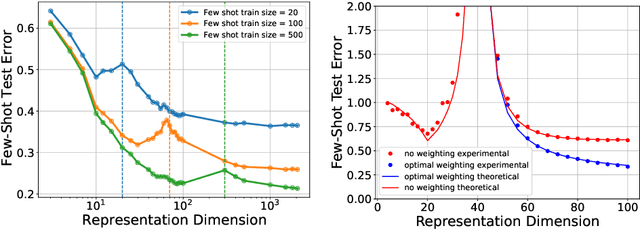
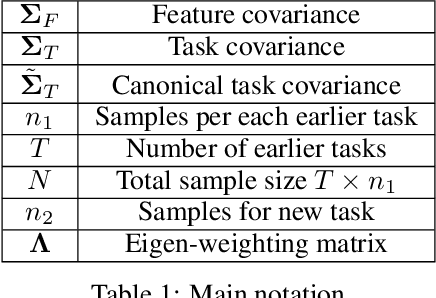
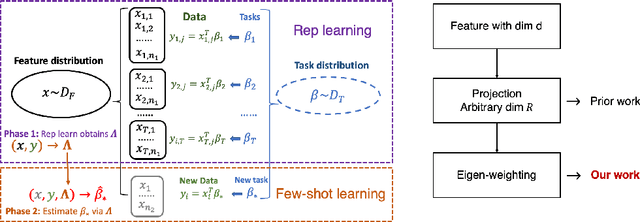

An overarching goal in machine learning is to build a generalizable model with few samples. To this end, overparameterization has been the subject of immense interest to explain the generalization ability of deep nets even when the size of the dataset is smaller than that of the model. While the prior literature focuses on the classical supervised setting, this paper aims to demystify overparameterization for meta-learning. Here we have a sequence of linear-regression tasks and we ask: (1) Given earlier tasks, what is the optimal linear representation of features for a new downstream task? and (2) How many samples do we need to build this representation? This work shows that surprisingly, overparameterization arises as a natural answer to these fundamental meta-learning questions. Specifically, for (1), we first show that learning the optimal representation coincides with the problem of designing a task-aware regularization to promote inductive bias. We leverage this inductive bias to explain how the downstream task actually benefits from overparameterization, in contrast to prior works on few-shot learning. For (2), we develop a theory to explain how feature covariance can implicitly help reduce the sample complexity well below the degrees of freedom and lead to small estimation error. We then integrate these findings to obtain an overall performance guarantee for our meta-learning algorithm. Numerical experiments on real and synthetic data verify our insights on overparameterized meta-learning.
Non-Stationary Representation Learning in Sequential Linear Bandits
Jan 13, 2022
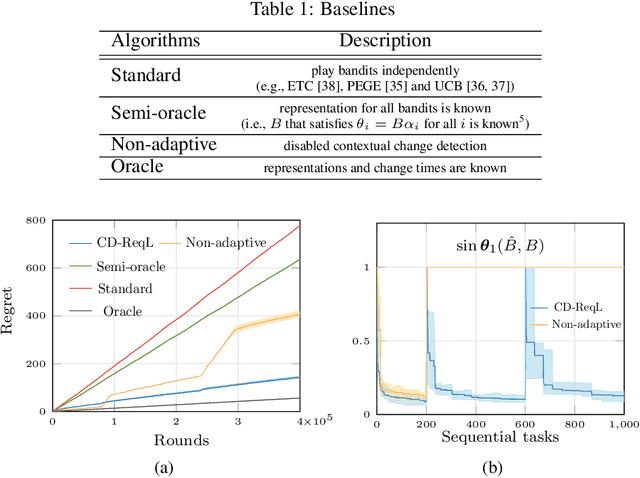
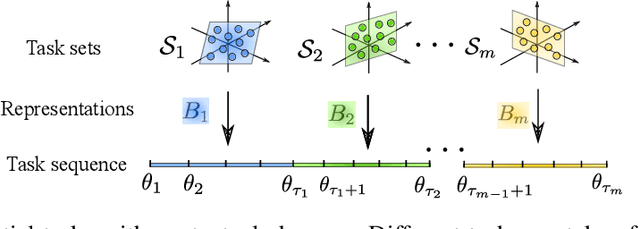
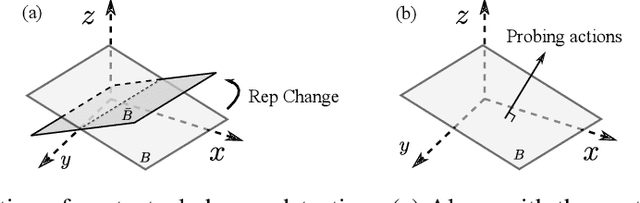
In this paper, we study representation learning for multi-task decision-making in non-stationary environments. We consider the framework of sequential linear bandits, where the agent performs a series of tasks drawn from distinct sets associated with different environments. The embeddings of tasks in each set share a low-dimensional feature extractor called representation, and representations are different across sets. We propose an online algorithm that facilitates efficient decision-making by learning and transferring non-stationary representations in an adaptive fashion. We prove that our algorithm significantly outperforms the existing ones that treat tasks independently. We also conduct experiments using both synthetic and real data to validate our theoretical insights and demonstrate the efficacy of our algorithm.
AutoBalance: Optimized Loss Functions for Imbalanced Data
Jan 04, 2022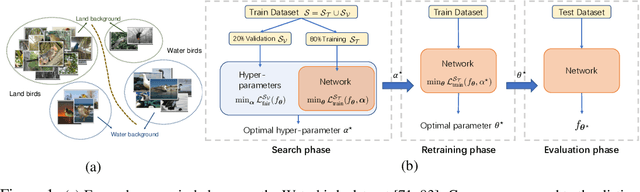
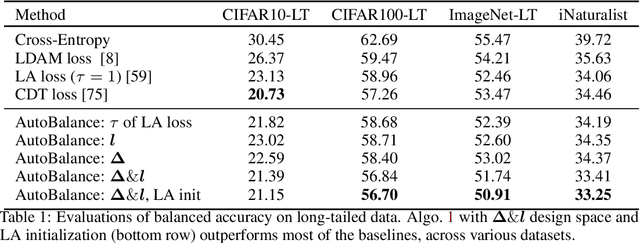
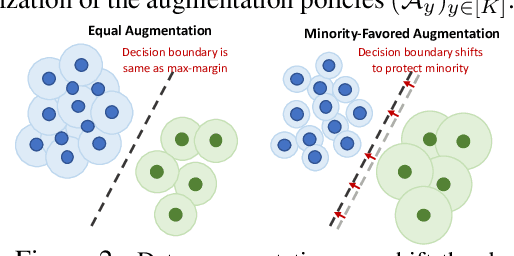

Imbalanced datasets are commonplace in modern machine learning problems. The presence of under-represented classes or groups with sensitive attributes results in concerns about generalization and fairness. Such concerns are further exacerbated by the fact that large capacity deep nets can perfectly fit the training data and appear to achieve perfect accuracy and fairness during training, but perform poorly during test. To address these challenges, we propose AutoBalance, a bi-level optimization framework that automatically designs a training loss function to optimize a blend of accuracy and fairness-seeking objectives. Specifically, a lower-level problem trains the model weights, and an upper-level problem tunes the loss function by monitoring and optimizing the desired objective over the validation data. Our loss design enables personalized treatment for classes/groups by employing a parametric cross-entropy loss and individualized data augmentation schemes. We evaluate the benefits and performance of our approach for the application scenarios of imbalanced and group-sensitive classification. Extensive empirical evaluations demonstrate the benefits of AutoBalance over state-of-the-art approaches. Our experimental findings are complemented with theoretical insights on loss function design and the benefits of train-validation split. All code is available open-source.
Identification and Adaptive Control of Markov Jump Systems: Sample Complexity and Regret Bounds
Nov 13, 2021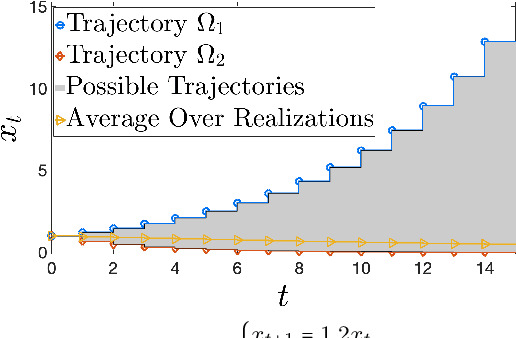
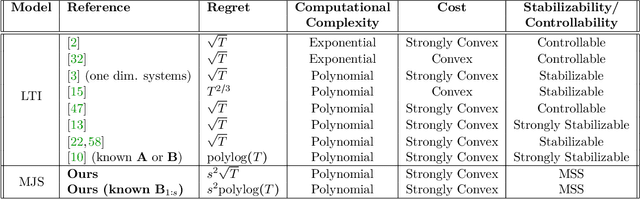
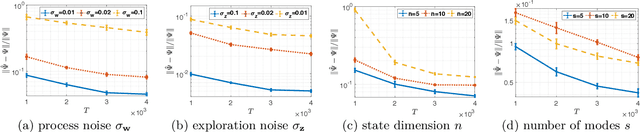

Learning how to effectively control unknown dynamical systems is crucial for intelligent autonomous systems. This task becomes a significant challenge when the underlying dynamics are changing with time. Motivated by this challenge, this paper considers the problem of controlling an unknown Markov jump linear system (MJS) to optimize a quadratic objective. By taking a model-based perspective, we consider identification-based adaptive control for MJSs. We first provide a system identification algorithm for MJS to learn the dynamics in each mode as well as the Markov transition matrix, underlying the evolution of the mode switches, from a single trajectory of the system states, inputs, and modes. Through mixing-time arguments, sample complexity of this algorithm is shown to be $\mathcal{O}(1/\sqrt{T})$. We then propose an adaptive control scheme that performs system identification together with certainty equivalent control to adapt the controllers in an episodic fashion. Combining our sample complexity results with recent perturbation results for certainty equivalent control, we prove that when the episode lengths are appropriately chosen, the proposed adaptive control scheme achieves $\mathcal{O}(\sqrt{T})$ regret, which can be improved to $\mathcal{O}(polylog(T))$ with partial knowledge of the system. Our proof strategy introduces innovations to handle Markovian jumps and a weaker notion of stability common in MJSs. Our analysis provides insights into system theoretic quantities that affect learning accuracy and control performance. Numerical simulations are presented to further reinforce these insights.
Post-hoc Models for Performance Estimation of Machine Learning Inference
Oct 06, 2021
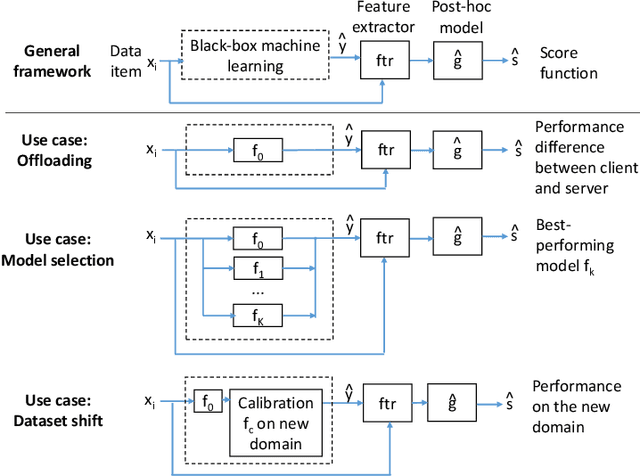
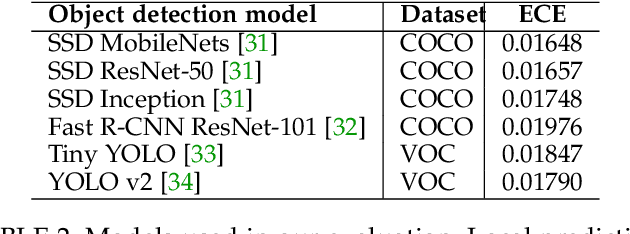
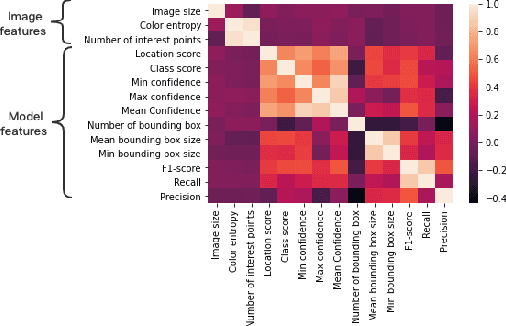
Estimating how well a machine learning model performs during inference is critical in a variety of scenarios (for example, to quantify uncertainty, or to choose from a library of available models). However, the standard accuracy estimate of softmax confidence is not versatile and cannot reliably predict different performance metrics (e.g., F1-score, recall) or the performance in different application scenarios or input domains. In this work, we systematically generalize performance estimation to a diverse set of metrics and scenarios and discuss generalized notions of uncertainty calibration. We propose the use of post-hoc models to accomplish this goal and investigate design parameters, including the model type, feature engineering, and performance metric, to achieve the best estimation quality. Emphasis is given to object detection problems and, unlike prior work, our approach enables the estimation of per-image metrics such as recall and F1-score. Through extensive experiments with computer vision models and datasets in three use cases -- mobile edge offloading, model selection, and dataset shift -- we find that proposed post-hoc models consistently outperform the standard calibrated confidence baselines. To the best of our knowledge, this is the first work to develop a unified framework to address different performance estimation problems for machine learning inference.
Certainty Equivalent Quadratic Control for Markov Jump Systems
May 26, 2021

Real-world control applications often involve complex dynamics subject to abrupt changes or variations. Markov jump linear systems (MJS) provide a rich framework for modeling such dynamics. Despite an extensive history, theoretical understanding of parameter sensitivities of MJS control is somewhat lacking. Motivated by this, we investigate robustness aspects of certainty equivalent model-based optimal control for MJS with quadratic cost function. Given the uncertainty in the system matrices and in the Markov transition matrix is bounded by $\epsilon$ and $\eta$ respectively, robustness results are established for (i) the solution to coupled Riccati equations and (ii) the optimal cost, by providing explicit perturbation bounds which decay as $\mathcal{O}(\epsilon + \eta)$ and $\mathcal{O}((\epsilon + \eta)^2)$ respectively.
Generalization Guarantees for Neural Architecture Search with Train-Validation Split
May 10, 2021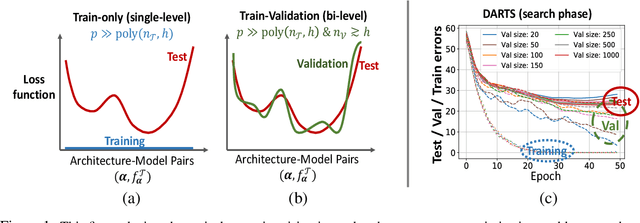
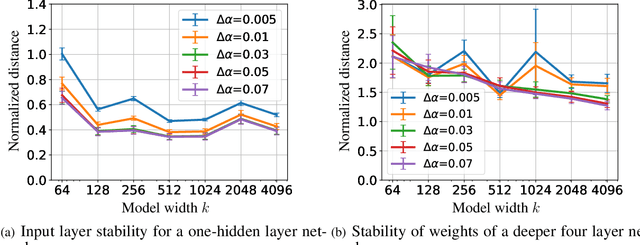
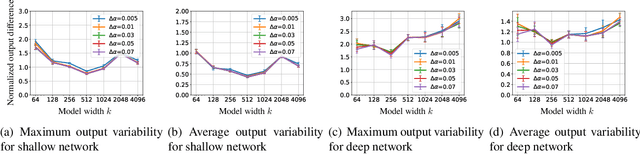
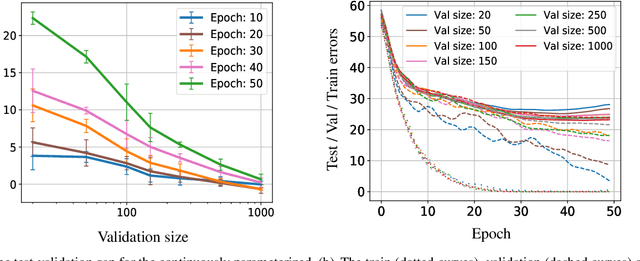
Neural Architecture Search (NAS) is a popular method for automatically designing optimized architectures for high-performance deep learning. In this approach, it is common to use bilevel optimization where one optimizes the model weights over the training data (lower-level problem) and various hyperparameters such as the configuration of the architecture over the validation data (upper-level problem). This paper explores the statistical aspects of such problems with train-validation splits. In practice, the lower-level problem is often overparameterized and can easily achieve zero loss. Thus, a-priori it seems impossible to distinguish the right hyperparameters based on training loss alone which motivates a better understanding of the role of train-validation split. To this aim this work establishes the following results. (1) We show that refined properties of the validation loss such as risk and hyper-gradients are indicative of those of the true test loss. This reveals that the upper-level problem helps select the most generalizable model and prevent overfitting with a near-minimal validation sample size. Importantly, this is established for continuous search spaces which are highly relevant for popular differentiable search schemes. (2) We establish generalization bounds for NAS problems with an emphasis on an activation search problem. When optimized with gradient-descent, we show that the train-validation procedure returns the best (model, architecture) pair even if all architectures can perfectly fit the training data to achieve zero error. (3) Finally, we highlight rigorous connections between NAS, multiple kernel learning, and low-rank matrix learning. The latter leads to novel algorithmic insights where the solution of the upper problem can be accurately learned via efficient spectral methods to achieve near-minimal risk.