 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContactGrasp: Functional Multi-finger Grasp Synthesis from Contact
Apr 09, 2019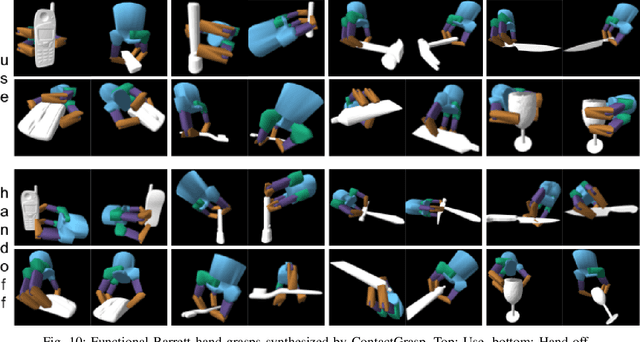

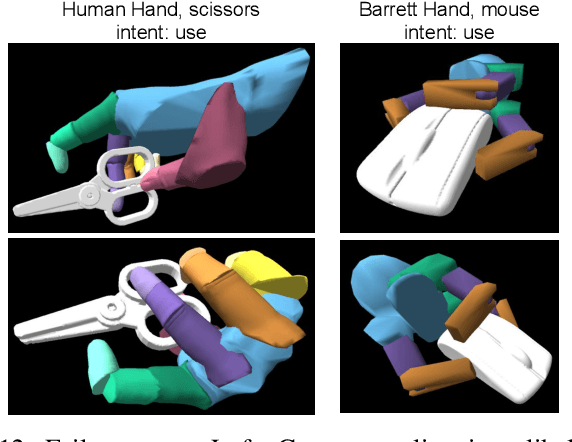
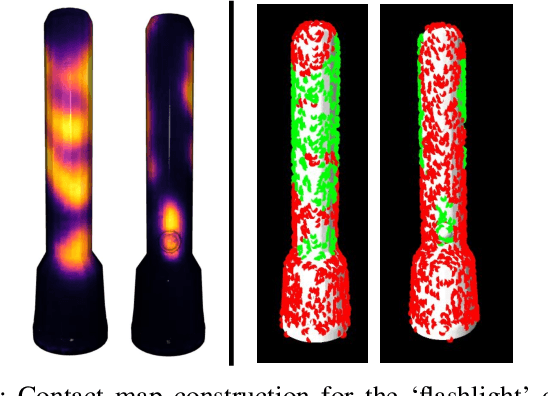
Grasping and manipulating objects is an important human skill. Since most objects are designed to be manipulated by human hands, anthropomorphic hands can enable richer human-robot interaction. Desirable grasps are not only stable, but also functional: they enable post-grasp actions with the object. However, functional grasp synthesis for high-dof anthropomorphic hands from object shape alone is challenging. We present ContactGrasp, a framework that allows functional grasp synthesis from object shape and contact on the object surface. Contact can be manually specified or obtained through demonstrations. Our contact representation is object-centric and allows functional grasp synthesis even for hand models different than the one used for demonstration. Using a dataset of contact demonstrations from humans grasping diverse household objects, we synthesize functional grasps for three hand models and two functional intents. The project webpage is https://contactdb.cc.gatech.edu/contactgrasp.html.
Geometry-Aware Learning of Maps for Camera Localization
Apr 02, 2018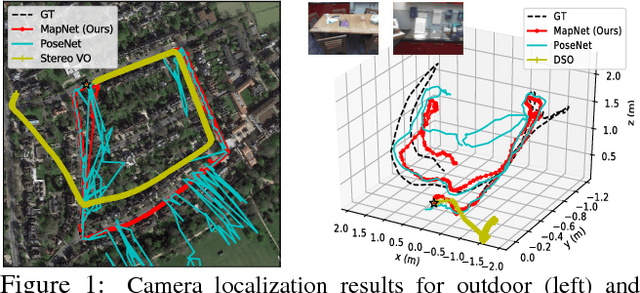

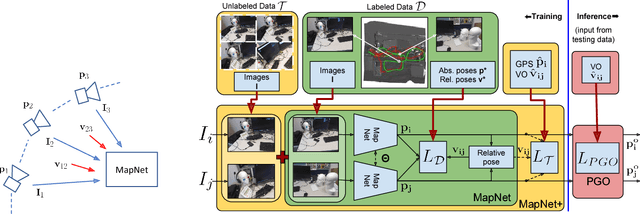
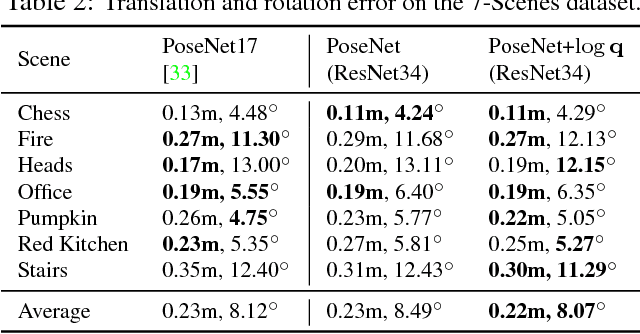
Maps are a key component in image-based camera localization and visual SLAM systems: they are used to establish geometric constraints between images, correct drift in relative pose estimation, and relocalize cameras after lost tracking. The exact definitions of maps, however, are often application-specific and hand-crafted for different scenarios (e.g. 3D landmarks, lines, planes, bags of visual words). We propose to represent maps as a deep neural net called MapNet, which enables learning a data-driven map representation. Unlike prior work on learning maps, MapNet exploits cheap and ubiquitous sensory inputs like visual odometry and GPS in addition to images and fuses them together for camera localization. Geometric constraints expressed by these inputs, which have traditionally been used in bundle adjustment or pose-graph optimization, are formulated as loss terms in MapNet training and also used during inference. In addition to directly improving localization accuracy, this allows us to update the MapNet (i.e., maps) in a self-supervised manner using additional unlabeled video sequences from the scene. We also propose a novel parameterization for camera rotation which is better suited for deep-learning based camera pose regression. Experimental results on both the indoor 7-Scenes dataset and the outdoor Oxford RobotCar dataset show significant performance improvement over prior work. The MapNet project webpage is https://goo.gl/mRB3Au.
DeepNav: Learning to Navigate Large Cities
May 20, 2017
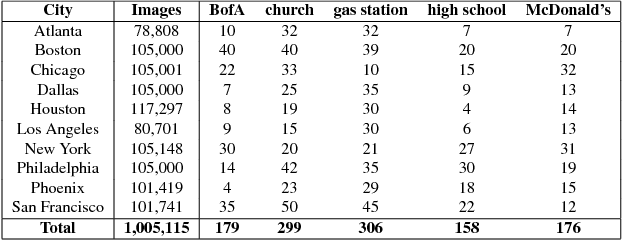
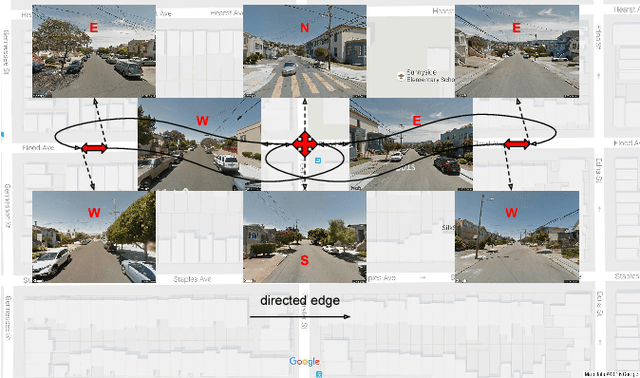
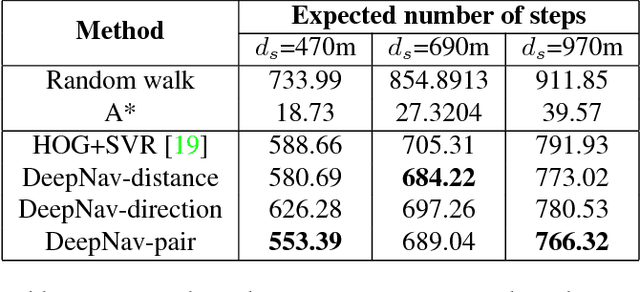
We present DeepNav, a Convolutional Neural Network (CNN) based algorithm for navigating large cities using locally visible street-view images. The DeepNav agent learns to reach its destination quickly by making the correct navigation decisions at intersections. We collect a large-scale dataset of street-view images organized in a graph where nodes are connected by roads. This dataset contains 10 city graphs and more than 1 million street-view images. We propose 3 supervised learning approaches for the navigation task and show how A* search in the city graph can be used to generate supervision for the learning. Our annotation process is fully automated using publicly available mapping services and requires no human input. We evaluate the proposed DeepNav models on 4 held-out cities for navigating to 5 different types of destinations. Our algorithms outperform previous work that uses hand-crafted features and Support Vector Regression (SVR)[19].
StuffNet: Using 'Stuff' to Improve Object Detection
Jan 30, 2017

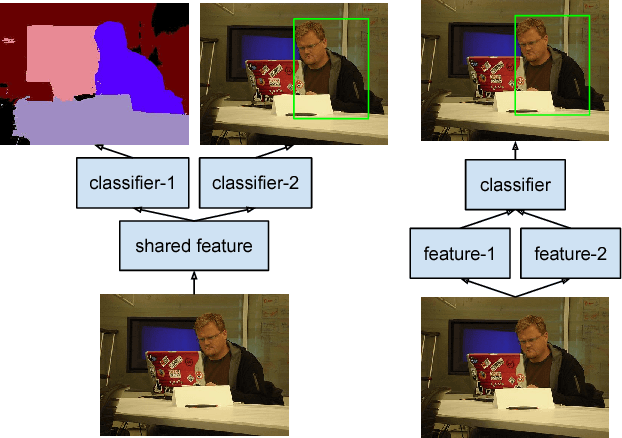

We propose a Convolutional Neural Network (CNN) based algorithm - StuffNet - for object detection. In addition to the standard convolutional features trained for region proposal and object detection [31], StuffNet uses convolutional features trained for segmentation of objects and 'stuff' (amorphous categories such as ground and water). Through experiments on Pascal VOC 2010, we show the importance of features learnt from stuff segmentation for improving object detection performance. StuffNet improves performance from 18.8% mAP to 23.9% mAP for small objects. We also devise a method to train StuffNet on datasets that do not have stuff segmentation labels. Through experiments on Pascal VOC 2007 and 2012, we demonstrate the effectiveness of this method and show that StuffNet also significantly improves object detection performance on such datasets.
Occlusion-Aware Object Localization, Segmentation and Pose Estimation
Jul 27, 2015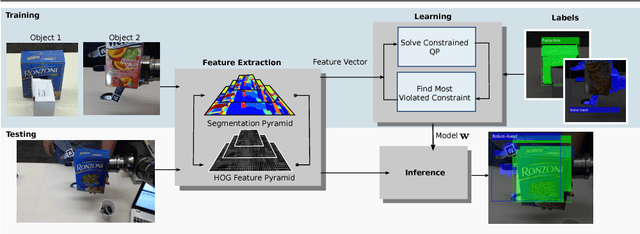
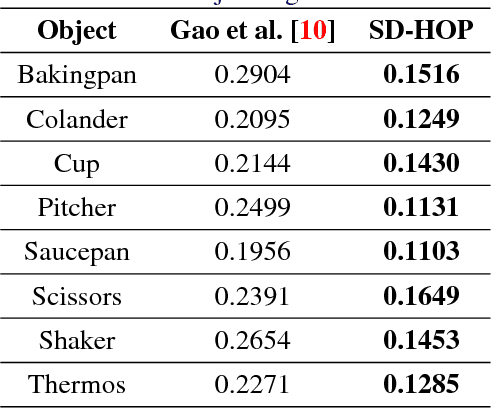
We present a learning approach for localization and segmentation of objects in an image in a manner that is robust to partial occlusion. Our algorithm produces a bounding box around the full extent of the object and labels pixels in the interior that belong to the object. Like existing segmentation aware detection approaches, we learn an appearance model of the object and consider regions that do not fit this model as potential occlusions. However, in addition to the established use of pairwise potentials for encouraging local consistency, we use higher order potentials which capture information at the level of im- age segments. We also propose an efficient loss function that targets both localization and segmentation performance. Our algorithm achieves 13.52% segmentation error and 0.81 area under the false-positive per image vs. recall curve on average over the challenging CMU Kitchen Occlusion Dataset. This is a 42.44% decrease in segmentation error and a 16.13% increase in localization performance compared to the state-of-the-art. Finally, we show that the visibility labelling produced by our algorithm can make full 3D pose estimation from a single image robust to occlusion.