 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage, Not Averages: Semantic Stratification for Trustworthy Retrieval Evaluation
Apr 22, 2026Retrieval quality is the primary bottleneck for accuracy and robustness in retrieval-augmented generation (RAG). Current evaluation relies on heuristically constructed query sets, which introduce a hidden intrinsic bias. We formalize retrieval evaluation as a statistical estimation problem, showing that metric reliability is fundamentally limited by the evaluation-set construction. We further introduce \emph{semantic stratification}, which grounds evaluation in corpus structure by organizing documents into an interpretable global space of entity-based clusters and systematically generating queries for missing strata. This yields (1) formal semantic coverage guarantees across retrieval regimes and (2) interpretable visibility into retrieval failure modes. Experiments across multiple benchmarks and retrieval methods validate our framework. The results expose systematic coverage gaps, identify structural signals that explain variance in retrieval performance, and show that stratified evaluation yields more stable and transparent assessments while supporting more trustworthy decision-making than aggregate metrics.
Can Linguistically Related Languages Guide LLM Translation in Low-Resource Settings?
Mar 17, 2026Large Language Models (LLMs) have achieved strong performance across many downstream tasks, yet their effectiveness in extremely low-resource machine translation remains limited. Standard adaptation techniques typically rely on large-scale parallel data or extensive fine-tuning, which are infeasible for the long tail of underrepresented languages. In this work, we investigate a more constrained question: in data-scarce settings, to what extent can linguistically similar pivot languages and few-shot demonstrations provide useful guidance for on-the-fly adaptation in LLMs? We study a data-efficient experimental setup that combines linguistically related pivot languages with few-shot in-context examples, without any parameter updates, and evaluate translation behavior under controlled conditions. Our analysis shows that while pivot-based prompting can yield improvements in certain configurations, particularly in settings where the target language is less well represented in the model's vocabulary, the gains are often modest and sensitive to few shot example construction. For closely related or better represented varieties, we observe diminishing or inconsistent gains. Our findings provide empirical guidance on how and when inference-time prompting and pivot-based examples can be used as a lightweight alternative to fine-tuning in low-resource translation settings.
Overcoming Mode Collapse with Adaptive Multi Adversarial Training
Dec 29, 2021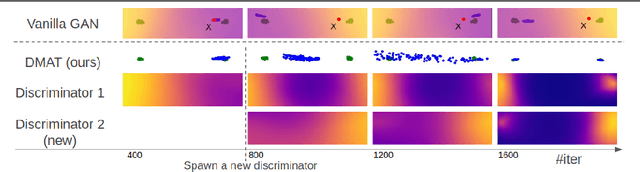
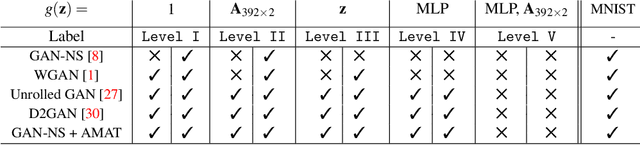

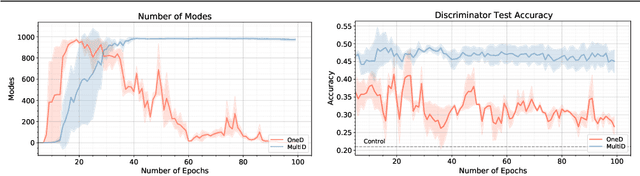
Generative Adversarial Networks (GANs) are a class of generative models used for various applications, but they have been known to suffer from the mode collapse problem, in which some modes of the target distribution are ignored by the generator. Investigative study using a new data generation procedure indicates that the mode collapse of the generator is driven by the discriminator's inability to maintain classification accuracy on previously seen samples, a phenomenon called Catastrophic Forgetting in continual learning. Motivated by this observation, we introduce a novel training procedure that adaptively spawns additional discriminators to remember previous modes of generation. On several datasets, we show that our training scheme can be plugged-in to existing GAN frameworks to mitigate mode collapse and improve standard metrics for GAN evaluation.
Goal-driven Command Recommendations for Analysts
Nov 12, 2020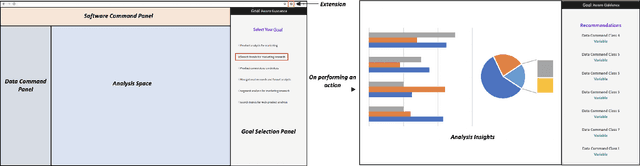
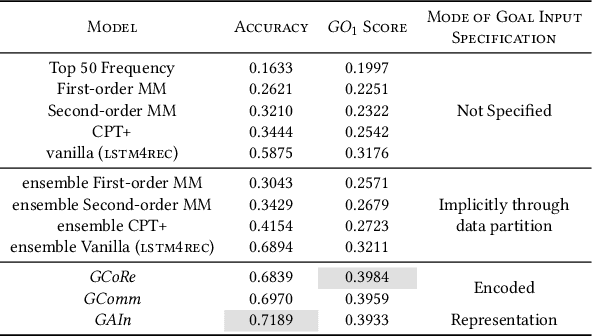
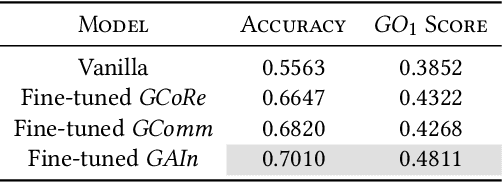
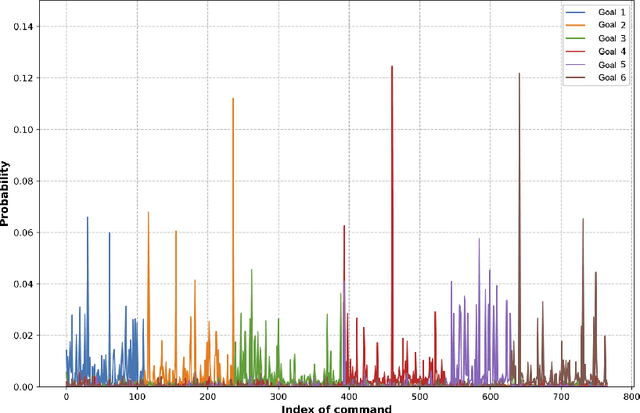
Recent times have seen data analytics software applications become an integral part of the decision-making process of analysts. The users of these software applications generate a vast amount of unstructured log data. These logs contain clues to the user's goals, which traditional recommender systems may find difficult to model implicitly from the log data. With this assumption, we would like to assist the analytics process of a user through command recommendations. We categorize the commands into software and data categories based on their purpose to fulfill the task at hand. On the premise that the sequence of commands leading up to a data command is a good predictor of the latter, we design, develop, and validate various sequence modeling techniques. In this paper, we propose a framework to provide goal-driven data command recommendations to the user by leveraging unstructured logs. We use the log data of a web-based analytics software to train our neural network models and quantify their performance, in comparison to relevant and competitive baselines. We propose a custom loss function to tailor the recommended data commands according to the goal information provided exogenously. We also propose an evaluation metric that captures the degree of goal orientation of the recommendations. We demonstrate the promise of our approach by evaluating the models with the proposed metric and showcasing the robustness of our models in the case of adversarial examples, where the user activity is misaligned with selected goal, through offline evaluation.
IITK-RSA at SemEval-2020 Task 5: Detecting Counterfactuals
Jul 21, 2020
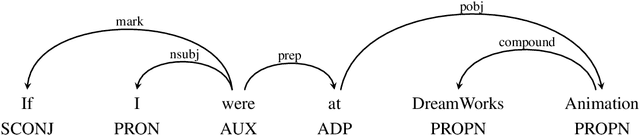
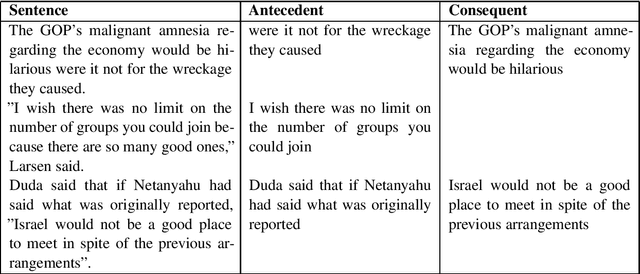
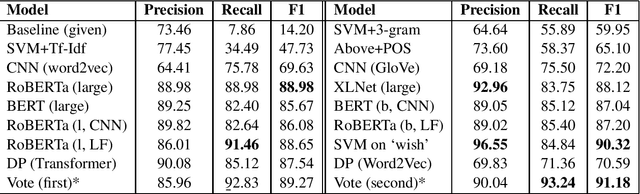
This paper describes our efforts in tackling Task 5 of SemEval-2020. The task involved detecting a class of textual expressions known as counterfactuals and separating them into their constituent elements. Counterfactual statements describe events that have not or could not have occurred and the possible implications of such events. While counterfactual reasoning is natural for humans, understanding these expressions is difficult for artificial agents due to a variety of linguistic subtleties. Our final submitted approaches were an ensemble of various fine-tuned transformer-based and CNN-based models for the first subtask and a transformer model with dependency tree information for the second subtask. We ranked 4-th and 9-th in the overall leaderboard. We also explored various other approaches that involved the use of classical methods, other neural architectures and the incorporation of different linguistic features.