 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulSense: Sense-Driven Interpreting for Efficient Simultaneous Speech Translation
Sep 26, 2025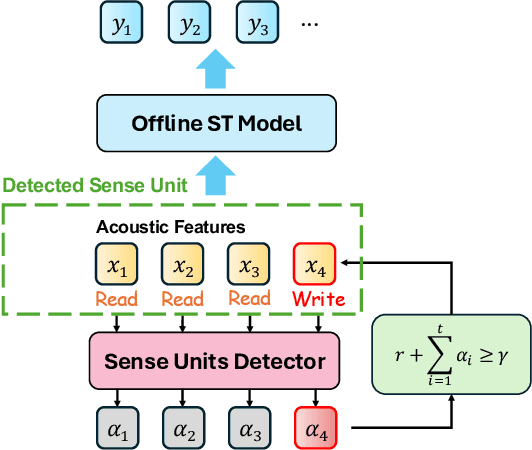

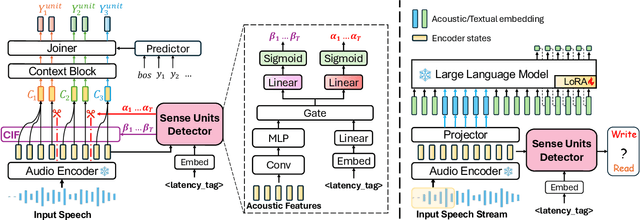
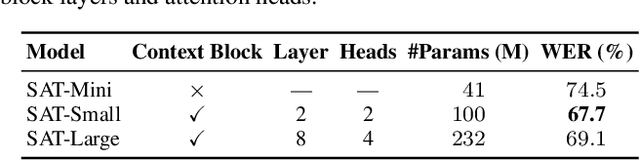
How to make human-interpreter-like read/write decisions for simultaneous speech translation (SimulST) systems? Current state-of-the-art systems formulate SimulST as a multi-turn dialogue task, requiring specialized interleaved training data and relying on computationally expensive large language model (LLM) inference for decision-making. In this paper, we propose SimulSense, a novel framework for SimulST that mimics human interpreters by continuously reading input speech and triggering write decisions to produce translation when a new sense unit is perceived. Experiments against two state-of-the-art baseline systems demonstrate that our proposed method achieves a superior quality-latency tradeoff and substantially improved real-time efficiency, where its decision-making is up to 9.6x faster than the baselines.
SC-SOT: Conditioning the Decoder on Diarized Speaker Information for End-to-End Overlapped Speech Recognition
Jun 15, 2025We propose Speaker-Conditioned Serialized Output Training (SC-SOT), an enhanced SOT-based training for E2E multi-talker ASR. We first probe how SOT handles overlapped speech, and we found the decoder performs implicit speaker separation. We hypothesize this implicit separation is often insufficient due to ambiguous acoustic cues in overlapping regions. To address this, SC-SOT explicitly conditions the decoder on speaker information, providing detailed information about "who spoke when". Specifically, we enhance the decoder by incorporating: (1) speaker embeddings, which allow the model to focus on the acoustic characteristics of the target speaker, and (2) speaker activity information, which guides the model to suppress non-target speakers. The speaker embeddings are derived from a jointly trained E2E speaker diarization model, mitigating the need for speaker enrollment. Experimental results demonstrate the effectiveness of our conditioning approach on overlapped speech.
Indonesian-English Code-Switching Speech Synthesizer Utilizing Multilingual STEN-TTS and Bert LID
Dec 26, 2024Multilingual text-to-speech systems convert text into speech across multiple languages. In many cases, text sentences may contain segments in different languages, a phenomenon known as code-switching. This is particularly common in Indonesia, especially between Indonesian and English. Despite its significance, no research has yet developed a multilingual TTS system capable of handling code-switching between these two languages. This study addresses Indonesian-English code-switching in STEN-TTS. Key modifications include adding a language identification component to the text-to-phoneme conversion using finetuned BERT for per-word language identification, as well as removing language embedding from the base model. Experimental results demonstrate that the code-switching model achieves superior naturalness and improved speech intelligibility compared to the Indonesian and English baseline STEN-TTS models.
Continual Learning in Machine Speech Chain Using Gradient Episodic Memory
Nov 27, 2024



Continual learning for automatic speech recognition (ASR) systems poses a challenge, especially with the need to avoid catastrophic forgetting while maintaining performance on previously learned tasks. This paper introduces a novel approach leveraging the machine speech chain framework to enable continual learning in ASR using gradient episodic memory (GEM). By incorporating a text-to-speech (TTS) component within the machine speech chain, we support the replay mechanism essential for GEM, allowing the ASR model to learn new tasks sequentially without significant performance degradation on earlier tasks. Our experiments, conducted on the LJ Speech dataset, demonstrate that our method outperforms traditional fine-tuning and multitask learning approaches, achieving a substantial error rate reduction while maintaining high performance across varying noise conditions. We showed the potential of our semi-supervised machine speech chain approach for effective and efficient continual learning in speech recognition.
A Transformer Framework for Simultaneous Segmentation, Classification, and Caller Identification of Marmoset Vocalization
Nov 06, 2024



Marmoset, a highly vocalized primate, has become a popular animal model for studying social-communicative behavior and its underlying mechanism comparing with human infant linguistic developments. In the study of vocal communication, it is vital to know the caller identities, call contents, and vocal exchanges. Previous work of a CNN has achieved a joint model for call segmentation, classification, and caller identification for marmoset vocalizations. However, the CNN has limitations in modeling long-range acoustic patterns; the Transformer architecture that has been shown to outperform CNNs, utilizes the self-attention mechanism that efficiently segregates information parallelly over long distances and captures the global structure of marmoset vocalization. We propose using the Transformer to jointly segment and classify the marmoset calls and identify the callers for each vocalization.
A Neural Transformer Framework for Simultaneous Tasks of Segmentation, Classification, and Caller Identification of Marmoset Vocalization
Oct 30, 2024Marmoset, a highly vocalized primate, has become a popular animal model for studying social-communicative behavior and its underlying mechanism. In the study of vocal communication, it is vital to know the caller identities, call contents, and vocal exchanges. Previous work of a CNN has achieved a joint model for call segmentation, classification, and caller identification for marmoset vocalizations. However, the CNN has limitations in modeling long-range acoustic patterns; the Transformer architecture that has been shown to outperform CNNs, utilizes the self-attention mechanism that efficiently segregates information parallelly over long distances and captures the global structure of marmoset vocalization. We propose using the Transformer to jointly segment and classify the marmoset calls and identify the callers for each vocalization.
Enhancing Indonesian Automatic Speech Recognition: Evaluating Multilingual Models with Diverse Speech Variabilities
Oct 11, 2024



An ideal speech recognition model has the capability to transcribe speech accurately under various characteristics of speech signals, such as speaking style (read and spontaneous), speech context (formal and informal), and background noise conditions (clean and moderate). Building such a model requires a significant amount of training data with diverse speech characteristics. Currently, Indonesian data is dominated by read, formal, and clean speech, leading to a scarcity of Indonesian data with other speech variabilities. To develop Indonesian automatic speech recognition (ASR), we present our research on state-of-the-art speech recognition models, namely Massively Multilingual Speech (MMS) and Whisper, as well as compiling a dataset comprising Indonesian speech with variabilities to facilitate our study. We further investigate the models' predictive ability to transcribe Indonesian speech data across different variability groups. The best results were achieved by the Whisper fine-tuned model across datasets with various characteristics, as indicated by the decrease in word error rate (WER) and character error rate (CER). Moreover, we found that speaking style variability affected model performance the most.
Contrastive Feedback Mechanism for Simultaneous Speech Translation
Jul 31, 2024Recent advances in simultaneous speech translation (SST) focus on the decision policies that enable the use of offline-trained ST models for simultaneous inference. These decision policies not only control the quality-latency trade-off in SST but also mitigate the impact of unstable predictions on translation quality by delaying translation for more context or discarding these predictions through stable hypothesis detection. However, these policies often overlook the potential benefits of utilizing unstable predictions. We introduce the contrastive feedback mechanism (CFM) for SST, a novel method that leverages these unstable predictions as feedback to improve translation quality. CFM guides the system to eliminate undesired model behaviors from these predictions through a contrastive objective. The experiments on 3 state-of-the-art decision policies across 8 languages in the MuST-C v1.0 dataset show that CFM effectively improves the performance of SST.
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Jul 31, 2024The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
NAIST Simultaneous Speech Translation System for IWSLT 2024
Jun 30, 2024



This paper describes NAIST's submission to the simultaneous track of the IWSLT 2024 Evaluation Campaign: English-to-{German, Japanese, Chinese} speech-to-text translation and English-to-Japanese speech-to-speech translation. We develop a multilingual end-to-end speech-to-text translation model combining two pre-trained language models, HuBERT and mBART. We trained this model with two decoding policies, Local Agreement (LA) and AlignAtt. The submitted models employ the LA policy because it outperformed the AlignAtt policy in previous models. Our speech-to-speech translation method is a cascade of the above speech-to-text model and an incremental text-to-speech (TTS) module that incorporates a phoneme estimation model, a parallel acoustic model, and a parallel WaveGAN vocoder. We improved our incremental TTS by applying the Transformer architecture with the AlignAtt policy for the estimation model. The results show that our upgraded TTS module contributed to improving the system performance.