 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Encoding in the Context of Memristor-Based Analog Computation for Automatic Speech Recognition
Jun 11, 2026Memristors provide a new chance for resource-efficient computation of neural models for natural language processing by enabling analog execution of vector-matrix-multiplication. Yet, computations on these devices are currently subject to larger distortion, both in weight programming and execution. In this work, we identify large output values of transformed positional encodings to cause major degradation within analog-to-digital conversion (ADC) as part of memristor-based computation. By adjusting the proportion of weight and precision bits of the ADC of specific memristor layers, we reduce the degradation of the execution by ~50% relative, while keeping the estimated energy consumption stable. Additionally, we investigate scenarios where the ADC cannot be modified. In that case the degradation can be reduced by ~30% relative after removing encoding-related linear transformations.
Reproducing and Dissecting Denoising Language Models for Speech Recognition
Dec 15, 2025Denoising language models (DLMs) have been proposed as a powerful alternative to traditional language models (LMs) for automatic speech recognition (ASR), motivated by their ability to use bidirectional context and adapt to a specific ASR model's error patterns. However, the complexity of the DLM training pipeline has hindered wider investigation. This paper presents the first independent, large-scale empirical study of DLMs. We build and release a complete, reproducible pipeline to systematically investigate the impact of key design choices. We evaluate dozens of configurations across multiple axes, including various data augmentation techniques (e.g., SpecAugment, dropout, mixup), different text-to-speech systems, and multiple decoding strategies. Our comparative analysis in a common subword vocabulary setting demonstrates that DLMs outperform traditional LMs, but only after a distinct compute tipping point. While LMs are more efficient at lower budgets, DLMs scale better with longer training, mirroring behaviors observed in diffusion language models. However, we observe smaller improvements than those reported in prior character-based work, which indicates that the DLM's performance is conditional on factors such as the vocabulary. Our analysis reveals that a key factor for improving performance is to condition the DLM on richer information from the ASR's hypothesis space, rather than just a single best guess. To this end, we introduce DLM-sum, a novel method for decoding from multiple ASR hypotheses, which consistently outperforms the previously proposed DSR decoding method. We believe our findings and public pipeline provide a crucial foundation for the community to better understand, improve, and build upon this promising class of models. The code is publicly available at https://github.com/rwth-i6/2025-denoising-lm/.
Running Conventional Automatic Speech Recognition on Memristor Hardware: A Simulated Approach
May 30, 2025Memristor-based hardware offers new possibilities for energy-efficient machine learning (ML) by providing analog in-memory matrix multiplication. Current hardware prototypes cannot fit large neural networks, and related literature covers only small ML models for tasks like MNIST or single word recognition. Simulation can be used to explore how hardware properties affect larger models, but existing software assumes simplified hardware. We propose a PyTorch-based library based on "Synaptogen" to simulate neural network execution with accurately captured memristor hardware properties. For the first time, we show how an ML system with millions of parameters would behave on memristor hardware, using a Conformer trained on the speech recognition task TED-LIUMv2 as example. With adjusted quantization-aware training, we limit the relative degradation in word error rate to 25% when using a 3-bit weight precision to execute linear operations via simulated analog computation.
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Jul 31, 2024The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures
Jul 25, 2024In this work we evaluate the utility of synthetic data for training automatic speech recognition (ASR). We use the ASR training data to train a text-to-speech (TTS) system similar to FastSpeech-2. With this TTS we reproduce the original training data, training ASR systems solely on synthetic data. For ASR, we use three different architectures, attention-based encoder-decoder, hybrid deep neural network hidden Markov model and a Gaussian mixture hidden Markov model, showing the different sensitivity of the models to synthetic data generation. In order to extend previous work, we present a number of ablation studies on the effectiveness of synthetic vs. real training data for ASR. In particular we focus on how the gap between training on synthetic and real data changes by varying the speaker embedding or by scaling the model size. For the latter we show that the TTS models generalize well, even when training scores indicate overfitting.
On the Relevance of Phoneme Duration Variability of Synthesized Training Data for Automatic Speech Recognition
Oct 12, 2023



Synthetic data generated by text-to-speech (TTS) systems can be used to improve automatic speech recognition (ASR) systems in low-resource or domain mismatch tasks. It has been shown that TTS-generated outputs still do not have the same qualities as real data. In this work we focus on the temporal structure of synthetic data and its relation to ASR training. By using a novel oracle setup we show how much the degradation of synthetic data quality is influenced by duration modeling in non-autoregressive (NAR) TTS. To get reference phoneme durations we use two common alignment methods, a hidden Markov Gaussian-mixture model (HMM-GMM) aligner and a neural connectionist temporal classification (CTC) aligner. Using a simple algorithm based on random walks we shift phoneme duration distributions of the TTS system closer to real durations, resulting in an improvement of an ASR system using synthetic data in a semi-supervised setting.
Take the Hint: Improving Arabic Diacritization with Partially-Diacritized Text
Jun 06, 2023


Automatic Arabic diacritization is useful in many applications, ranging from reading support for language learners to accurate pronunciation predictor for downstream tasks like speech synthesis. While most of the previous works focused on models that operate on raw non-diacritized text, production systems can gain accuracy by first letting humans partly annotate ambiguous words. In this paper, we propose 2SDiac, a multi-source model that can effectively support optional diacritics in input to inform all predictions. We also introduce Guided Learning, a training scheme to leverage given diacritics in input with different levels of random masking. We show that the provided hints during test affect more output positions than those annotated. Moreover, experiments on two common benchmarks show that our approach i) greatly outperforms the baseline also when evaluated on non-diacritized text; and ii) achieves state-of-the-art results while reducing the parameter count by over 60%.
Comparing the Benefit of Synthetic Training Data for Various Automatic Speech Recognition Architectures
Apr 12, 2021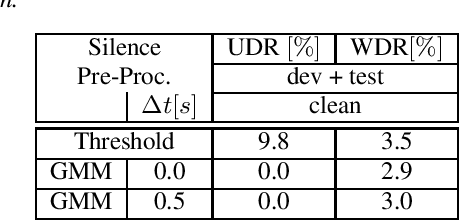
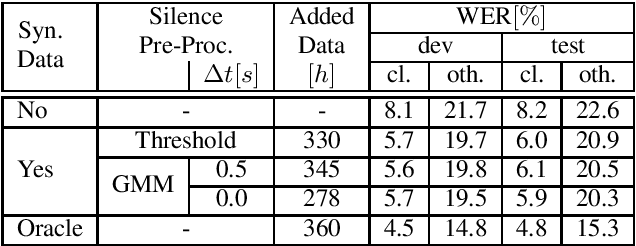
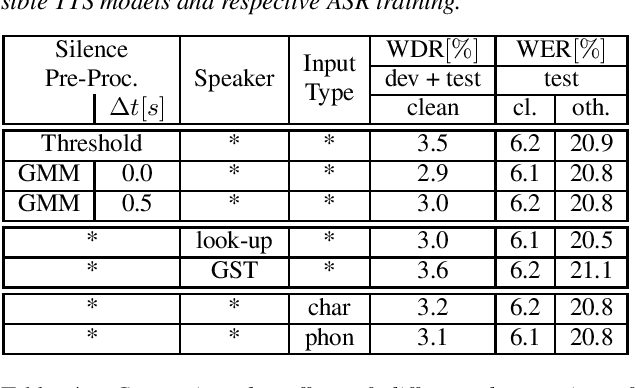
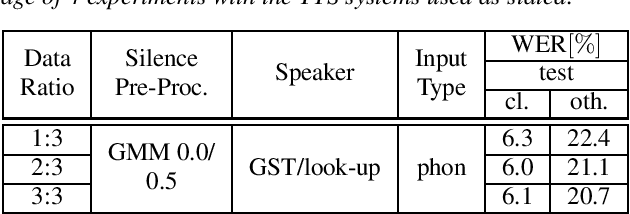
Recent publications on automatic-speech-recognition (ASR) have a strong focus on attention encoder-decoder (AED) architectures which work well for large datasets, but tend to overfit when applied in low resource scenarios. One solution to tackle this issue is to generate synthetic data with a trained text-to-speech system (TTS) if additional text is available. This was successfully applied in many publications with AED systems. We present a novel approach of silence correction in the data pre-processing for TTS systems which increases the robustness when training on corpora targeted for ASR applications. In this work we do not only show the successful application of synthetic data for AED systems, but also test the same method on a highly optimized state-of-the-art Hybrid ASR system and a competitive monophone based system using connectionist-temporal-classification (CTC). We show that for the later systems the addition of synthetic data only has a minor effect, but they still outperform the AED systems by a large margin on LibriSpeech-100h. We achieve a final word-error-rate of 3.3%/10.0% with a Hybrid system on the clean/noisy test-sets, surpassing any previous state-of-the-art systems that do not include unlabeled audio data.
Generating Synthetic Audio Data for Attention-Based Speech Recognition Systems
Dec 19, 2019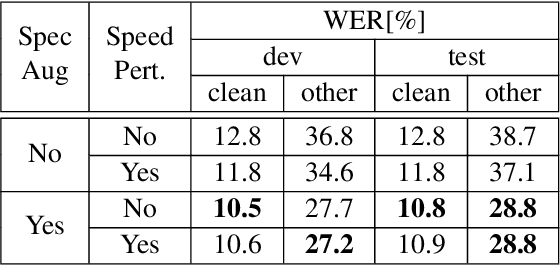
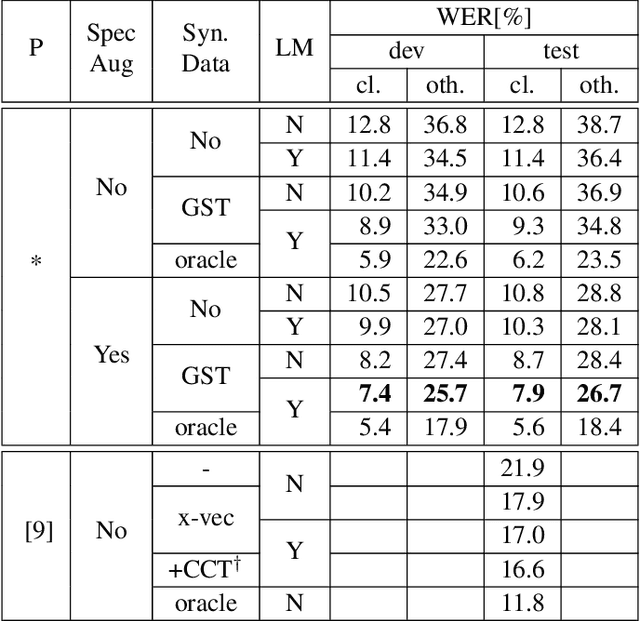
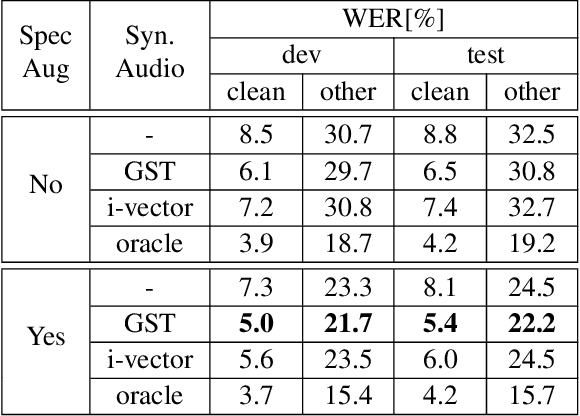
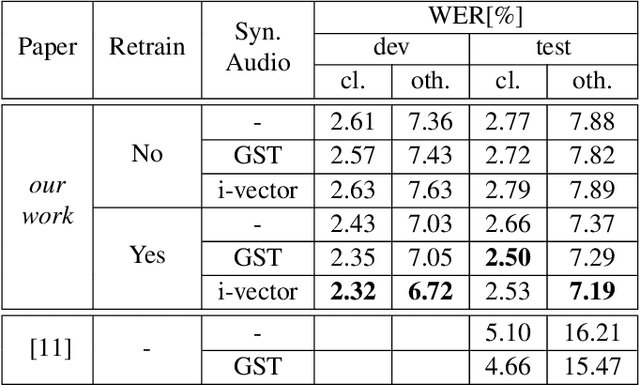
Recent advances in text-to-speech (TTS) led to the development of flexible multi-speaker end-to-end TTS systems. We extend state-of-the-art attention-based automatic speech recognition (ASR) systems with synthetic audio generated by a TTS system trained only on the ASR corpora itself. ASR and TTS systems are built separately to show that text-only data can be used to enhance existing end-to-end ASR systems without the necessity of parameter or architecture changes. We compare our method with language model integration of the same text data and with simple data augmentation methods like SpecAugment and show that performance improvements are mostly independent. We achieve improvements of up to 33% relative in word-error-rate (WER) over a strong baseline with data-augmentation in a low-resource environment (LibriSpeech-100h), closing the gap to a comparable oracle experiment by more than 50\%. We also show improvements of up to 5% relative WER over our most recent ASR baseline on LibriSpeech-960h.
Learning Bilingual Sentence Embeddings via Autoencoding and Computing Similarities with a Multilayer Perceptron
Jun 05, 2019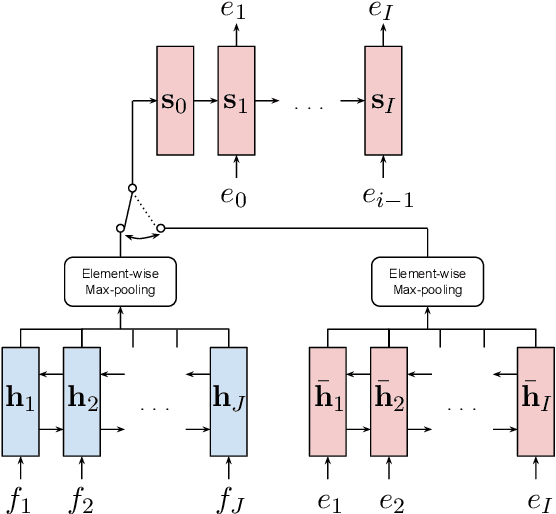
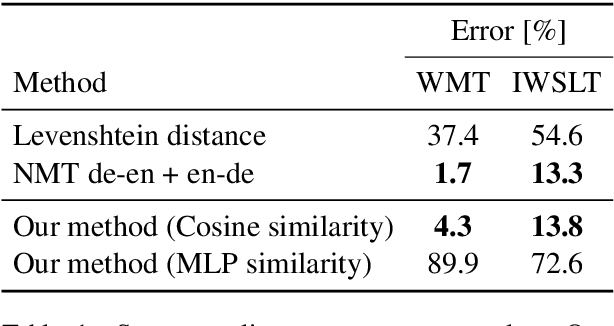
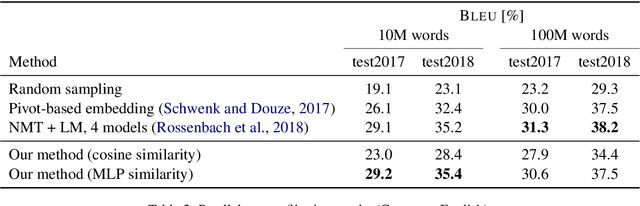
We propose a novel model architecture and training algorithm to learn bilingual sentence embeddings from a combination of parallel and monolingual data. Our method connects autoencoding and neural machine translation to force the source and target sentence embeddings to share the same space without the help of a pivot language or an additional transformation. We train a multilayer perceptron on top of the sentence embeddings to extract good bilingual sentence pairs from nonparallel or noisy parallel data. Our approach shows promising performance on sentence alignment recovery and the WMT 2018 parallel corpus filtering tasks with only a single model.