 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Drives the Use of Metaphorical Language? Negative Insights from Abstractness, Affect, Discourse Coherence and Contextualized Word Representations
May 23, 2022
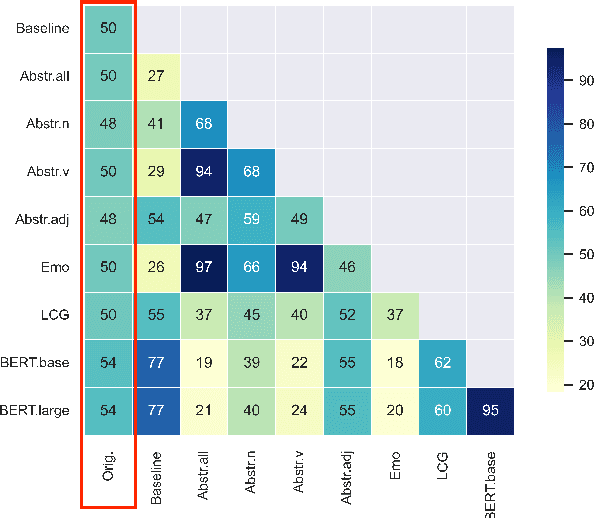
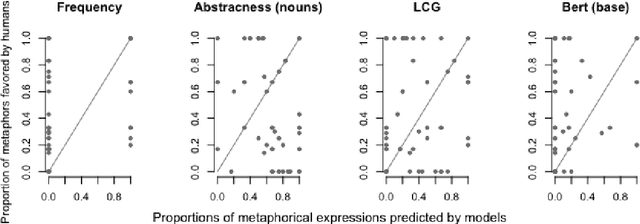
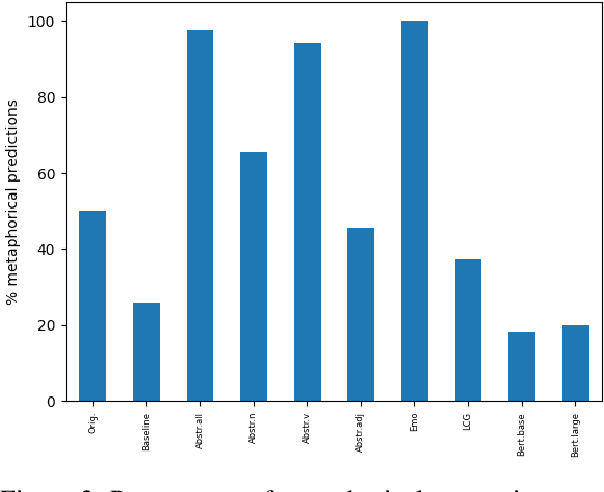
Given a specific discourse, which discourse properties trigger the use of metaphorical language, rather than using literal alternatives? For example, what drives people to say "grasp the meaning" rather than "understand the meaning" within a specific context? Many NLP approaches to metaphorical language rely on cognitive and (psycho-)linguistic insights and have successfully defined models of discourse coherence, abstractness and affect. In this work, we build five simple models relying on established cognitive and linguistic properties -- frequency, abstractness, affect, discourse coherence and contextualized word representations -- to predict the use of a metaphorical vs. synonymous literal expression in context. By comparing the models' outputs to human judgments, our study indicates that our selected properties are not sufficient to systematically explain metaphorical vs. literal language choices.
Features of Perceived Metaphoricity on the Discourse Level: Abstractness and Emotionality
May 18, 2022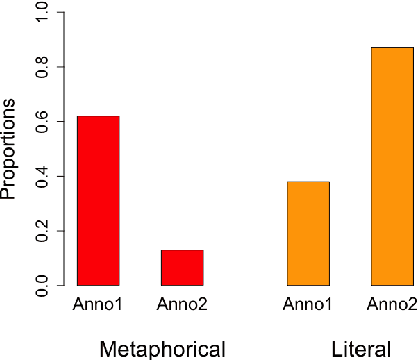
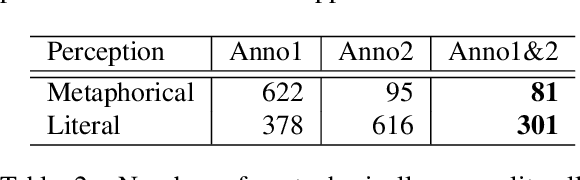
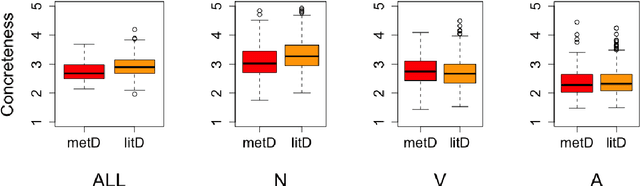
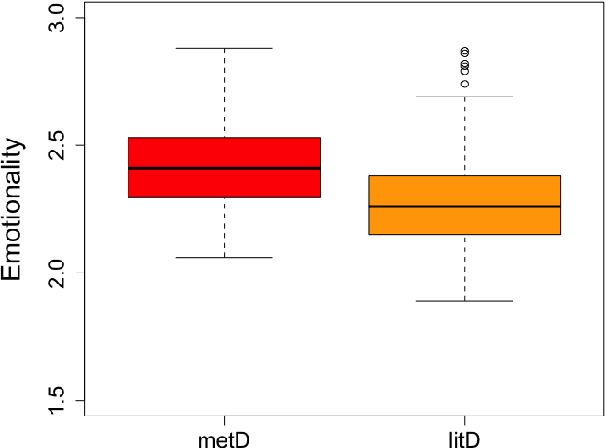
Research on metaphorical language has shown ties between abstractness and emotionality with regard to metaphoricity; prior work is however limited to the word and sentence levels, and up to date there is no empirical study establishing the extent to which this is also true on the discourse level. This paper explores which textual and perceptual features human annotators perceive as important for the metaphoricity of discourses and expressions, and addresses two research questions more specifically. First, is a metaphorically-perceived discourse more abstract and more emotional in comparison to a literally-perceived discourse? Second, is a metaphorical expression preceded by a more metaphorical/abstract/emotional context than a synonymous literal alternative? We used a dataset of 1,000 corpus-extracted discourses for which crowdsourced annotators (1) provided judgements on whether they perceived the discourses as more metaphorical or more literal, and (2) systematically listed lexical terms which triggered their decisions in (1). Our results indicate that metaphorical discourses are more emotional and to a certain extent more abstract than literal discourses. However, neither the metaphoricity nor the abstractness and emotionality of the preceding discourse seem to play a role in triggering the choice between synonymous metaphorical vs. literal expressions. Our dataset is available at https://www.ims.uni-stuttgart.de/data/discourse-met-lit.
Lexical Semantic Change Discovery
Jun 06, 2021

While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
More than just Frequency? Demasking Unsupervised Hypernymy Prediction Methods
May 31, 2021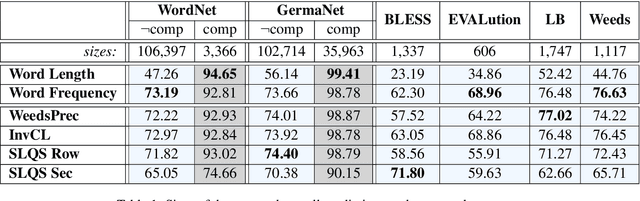

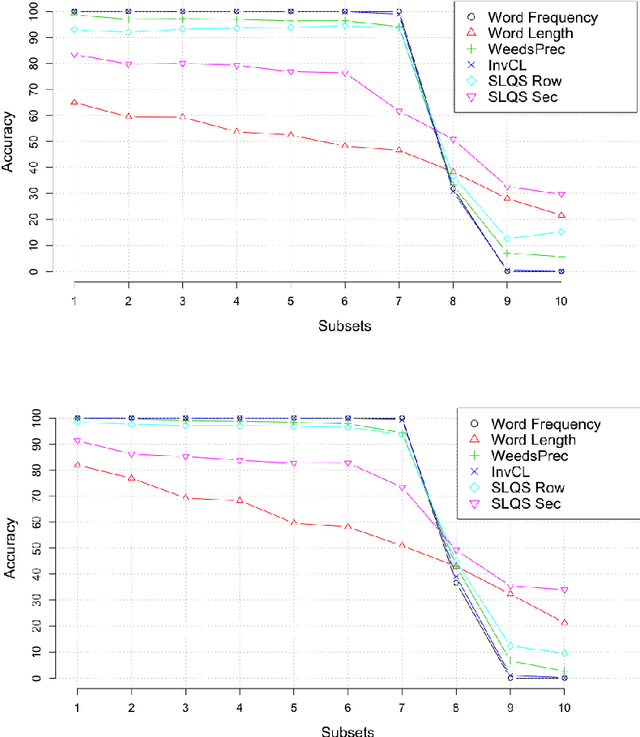
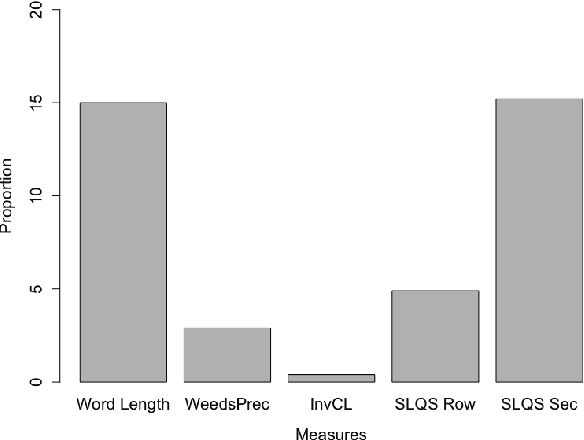
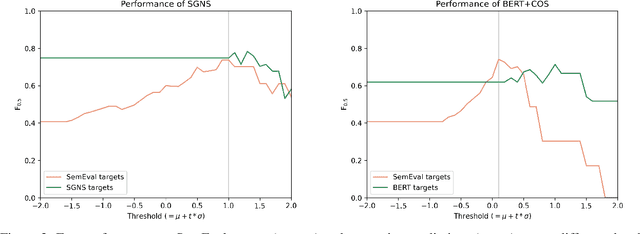
This paper presents a comparison of unsupervised methods of hypernymy prediction (i.e., to predict which word in a pair of words such as fish-cod is the hypernym and which the hyponym). Most importantly, we demonstrate across datasets for English and for German that the predictions of three methods (WeedsPrec, invCL, SLQS Row) strongly overlap and are highly correlated with frequency-based predictions. In contrast, the second-order method SLQS shows an overall lower accuracy but makes correct predictions where the others go wrong. Our study once more confirms the general need to check the frequency bias of a computational method in order to identify frequency-(un)related effects.
Explaining and Improving BERT Performance on Lexical Semantic Change Detection
Mar 12, 2021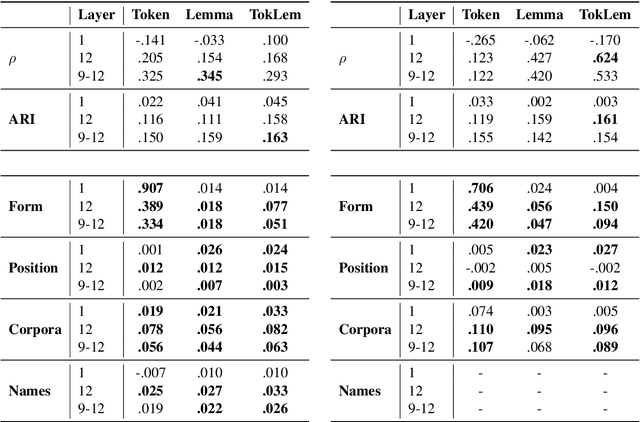
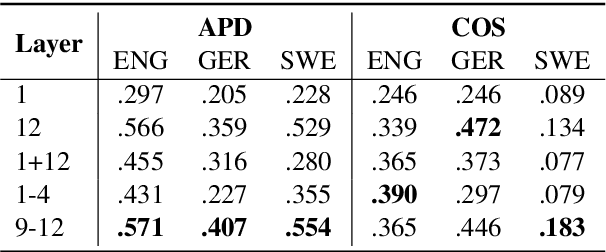
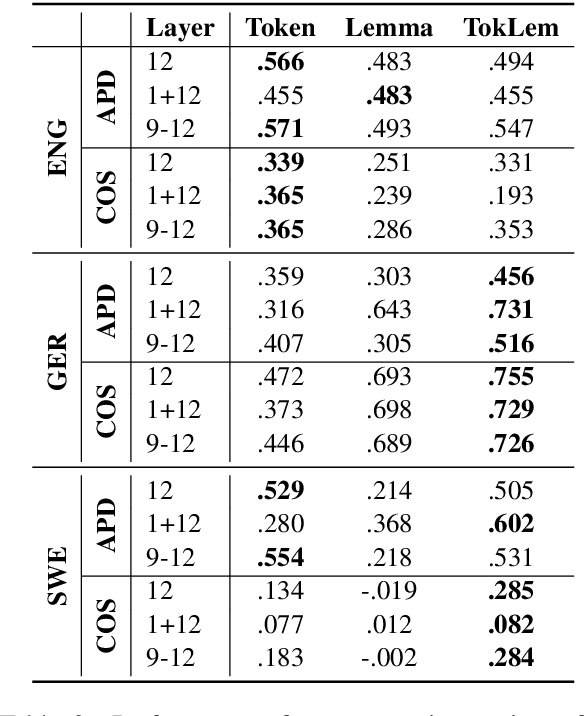
Type- and token-based embedding architectures are still competing in lexical semantic change detection. The recent success of type-based models in SemEval-2020 Task 1 has raised the question why the success of token-based models on a variety of other NLP tasks does not translate to our field. We investigate the influence of a range of variables on clusterings of BERT vectors and show that its low performance is largely due to orthographic information on the target word, which is encoded even in the higher layers of BERT representations. By reducing the influence of orthography we considerably improve BERT's performance.
CL-IMS @ DIACR-Ita: Volente o Nolente: BERT does not outperform SGNS on Semantic Change Detection
Dec 03, 2020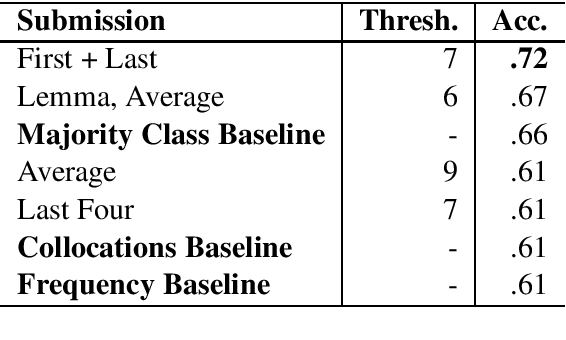
We present the results of our participation in the DIACR-Ita shared task on lexical semantic change detection for Italian. We exploit Average Pairwise Distance of token-based BERT embeddings between time points and rank 5 (of 8) in the official ranking with an accuracy of $.72$. While we tune parameters on the English data set of SemEval-2020 Task 1 and reach high performance, this does not translate to the Italian DIACR-Ita data set. Our results show that we do not manage to find robust ways to exploit BERT embeddings in lexical semantic change detection.
OP-IMS @ DIACR-Ita: Back to the Roots: SGNS+OP+CD still rocks Semantic Change Detection
Nov 06, 2020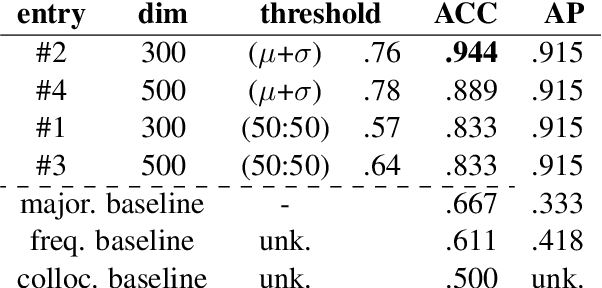
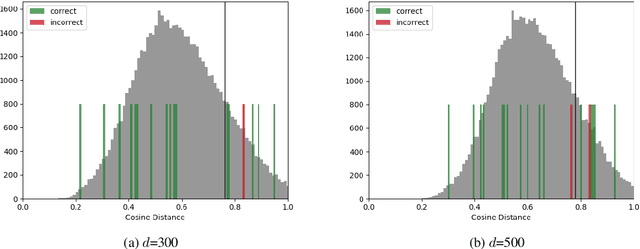
We present the results of our participation in the DIACR-Ita shared task on lexical semantic change detection for Italian. We exploit one of the earliest and most influential semantic change detection models based on Skip-Gram with Negative Sampling, Orthogonal Procrustes alignment and Cosine Distance and obtain the winning submission of the shared task with near to perfect accuracy .94. Our results once more indicate that, within the present task setup in lexical semantic change detection, the traditional type-based approaches yield excellent performance.
IMS at SemEval-2020 Task 1: How low can you go? Dimensionality in Lexical Semantic Change Detection
Aug 07, 2020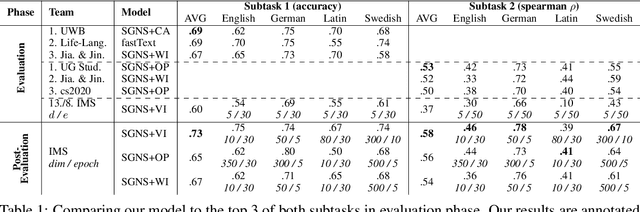
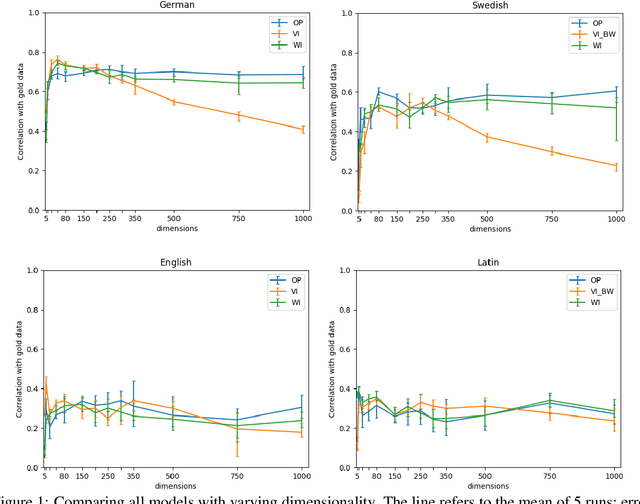
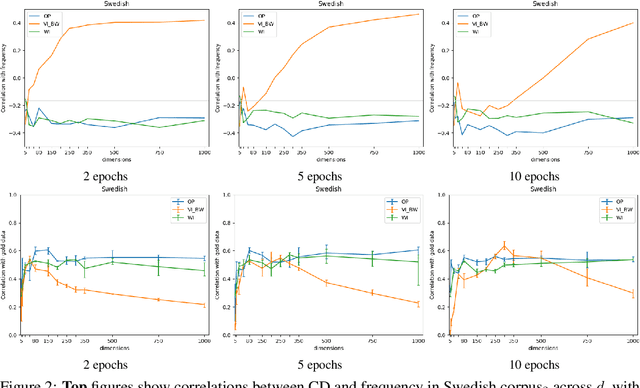

We present the results of our system for SemEval-2020 Task 1 that exploits a commonly used lexical semantic change detection model based on Skip-Gram with Negative Sampling. Our system focuses on Vector Initialization (VI) alignment, compares VI to the currently top-ranking models for Subtask 2 and demonstrates that these can be outperformed if we optimize VI dimensionality. We demonstrate that differences in performance can largely be attributed to model-specific sources of noise, and we reveal a strong relationship between dimensionality and frequency-induced noise in VI alignment. Our results suggest that lexical semantic change models integrating vector space alignment should pay more attention to the role of the dimensionality parameter.
Simulating Lexical Semantic Change from Sense-Annotated Data
Jan 09, 2020



We present a novel procedure to simulate lexical semantic change from synchronic sense-annotated data, and demonstrate its usefulness for assessing lexical semantic change detection models. The induced dataset represents a stronger correspondence to empirically observed lexical semantic change than previous synthetic datasets, because it exploits the intimate relationship between synchronic polysemy and diachronic change. We publish the data and provide the first large-scale evaluation gold standard for LSC detection models.
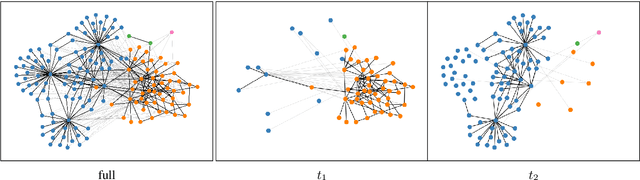
You Shall Know a User by the Company It Keeps: Dynamic Representations for Social Media Users in NLP
Sep 01, 2019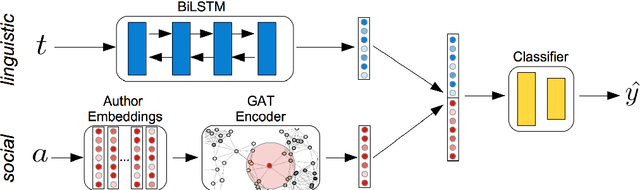
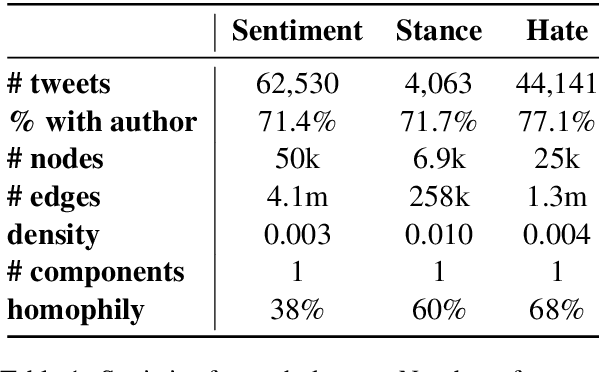
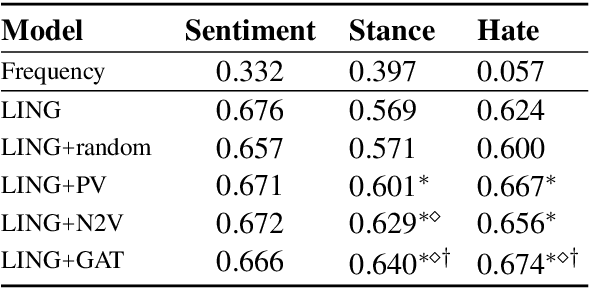
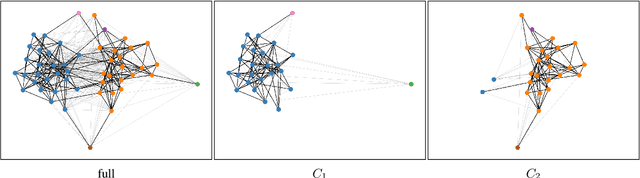
Information about individuals can help to better understand what they say, particularly in social media where texts are short. Current approaches to modelling social media users pay attention to their social connections, but exploit this information in a static way, treating all connections uniformly. This ignores the fact, well known in sociolinguistics, that an individual may be part of several communities which are not equally relevant in all communicative situations. We present a model based on Graph Attention Networks that captures this observation. It dynamically explores the social graph of a user, computes a user representation given the most relevant connections for a target task, and combines it with linguistic information to make a prediction. We apply our model to three different tasks, evaluate it against alternative models, and analyse the results extensively, showing that it significantly outperforms other current methods.