 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRi: Low-Rank Distillation for Implicit Reasoning
Jun 03, 2026Implicit chain-of-thought (iCoT) methods aim to internalize reasoning in large language models, but often underperform explicit CoT prompting. We empirically find that hidden-state reasoning trajectories exhibit low-rank structure. Motivated by this observation, we propose a low-rank distillation framework that transfers reasoning by aligning teacher and student trajectories in a shared low-rank tensor subspace using first- and second-order statistics. The resulting formulation captures the global structure of reasoning while supporting a compact latent reasoning process. We evaluate the method across multiple model families, including LLaMA and Qwen, at different scales on mathematical reasoning benchmarks. Our approach consistently improves performance, especially on challenging multi-step tasks, approaching explicit CoT accuracy and outperforming prior iCoT distillation methods.
FLAT-LLM: Fine-grained Low-rank Activation Space Transformation for Large Language Model Compression
May 29, 2025Large Language Models (LLMs) have enabled remarkable progress in natural language processing, yet their high computational and memory demands pose challenges for deployment in resource-constrained environments. Although recent low-rank decomposition methods offer a promising path for structural compression, they often suffer from accuracy degradation, expensive calibration procedures, and result in inefficient model architectures that hinder real-world inference speedups. In this paper, we propose FLAT-LLM, a fast and accurate, training-free structural compression method based on fine-grained low-rank transformations in the activation space. Specifically, we reduce the hidden dimension by transforming the weights using truncated eigenvectors computed via head-wise Principal Component Analysis (PCA), and employ an importance-based metric to adaptively allocate ranks across decoders. FLAT-LLM achieves efficient and effective weight compression without recovery fine-tuning, which could complete the calibration within a few minutes. Evaluated across 4 models and 11 datasets, FLAT-LLM outperforms structural pruning baselines in generalization and downstream performance, while delivering inference speedups over decomposition-based methods.
Saten: Sparse Augmented Tensor Networks for Post-Training Compression of Large Language Models
May 20, 2025The efficient implementation of large language models (LLMs) is crucial for deployment on resource-constrained devices. Low-rank tensor compression techniques, such as tensor-train (TT) networks, have been widely studied for over-parameterized neural networks. However, their applications to compress pre-trained large language models (LLMs) for downstream tasks (post-training) remains challenging due to the high-rank nature of pre-trained LLMs and the lack of access to pretraining data. In this study, we investigate low-rank tensorized LLMs during fine-tuning and propose sparse augmented tensor networks (Saten) to enhance their performance. The proposed Saten framework enables full model compression. Experimental results demonstrate that Saten enhances both accuracy and compression efficiency in tensorized language models, achieving state-of-the-art performance.
Partial Tensorized Transformers for Natural Language Processing
Oct 30, 2023The transformer architecture has revolutionized Natural Language Processing (NLP) and other machine-learning tasks, due to its unprecedented accuracy. However, their extensive memory and parameter requirements often hinder their practical applications. In this work, we study the effect of tensor-train decomposition to improve the accuracy and compress transformer vision-language neural networks, namely BERT and ViT. We focus both on embedding-layer compression and partial tensorization of neural networks (PTNN) through an algorithmic approach. Our novel PTNN approach significantly improves the accuracy of existing models by up to 5%, all without the need for post-training adjustments, breaking new ground in the field of tensor decomposition.
Tensor Shape Search for Optimum Data Compression
May 21, 2022
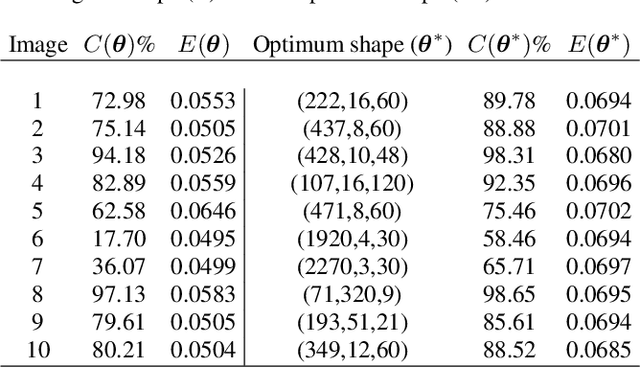
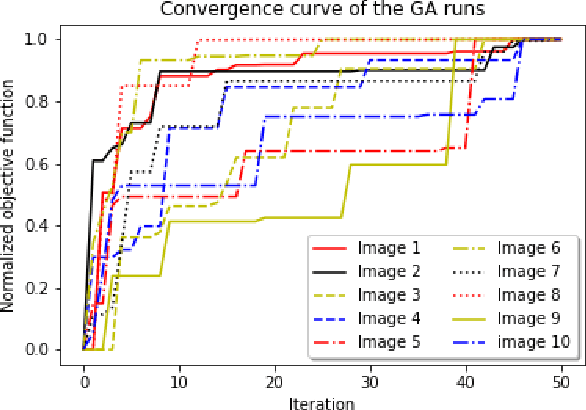
Various tensor decomposition methods have been proposed for data compression. In real world applications of the tensor decomposition, selecting the tensor shape for the given data poses a challenge and the shape of the tensor may affect the error and the compression ratio. In this work, we study the effect of the tensor shape on the tensor decomposition and propose an optimization model to find an optimum shape for the tensor train (TT) decomposition. The proposed optimization model maximizes the compression ratio of the TT decomposition given an error bound. We implement a genetic algorithm (GA) linked with the TT-SVD algorithm to solve the optimization model. We apply the proposed method for the compression of RGB images. The results demonstrate the effectiveness of the proposed evolutionary tensor shape search for the TT decomposition.