 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Efficient Confidence Score for Grading Whole Slide Images
Mar 08, 2023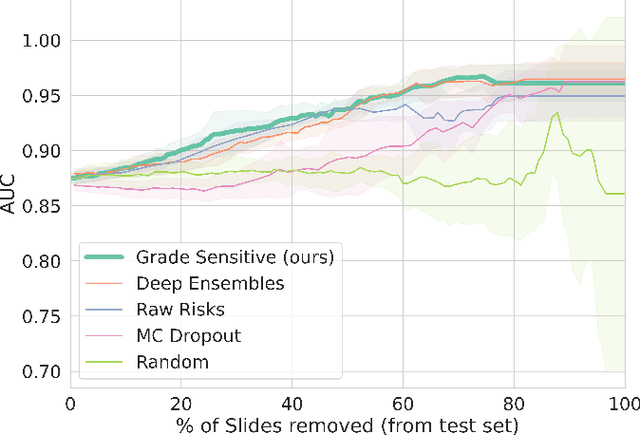

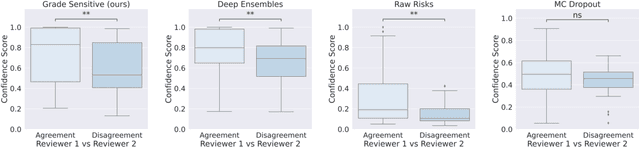

Grading precancerous lesions on whole slide images is a challenging task: the continuous space of morphological phenotypes makes clear-cut decisions between different grades often difficult, leading to low inter- and intra-rater agreements. More and more Artificial Intelligence (AI) algorithms are developed to help pathologists perform and standardize their diagnosis. However, those models can render their prediction without consideration of the ambiguity of the classes and can fail without notice which prevent their wider acceptance in a clinical context. In this paper, we propose a new score to measure the confidence of AI models in grading tasks. Our confidence score is specifically adapted to ordinal output variables, is versatile and does not require extra training or additional inferences nor particular architecture changes. Comparison to other popular techniques such as Monte Carlo Dropout and deep ensembles shows that our method provides state-of-the art results, while being simpler, more versatile and less computationally intensive. The score is also easily interpretable and consistent with real life hesitations of pathologists. We show that the score is capable of accurately identifying mispredicted slides and that accuracy for high confidence decisions is significantly higher than for low-confidence decisions (gap in AUC of 17.1% on the test set). We believe that the proposed confidence score could be leveraged by pathologists directly in their workflow and assist them on difficult tasks such as grading precancerous lesions.
Recommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022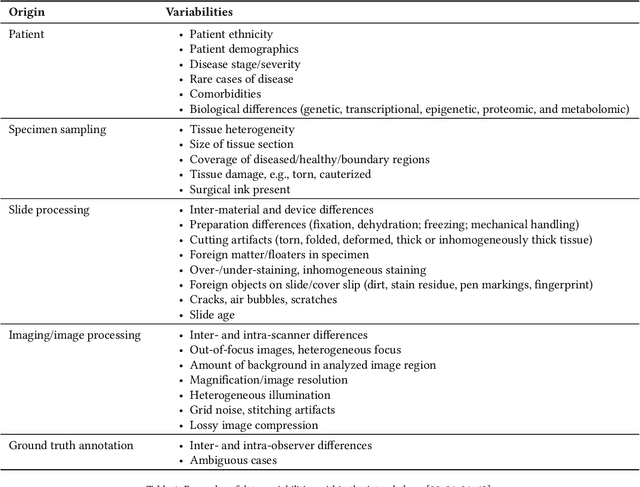

Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.