 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Recognition to Cognition: Visual Commonsense Reasoning
Nov 27, 2018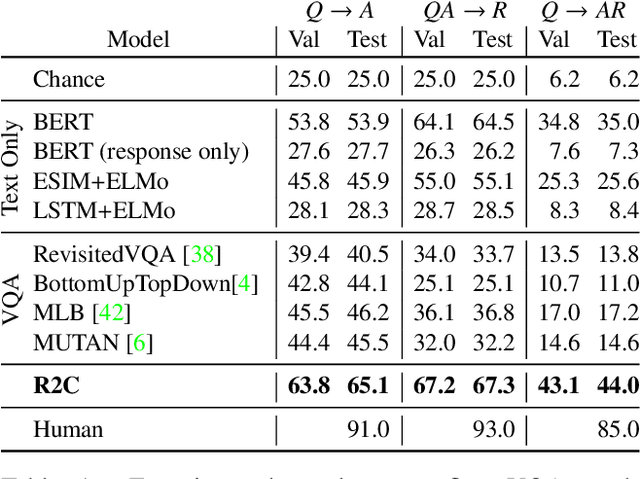
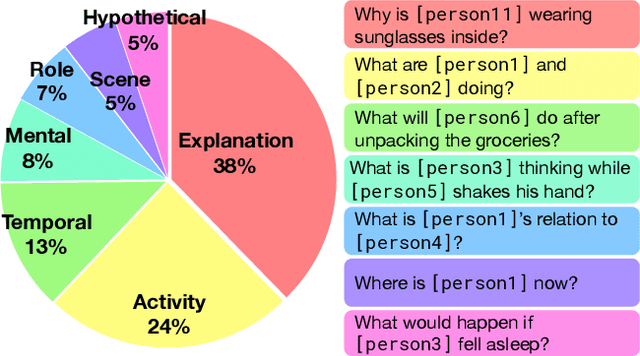
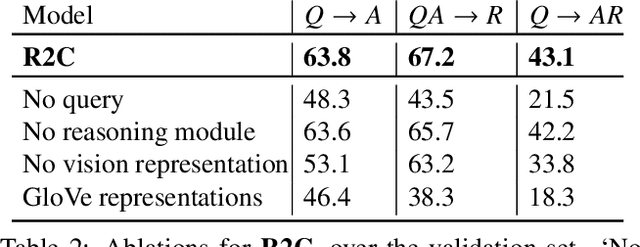

Visual understanding goes well beyond object recognition. With one glance at an image, we can effortlessly imagine the world beyond the pixels: for instance, we can infer people's actions, goals, and mental states. While this task is easy for humans, it is tremendously difficult for today's vision systems, requiring higher-order cognition and commonsense reasoning about the world. In this paper, we formalize this task as Visual Commonsense Reasoning. In addition to answering challenging visual questions expressed in natural language, a model must provide a rationale explaining why its answer is true. We introduce a new dataset, VCR, consisting of 290k multiple choice QA problems derived from 110k movie scenes. The key recipe to generating non-trivial and high-quality problems at scale is Adversarial Matching, a new approach to transform rich annotations into multiple choice questions with minimal bias. To move towards cognition-level image understanding, we present a new reasoning engine, called Recognition to Cognition Networks (R2C), that models the necessary layered inferences for grounding, contextualization, and reasoning. Experimental results show that while humans find VCR easy (over 90% accuracy), state-of-the-art models struggle (~45%). Our R2C helps narrow this gap (~65%); still, the challenge is far from solved, and we provide analysis that suggests avenues for future work.
SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference
Aug 16, 2018
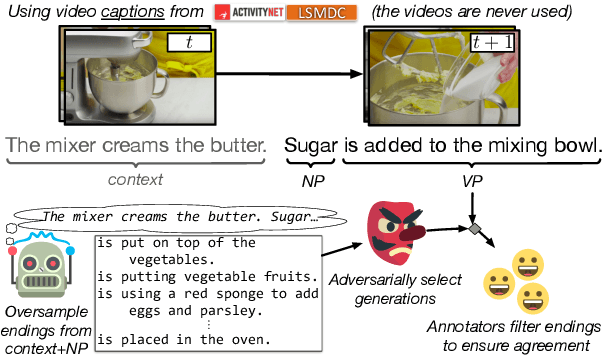
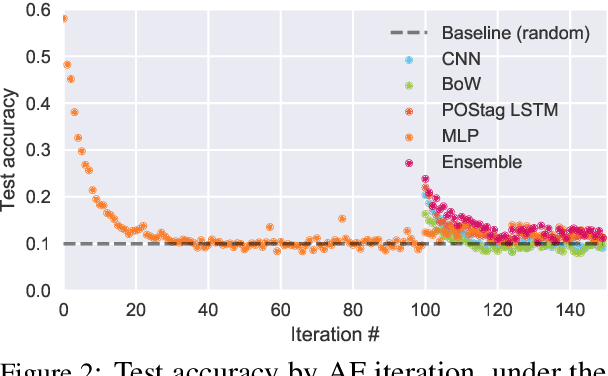
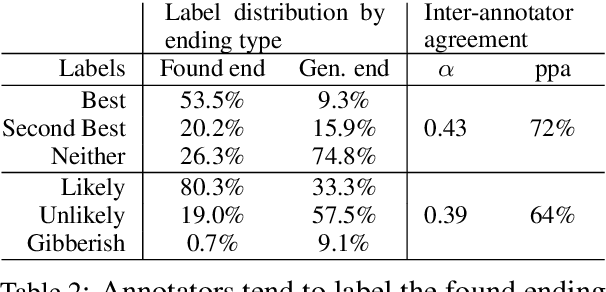
Given a partial description like "she opened the hood of the car," humans can reason about the situation and anticipate what might come next ("then, she examined the engine"). In this paper, we introduce the task of grounded commonsense inference, unifying natural language inference and commonsense reasoning. We present SWAG, a new dataset with 113k multiple choice questions about a rich spectrum of grounded situations. To address the recurring challenges of the annotation artifacts and human biases found in many existing datasets, we propose Adversarial Filtering (AF), a novel procedure that constructs a de-biased dataset by iteratively training an ensemble of stylistic classifiers, and using them to filter the data. To account for the aggressive adversarial filtering, we use state-of-the-art language models to massively oversample a diverse set of potential counterfactuals. Empirical results demonstrate that while humans can solve the resulting inference problems with high accuracy (88%), various competitive models struggle on our task. We provide comprehensive analysis that indicates significant opportunities for future research.
Neural Motifs: Scene Graph Parsing with Global Context
Mar 29, 2018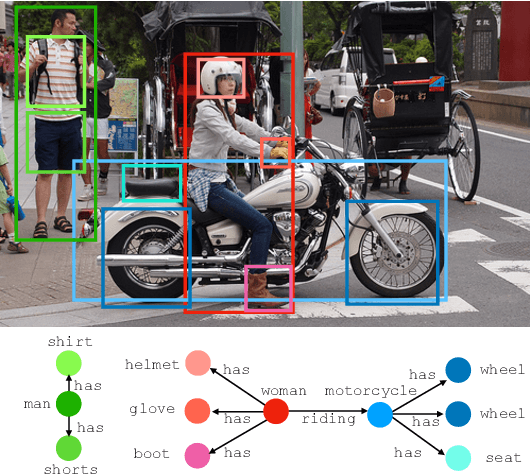
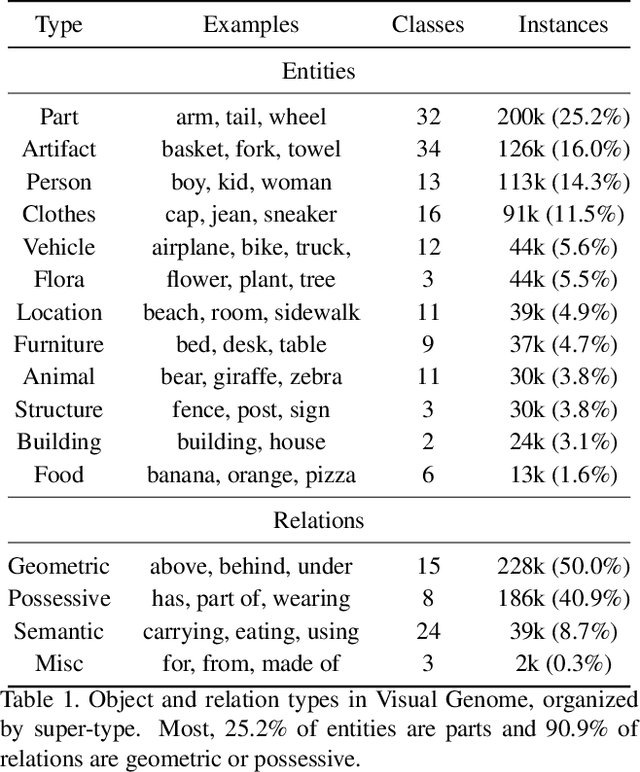
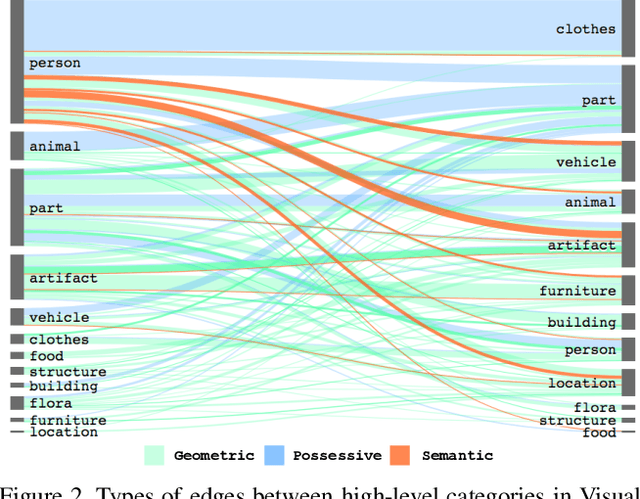
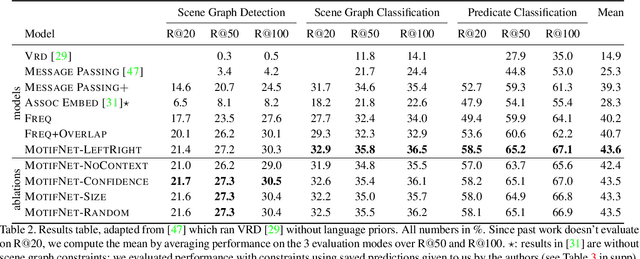
We investigate the problem of producing structured graph representations of visual scenes. Our work analyzes the role of motifs: regularly appearing substructures in scene graphs. We present new quantitative insights on such repeated structures in the Visual Genome dataset. Our analysis shows that object labels are highly predictive of relation labels but not vice-versa. We also find that there are recurring patterns even in larger subgraphs: more than 50% of graphs contain motifs involving at least two relations. Our analysis motivates a new baseline: given object detections, predict the most frequent relation between object pairs with the given labels, as seen in the training set. This baseline improves on the previous state-of-the-art by an average of 3.6% relative improvement across evaluation settings. We then introduce Stacked Motif Networks, a new architecture designed to capture higher order motifs in scene graphs that further improves over our strong baseline by an average 7.1% relative gain. Our code is available at github.com/rowanz/neural-motifs.
Zero-Shot Activity Recognition with Verb Attribute Induction
Sep 02, 2017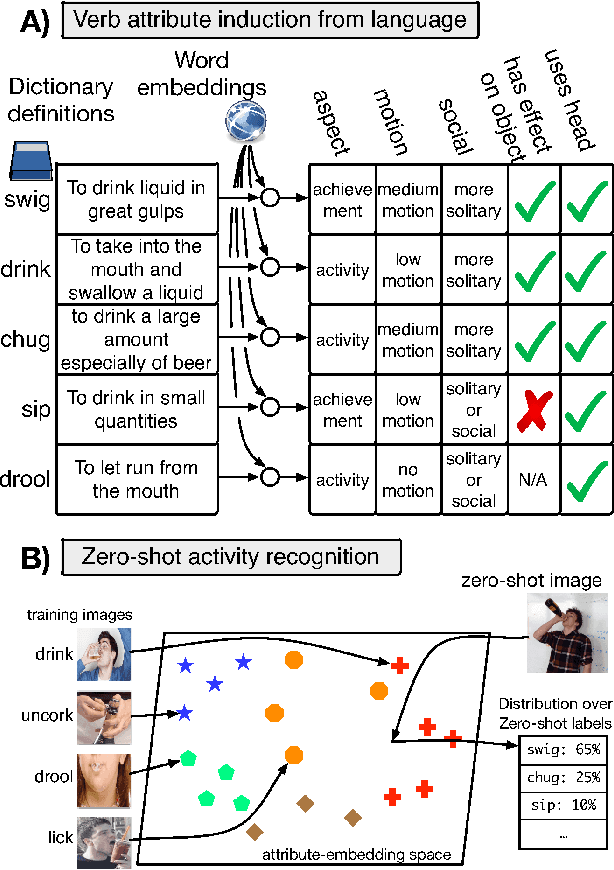
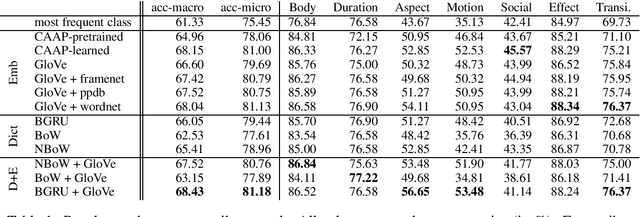
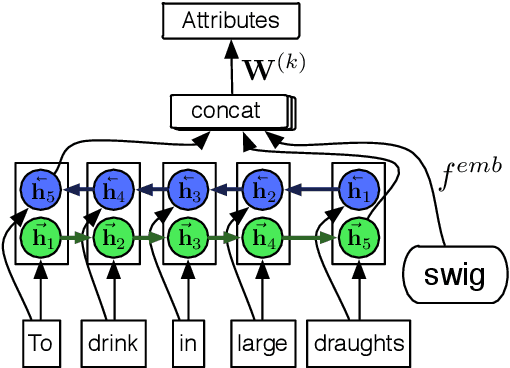
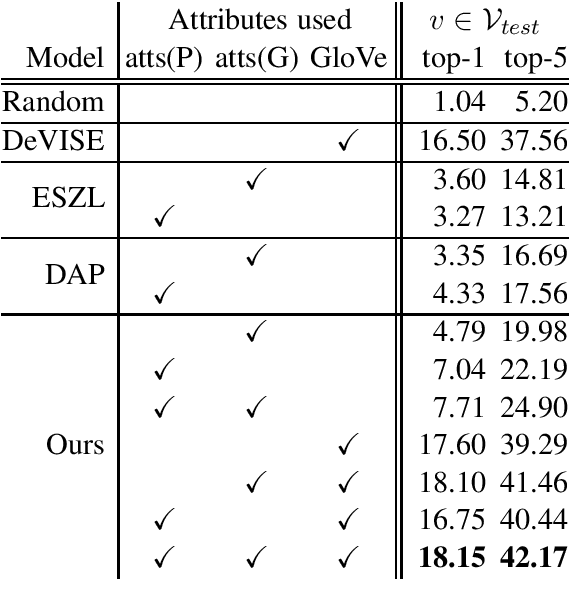
In this paper, we investigate large-scale zero-shot activity recognition by modeling the visual and linguistic attributes of action verbs. For example, the verb "salute" has several properties, such as being a light movement, a social act, and short in duration. We use these attributes as the internal mapping between visual and textual representations to reason about a previously unseen action. In contrast to much prior work that assumes access to gold standard attributes for zero-shot classes and focuses primarily on object attributes, our model uniquely learns to infer action attributes from dictionary definitions and distributed word representations. Experimental results confirm that action attributes inferred from language can provide a predictive signal for zero-shot prediction of previously unseen activities.
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
Aug 12, 2016
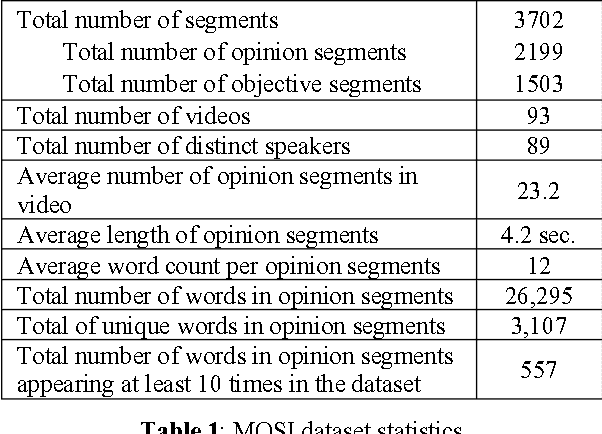
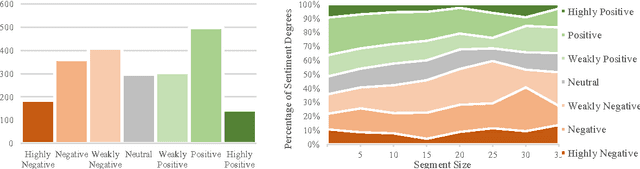
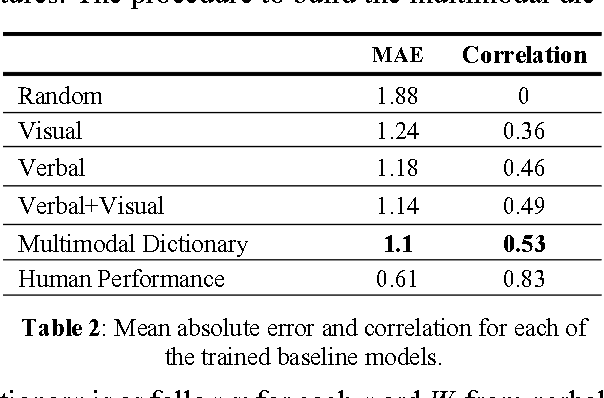
People are sharing their opinions, stories and reviews through online video sharing websites every day. Studying sentiment and subjectivity in these opinion videos is experiencing a growing attention from academia and industry. While sentiment analysis has been successful for text, it is an understudied research question for videos and multimedia content. The biggest setbacks for studies in this direction are lack of a proper dataset, methodology, baselines and statistical analysis of how information from different modality sources relate to each other. This paper introduces to the scientific community the first opinion-level annotated corpus of sentiment and subjectivity analysis in online videos called Multimodal Opinion-level Sentiment Intensity dataset (MOSI). The dataset is rigorously annotated with labels for subjectivity, sentiment intensity, per-frame and per-opinion annotated visual features, and per-milliseconds annotated audio features. Furthermore, we present baselines for future studies in this direction as well as a new multimodal fusion approach that jointly models spoken words and visual gestures.
* Accepted as Journal Publication in IEEE Intelligent Systems