 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Preprocessing and Memristor Dynamics in Reservoir Computing for Image Classification
Apr 23, 2026Reservoir computing (RC) is an emerging recurrent neural network architecture that has attracted growing attention for its low training cost and modest hardware requirements. Memristor-based circuits are particularly promising for RC, as their intrinsic dynamics can reduce network size and parameter overhead in tasks such as time-series prediction and image recognition. Although RC has been demonstrated with several memristive devices, a comprehensive evaluation of device-level requirements remains limited. In this paper, we analyze and explain the operation of a parallel delayed feedback network (PDFN) RC architecture with volatile memristors, focusing on how device characteristics -- such as decay rate, quantization, and variability -- affect reservoir performance. We further discuss strategies to improve data representation in the reservoir using preprocessing methods and suggest potential improvements. The proposed approach achieves 95.89% classification accuracy on MNIST, comparable with the best reported memristor-based RC implementations. Furthermore, the method maintains high robustness under 20% device variability, achieving an accuracy of up to 94.2%. These results demonstrate that volatile memristors can support reliable spatio-temporal information processing and reinforce their potential as key building blocks for compact, high-speed, and energy-efficient neuromorphic computing systems.
Preprocessing Methods for Memristive Reservoir Computing for Image Recognition
Jun 05, 2025



Reservoir computing (RC) has attracted attention as an efficient recurrent neural network architecture due to its simplified training, requiring only its last perceptron readout layer to be trained. When implemented with memristors, RC systems benefit from their dynamic properties, which make them ideal for reservoir construction. However, achieving high performance in memristor-based RC remains challenging, as it critically depends on the input preprocessing method and reservoir size. Despite growing interest, a comprehensive evaluation that quantifies the impact of these factors is still lacking. This paper systematically compares various preprocessing methods for memristive RC systems, assessing their effects on accuracy and energy consumption. We also propose a parity-based preprocessing method that improves accuracy by 2-6% while requiring only a modest increase in device count compared to other methods. Our findings highlight the importance of informed preprocessing strategies to improve the efficiency and scalability of memristive RC systems.
Efficient Training of the Memristive Deep Belief Net Immune to Non-Idealities of the Synaptic Devices
Mar 15, 2022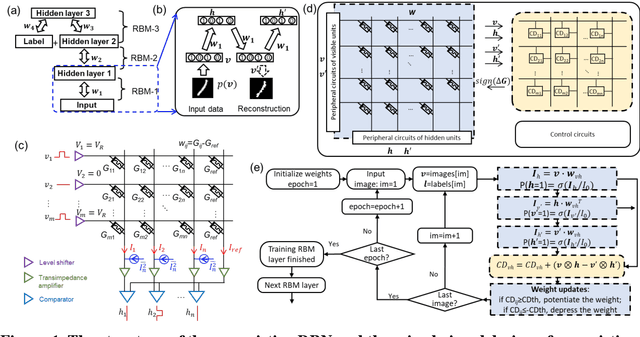
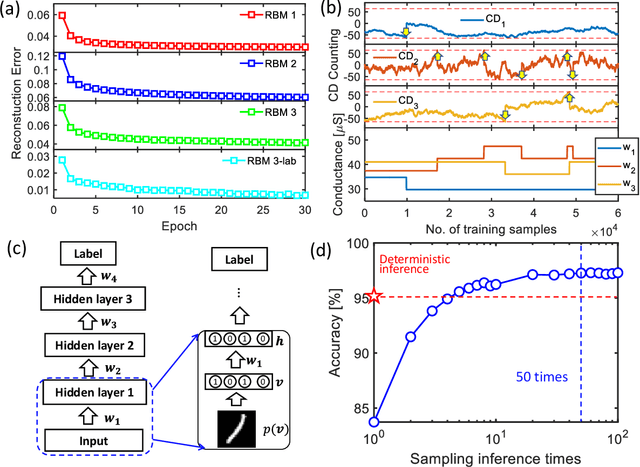
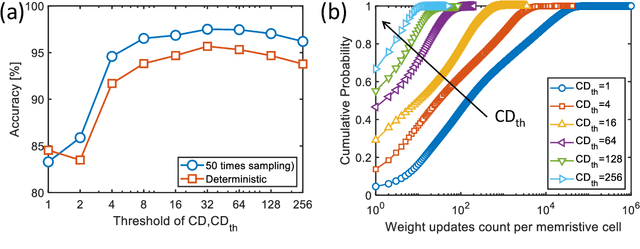
The tunability of conductance states of various emerging non-volatile memristive devices emulates the plasticity of biological synapses, making it promising in the hardware realization of large-scale neuromorphic systems. The inference of the neural network can be greatly accelerated by the vector-matrix multiplication (VMM) performed within a crossbar array of memristive devices in one step. Nevertheless, the implementation of the VMM needs complex peripheral circuits and the complexity further increases since non-idealities of memristive devices prevent precise conductance tuning (especially for the online training) and largely degrade the performance of the deep neural networks (DNNs). Here, we present an efficient online training method of the memristive deep belief net (DBN). The proposed memristive DBN uses stochastically binarized activations, reducing the complexity of peripheral circuits, and uses the contrastive divergence (CD) based gradient descent learning algorithm. The analog VMM and digital CD are performed separately in a mixed-signal hardware arrangement, making the memristive DBN high immune to non-idealities of synaptic devices. The number of write operations on memristive devices is reduced by two orders of magnitude. The recognition accuracy of 95%~97% can be achieved for the MNIST dataset using pulsed synaptic behaviors of various memristive synaptic devices.
Why & When Deep Learning Works: Looking Inside Deep Learnings
May 10, 2017The Intel Collaborative Research Institute for Computational Intelligence (ICRI-CI) has been heavily supporting Machine Learning and Deep Learning research from its foundation in 2012. We have asked six leading ICRI-CI Deep Learning researchers to address the challenge of "Why & When Deep Learning works", with the goal of looking inside Deep Learning, providing insights on how deep networks function, and uncovering key observations on their expressiveness, limitations, and potential. The output of this challenge resulted in five papers that address different facets of deep learning. These different facets include a high-level understating of why and when deep networks work (and do not work), the impact of geometry on the expressiveness of deep networks, and making deep networks interpretable.